 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFSAttn: Dynamic Fine-grained Sparse Attention for Efficient Video Generation
May 22, 2026Diffusion transformers have achieved remarkable success in high-quality video generation, yet their reliance on spatiotemporal 3D full attention incurs prohibitive computational cost due to the quadratic complexity of attention. Block sparse attention is a common approach to mitigate this by focusing computation on important regions. However, attention maps in DiTs exhibit inherently dynamic and fine-grained sparsity, which causes existing block sparse attention methods to degrade significantly in quality, especially at high sparsity ratios. In this paper, we revisit block sparse attention and derive a theoretical lower bound on attention recall to characterize the key factors governing its effectiveness. Guided by these insights, we propose DFSAttn, a training-free sparse attention framework that enables dynamic, fine-grained sparsification efficiently. DFSAttn incorporates three core designs: Hilbert curve-based token reordering to achieve fine-grained sparsity while preserving efficient GPU execution, hierarchical block scoring for accurate block importance estimation, and sparse mask caching with adaptive ratios to balance accuracy and efficiency. Experimental results demonstrate that DFSAttn consistently outperforms prior methods under high sparsity, achieving up to 2.1$\times$ end-to-end speedup while maintaining high generation quality. Our code is open-sourced and available at https://github.com/jessica-hujie/DFSAttn.
RoPeSLR: 3D RoPE-driven Sparse-LowRank Attention for Efficient Diffusion Transformers
May 20, 2026Diffusion Transformers (DiTs) have revolutionized high-fidelity video generation, yet their $\mathcal{O}(L^2)$ attention complexity poses a formidable bottleneck for long-sequence synthesis. While recent sparse-linear attention hybrids aim to mitigate this, their performance severely degrades at extreme sparsity due to the "RoPE Dilemma": standard linear attention fails to preserve the orthogonal relative-position structure of 3D Rotary Position Embeddings (RoPE), neutralizing vital distance awareness. To address this, we propose \textbf{RoPeSLR}, a 3D RoPE-guided Sparse-LowRank attention framework. We establish that under empirically validated assumptions, the DiT attention manifold admits a decoupling into a high-frequency semantic spike set (bounded by $\mathcal{O}(L^{3/2})$ sparsity) and an extreme low-rank ($\mathcal{O}(d_h \log L)$) background continuum. Guided by this structural prior, RoPeSLR eschews standard linear attention for a head-wise low-rank parameterization equipped with a learnable 3D Absolute Positional Embedding (PE) injection, seamlessly synthesizing long-range relative distance decay. By guaranteeing sub-quadratic sparsity and sub-linear rank growth, RoPeSLR is exceptionally suited for scaling to ultra-long video inference. Extensive evaluations validate this scalable superiority: at 90\% sparsity, RoPeSLR achieves up to $10\times$ fewer FLOPs on Wan2.1-1.3B and delivers a $2.26\times$ end-to-end inference speedup on the ultra-long 100K+ token sequences of HunyuanVideo-13B, all while maintaining near-lossless generation fidelity (less than 1.3\% average VBench degradation).
FedSLoP: Memory-Efficient Federated Learning with Low-Rank Gradient Projection
Apr 27, 2026Federated learning enables a population of clients to collaboratively train machine learning models without exchanging their raw data, but standard algorithms such as FedAvg suffer from slow convergence and high communication and memory costs in heterogeneous, resource-constrained environments. We introduce FedSLoP, a federated optimization algorithm that combines stochastic low-rank subspace projections of gradients, thereby reducing the dimension of communicated and stored updates while preserving optimization progress. On the theoretical side, we develop a detailed nonconvex convergence analysis under standard smoothness and bounded-variance assumptions, showing that FedSLoP is guaranteed to converge to a first-order stationary point at a rate of $O(1/\sqrt{NT})$. On the empirical side, we conduct extensive experiments on federated MNIST classification with heterogeneous data partitions, showing that FedSLoP substantially reduces communication volume and client-side memory while achieving competitive or better accuracy compared with FedAvg and representative sparse or low-rank baselines. Together, our results demonstrate that random subspace momentum methods such as FedSLoP provide a principled and effective approach to communication- and memory-efficient federated learning. Codes are available at: https://github.com/pkumelon/FedSLoP.git.
