 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCluster: Adaptive Query-Key Clustering for Sparse Attention in Video Generation
Apr 20, 2026Video diffusion transformers (DiTs) suffer from prohibitive inference latency due to quadratic attention complexity. Existing sparse attention methods either overlook semantic similarity or fail to adapt to heterogeneous token distributions across layers, leading to model performance degradation. We propose AdaCluster, a training-free adaptive clustering framework that accelerates the generation of DiTs while preserving accuracy. AdaCluster applies an angle-similarity-preserving clustering method to query vectors for higher compression, and designs a euclidean-similarity-preserving clustering method for keys, covering cluster number assignment, threshold-wise adaptive clustering, and efficient critical cluster selection. Experiments on CogVideoX-2B, HunyuanVideo, and Wan-2.1 on one A40 GPU demonstrate up to 1.67-4.31x speedup with negligible quality degradation.
GenoBERT: A Language Model for Accurate Genotype Imputation
Mar 31, 2026Genotype imputation enables dense variant coverage for genome-wide association and risk-prediction studies, yet conventional reference-panel methods remain limited by ancestry bias and reduced rare-variant accuracy. We present Genotype Bidirectional Encoder Representations from Transformers (GenoBERT), a transformer-based, reference-free framework that tokenizes phased genotypes and uses a self-attention mechanism to capture both short- and long-range linkage disequilibrium (LD) dependencies. Benchmarking on two independent datasets including the Louisiana Osteoporosis Study (LOS) and the 1000 Genomes Project (1KGP) across ancestry groups and multiple genotype missingness levels (5-50%) shows that GenoBERT achieves the highest overall accuracy compared to four baseline methods (Beagle5.4, SCDA, BiU-Net, and STICI). At practical sparsity levels (up to 25% missing), GenoBERT attains high overall imputation accuracy ($r^2 approx 0.98$) across datasets, and maintains robust performance ($r^2 > 0.90$) even at 50% missingness. Experimental results across different ancestries confirm consistent gains across datasets, with resilience to small sample sizes and weak LD. A 128-SNP (single-nucleotide polymorphism) context window (approximately 100 Kb) is validated through LD-decay analyses as sufficient to capture local correlation structures. By eliminating reference-panel dependence while preserving high accuracy, GenoBERT provides a scalable and robust solution for genotype imputation and a foundation for downstream genomic modeling.
IGV-RRT: Prior-Real-Time Observation Fusion for Active Object Search in Changing Environments
Mar 23, 2026Object Goal Navigation (ObjectNav) in temporally changing indoor environments is challenging because object relocation can invalidate historical scene knowledge. To address this issue, we propose a probabilistic planning framework that combines uncertainty-aware scene priors with online target relevance estimates derived from a Vision Language Model (VLM). The framework contains a dual-layer semantic mapping module and a real-time planner. The mapping module includes an Information Gain Map (IGM) built from a 3D scene graph (3DSG) during prior exploration to model object co-occurrence relations and provide global guidance on likely target regions. It also maintains a VLM score map (VLM-SM) that fuses confidence-weighted semantic observations into the map for local validation of the current scene. Based on these two cues, we develop a planner that jointly exploits information gain and semantic evidence for online decision making. The planner biases tree expansion toward semantically salient regions with high prior likelihood and strong online relevance (IGV-RRT), while preserving kinematic feasibility through gradient-based analysis. Simulation and real-world experiments demonstrate that the proposed method effectively mitigates the impact of object rearrangement, achieving higher search efficiency and success rates than representative baselines in complex indoor environments.