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Feb 05, 2026Flow and diffusion models produce high-quality samples, but adapting them to user preferences or constraints post-training remains costly and brittle, a challenge commonly called reward alignment. We argue that efficient reward alignment should be a property of the generative model itself, not an afterthought, and redesign the model for adaptability. We propose "Diamond Maps", stochastic flow map models that enable efficient and accurate alignment to arbitrary rewards at inference time. Diamond Maps amortize many simulation steps into a single-step sampler, like flow maps, while preserving the stochasticity required for optimal reward alignment. This design makes search, sequential Monte Carlo, and guidance scalable by enabling efficient and consistent estimation of the value function. Our experiments show that Diamond Maps can be learned efficiently via distillation from GLASS Flows, achieve stronger reward alignment performance, and scale better than existing methods. Our results point toward a practical route to generative models that can be rapidly adapted to arbitrary preferences and constraints at inference time.
Mixture-of-Channels: Exploiting Sparse FFNs for Efficient LLMs Pre-Training and Inference
Nov 12, 2025Large language models (LLMs) have demonstrated remarkable success across diverse artificial intelligence tasks, driven by scaling laws that correlate model size and training data with performance improvements. However, this scaling paradigm incurs substantial memory overhead, creating significant challenges for both training and inference. While existing research has primarily addressed parameter and optimizer state memory reduction, activation memory-particularly from feed-forward networks (FFNs)-has become the critical bottleneck, especially when FlashAttention is implemented. In this work, we conduct a detailed memory profiling of LLMs and identify FFN activations as the predominant source to activation memory overhead. Motivated by this, we introduce Mixture-of-Channels (MoC), a novel FFN architecture that selectively activates only the Top-K most relevant channels per token determined by SwiGLU's native gating mechanism. MoC substantially reduces activation memory during pre-training and improves inference efficiency by reducing memory access through partial weight loading into GPU SRAM. Extensive experiments validate that MoC delivers significant memory savings and throughput gains while maintaining competitive model performance.
An All-Reduce Compatible Top-K Compressor for Communication-Efficient Distributed Learning
Oct 30, 2025Communication remains a central bottleneck in large-scale distributed machine learning, and gradient sparsification has emerged as a promising strategy to alleviate this challenge. However, existing gradient compressors face notable limitations: Rand-$K$\ discards structural information and performs poorly in practice, while Top-$K$\ preserves informative entries but loses the contraction property and requires costly All-Gather operations. In this paper, we propose ARC-Top-$K$, an {All-Reduce}-Compatible Top-$K$ compressor that aligns sparsity patterns across nodes using a lightweight sketch of the gradient, enabling index-free All-Reduce while preserving globally significant information. ARC-Top-$K$\ is provably contractive and, when combined with momentum error feedback (EF21M), achieves linear speedup and sharper convergence rates than the original EF21M under standard assumptions. Empirically, ARC-Top-$K$\ matches the accuracy of Top-$K$\ while reducing wall-clock training time by up to 60.7\%, offering an efficient and scalable solution that combines the robustness of Rand-$K$\ with the strong performance of Top-$K$.