CLO: Efficient LLM Inference System with CPU-Light KVCache Offloading via Algorithm-System Co-Design
Nov 18, 2025The growth of million-token LLMs exposes the scalability limits of inference systems, where the KVCache dominates memory usage and data transfer overhead. Recent offloading systems migrate the KVCache to CPU memory and incorporate top-k attention to reduce the volume of data transferred from the CPU, while further applying system-level optimizations such as on-GPU caching and prefetching to lower transfer overhead. However, they overlook the CPU bottleneck in three aspects: (1) substantial overhead of fine-grained dynamic cache management performed on the CPU side, (2) significant transfer overhead from poor PCIe bandwidth utilization caused by heavy gathering operations at the CPU side, and (3) GPU runtime bubbles introduced by coarse-grained CPU-centric synchronization. To address these challenges, we propose CLO, a CPU-light KVCache offloading system via algorithm-system co-design. CLO features: (1) a coarse-grained head-wise approximate on-GPU caching strategy with negligible cache management cost, (2) seamless combination of data prefetching and on-GPU persistent caching for lower transfer overhead, (3) a zero-copy transfer engine to fully exploit PCIe bandwidth, and a GPU-centric synchronization method to eliminate GPU stalls. Evaluation on two widely-used LLMs demonstrates that CLO achieves comparable accuracy to state-of-the-art systems, while substantially minimizing CPU overhead, fully utilizing PCIe bandwidth, thus improving decoding throughput by 9.3%-66.6%. Our results highlight that algorithm-system co-design is essential for memory-constrained LLM inference on modern GPU platforms. We open source CLO at https://github.com/CommediaJW/CLO.
Efficient Long-Context LLM Inference via KV Cache Clustering
Jun 13, 2025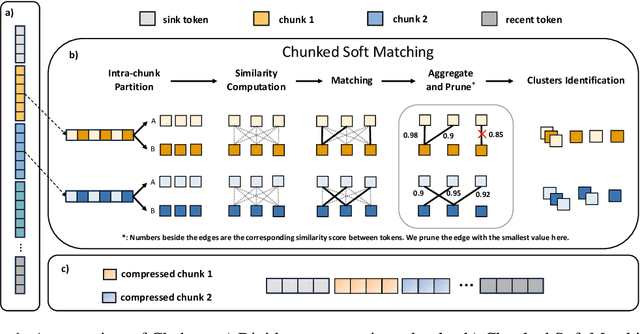
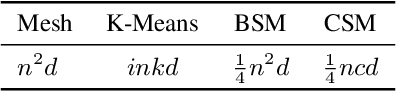
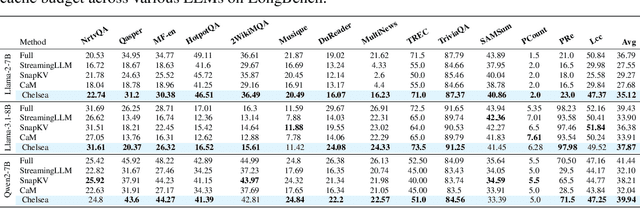
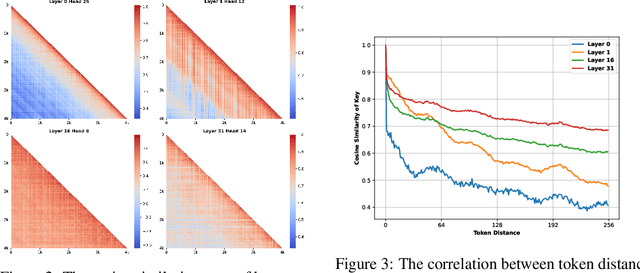
Large language models (LLMs) with extended context windows have become increasingly prevalent for tackling complex tasks. However, the substantial Key-Value (KV) cache required for long-context LLMs poses significant deployment challenges. Existing approaches either discard potentially critical information needed for future generations or offer limited efficiency gains due to high computational overhead. In this paper, we introduce Chelsea, a simple yet effective framework for online KV cache clustering. Our approach is based on the observation that key states exhibit high similarity along the sequence dimension. To enable efficient clustering, we divide the sequence into chunks and propose Chunked Soft Matching, which employs an alternating partition strategy within each chunk and identifies clusters based on similarity. Chelsea then merges the KV cache within each cluster into a single centroid. Additionally, we provide a theoretical analysis of the computational complexity and the optimality of the intra-chunk partitioning strategy. Extensive experiments across various models and long-context benchmarks demonstrate that Chelsea achieves up to 80% reduction in KV cache memory usage while maintaining comparable model performance. Moreover, with minimal computational overhead, Chelsea accelerates the decoding stage of inference by up to 3.19$\times$ and reduces end-to-end latency by up to 2.72$\times$.