Efficient Long-Context LLM Inference via KV Cache Clustering
Jun 13, 2025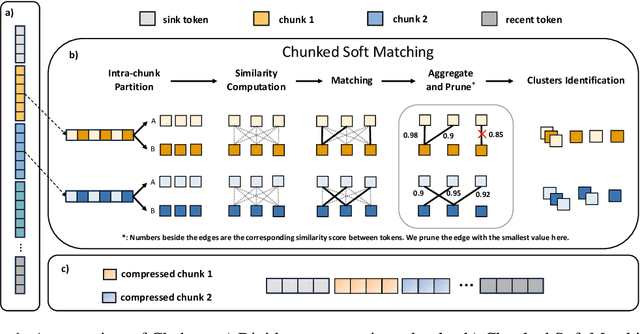
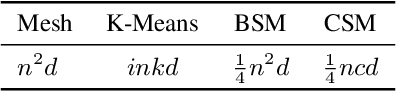
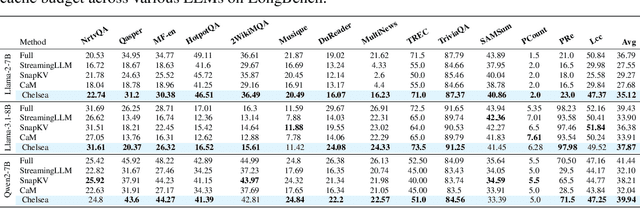
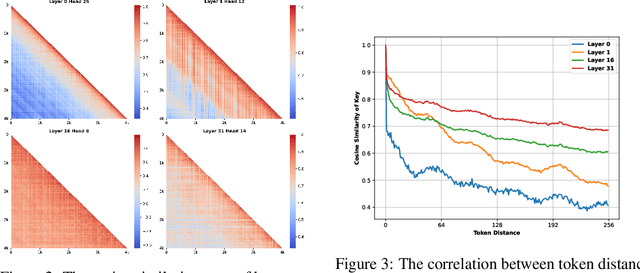
Large language models (LLMs) with extended context windows have become increasingly prevalent for tackling complex tasks. However, the substantial Key-Value (KV) cache required for long-context LLMs poses significant deployment challenges. Existing approaches either discard potentially critical information needed for future generations or offer limited efficiency gains due to high computational overhead. In this paper, we introduce Chelsea, a simple yet effective framework for online KV cache clustering. Our approach is based on the observation that key states exhibit high similarity along the sequence dimension. To enable efficient clustering, we divide the sequence into chunks and propose Chunked Soft Matching, which employs an alternating partition strategy within each chunk and identifies clusters based on similarity. Chelsea then merges the KV cache within each cluster into a single centroid. Additionally, we provide a theoretical analysis of the computational complexity and the optimality of the intra-chunk partitioning strategy. Extensive experiments across various models and long-context benchmarks demonstrate that Chelsea achieves up to 80% reduction in KV cache memory usage while maintaining comparable model performance. Moreover, with minimal computational overhead, Chelsea accelerates the decoding stage of inference by up to 3.19$\times$ and reduces end-to-end latency by up to 2.72$\times$.
Accelerating Diffusion Models in Offline RL via Reward-Aware Consistency Trajectory Distillation
Jun 09, 2025Although diffusion models have achieved strong results in decision-making tasks, their slow inference speed remains a key limitation. While the consistency model offers a potential solution, its applications to decision-making often struggle with suboptimal demonstrations or rely on complex concurrent training of multiple networks. In this work, we propose a novel approach to consistency distillation for offline reinforcement learning that directly incorporates reward optimization into the distillation process. Our method enables single-step generation while maintaining higher performance and simpler training. Empirical evaluations on the Gym MuJoCo benchmarks and long horizon planning demonstrate that our approach can achieve an 8.7% improvement over previous state-of-the-art while offering up to 142x speedup over diffusion counterparts in inference time.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
CE-LoRA: Computation-Efficient LoRA Fine-Tuning for Language Models
Feb 03, 2025



Large Language Models (LLMs) demonstrate exceptional performance across various tasks but demand substantial computational resources even for fine-tuning computation. Although Low-Rank Adaptation (LoRA) significantly alleviates memory consumption during fine-tuning, its impact on computational cost reduction is limited. This paper identifies the computation of activation gradients as the primary bottleneck in LoRA's backward propagation and introduces the Computation-Efficient LoRA (CE-LoRA) algorithm, which enhances computational efficiency while preserving memory efficiency. CE-LoRA leverages two key techniques: Approximated Matrix Multiplication, which replaces dense multiplications of large and complete matrices with sparse multiplications involving only critical rows and columns, and the Double-LoRA technique, which reduces error propagation in activation gradients. Theoretically, CE-LoRA converges at the same rate as LoRA, $ \mathcal{O}(1/\sqrt{T}) $, where $T$ is the number of iteartions. Empirical evaluations confirm that CE-LoRA significantly reduces computational costs compared to LoRA without notable performance degradation.