Unicorn: A Universal and Collaborative Reinforcement Learning Approach Towards Generalizable Network-Wide Traffic Signal Control
Mar 14, 2025Adaptive traffic signal control (ATSC) is crucial in reducing congestion, maximizing throughput, and improving mobility in rapidly growing urban areas. Recent advancements in parameter-sharing multi-agent reinforcement learning (MARL) have greatly enhanced the scalable and adaptive optimization of complex, dynamic flows in large-scale homogeneous networks. However, the inherent heterogeneity of real-world traffic networks, with their varied intersection topologies and interaction dynamics, poses substantial challenges to achieving scalable and effective ATSC across different traffic scenarios. To address these challenges, we present Unicorn, a universal and collaborative MARL framework designed for efficient and adaptable network-wide ATSC. Specifically, we first propose a unified approach to map the states and actions of intersections with varying topologies into a common structure based on traffic movements. Next, we design a Universal Traffic Representation (UTR) module with a decoder-only network for general feature extraction, enhancing the model's adaptability to diverse traffic scenarios. Additionally, we incorporate an Intersection Specifics Representation (ISR) module, designed to identify key latent vectors that represent the unique intersection's topology and traffic dynamics through variational inference techniques. To further refine these latent representations, we employ a contrastive learning approach in a self-supervised manner, which enables better differentiation of intersection-specific features. Moreover, we integrate the state-action dependencies of neighboring agents into policy optimization, which effectively captures dynamic agent interactions and facilitates efficient regional collaboration. Our results show that Unicorn outperforms other methods across various evaluation metrics, highlighting its potential in complex, dynamic traffic networks.
SARA: Singular-Value Based Adaptive Low-Rank Adaption
Aug 06, 2024With the increasing number of parameters in large pre-trained models, LoRA as a parameter-efficient fine-tuning(PEFT) method is widely used for not adding inference overhead. The LoRA method assumes that weight changes during fine-tuning can be approximated by low-rank matrices. However, the rank values need to be manually verified to match different downstream tasks, and they cannot accommodate the varying importance of different layers in the model. In this work, we first analyze the relationship between the performance of different layers and their ranks using SVD. Based on this, we design the Singular-Value Based Adaptive Low-Rank Adaption(SARA), which adaptively finds the rank during initialization by performing SVD on the pre-trained weights. Additionally, we explore the Mixture-of-SARA(Mo-SARA), which significantly reduces the number of parameters by fine-tuning only multiple parallel sets of singular values controlled by a router. Extensive experiments on various complex tasks demonstrate the simplicity and parameter efficiency of our methods. They can effectively and adaptively find the most suitable rank for each layer of each model.
Understand Data Preprocessing for Effective End-to-End Training of Deep Neural Networks
Apr 18, 2023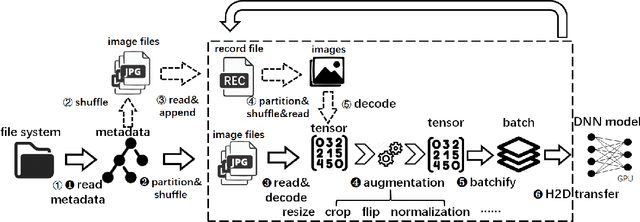
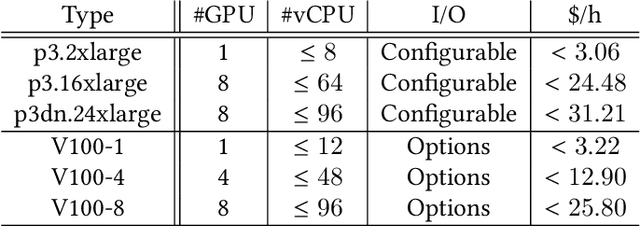
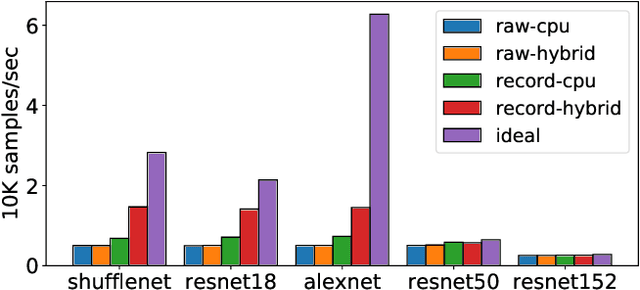

In this paper, we primarily focus on understanding the data preprocessing pipeline for DNN Training in the public cloud. First, we run experiments to test the performance implications of the two major data preprocessing methods using either raw data or record files. The preliminary results show that data preprocessing is a clear bottleneck, even with the most efficient software and hardware configuration enabled by NVIDIA DALI, a high-optimized data preprocessing library. Second, we identify the potential causes, exercise a variety of optimization methods, and present their pros and cons. We hope this work will shed light on the new co-design of ``data storage, loading pipeline'' and ``training framework'' and flexible resource configurations between them so that the resources can be fully exploited and performance can be maximized.
Joint localization and classification of breast tumors on ultrasound images using a novel auxiliary attention-based framework
Oct 11, 2022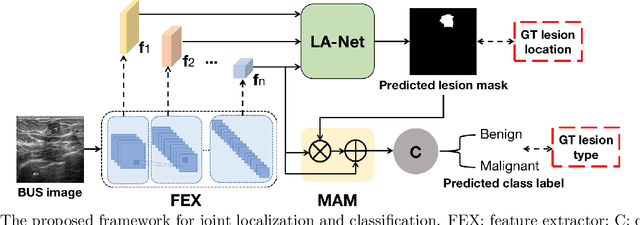
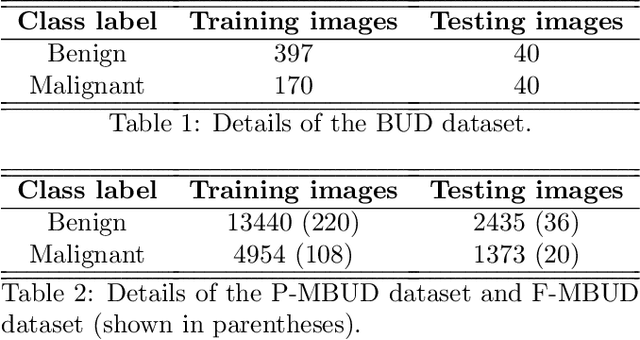
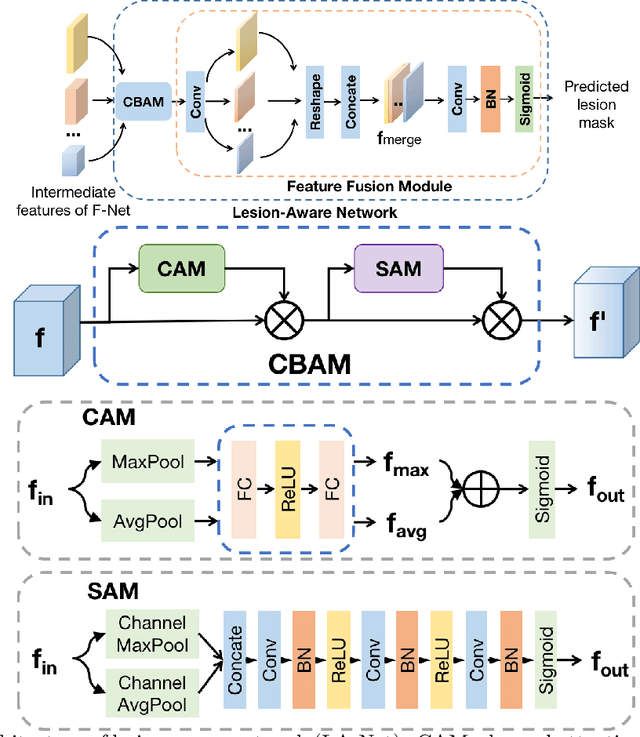
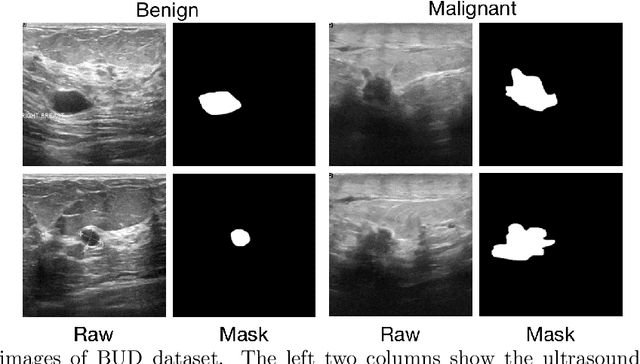
Automatic breast lesion detection and classification is an important task in computer-aided diagnosis, in which breast ultrasound (BUS) imaging is a common and frequently used screening tool. Recently, a number of deep learning-based methods have been proposed for joint localization and classification of breast lesions using BUS images. In these methods, features extracted by a shared network trunk are appended by two independent network branches to achieve classification and localization. Improper information sharing might cause conflicts in feature optimization in the two branches and leads to performance degradation. Also, these methods generally require large amounts of pixel-level annotated data for model training. To overcome these limitations, we proposed a novel joint localization and classification model based on the attention mechanism and disentangled semi-supervised learning strategy. The model used in this study is composed of a classification network and an auxiliary lesion-aware network. By use of the attention mechanism, the auxiliary lesion-aware network can optimize multi-scale intermediate feature maps and extract rich semantic information to improve classification and localization performance. The disentangled semi-supervised learning strategy only requires incomplete training datasets for model training. The proposed modularized framework allows flexible network replacement to be generalized for various applications. Experimental results on two different breast ultrasound image datasets demonstrate the effectiveness of the proposed method. The impacts of various network factors on model performance are also investigated to gain deep insights into the designed framework.
One-Shot Medical Landmark Localization by Edge-Guided Transform and Noisy Landmark Refinement
Jul 31, 2022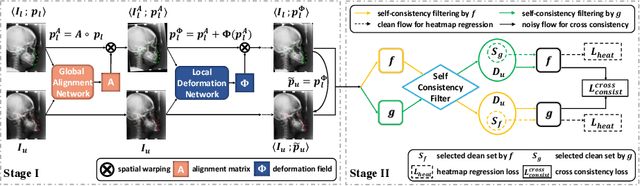
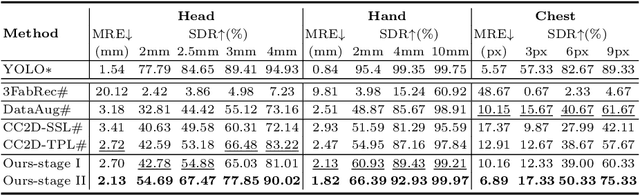
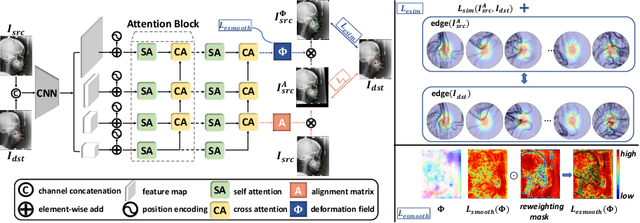
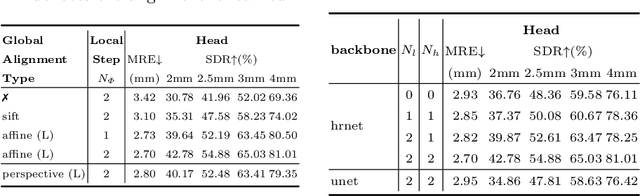
As an important upstream task for many medical applications, supervised landmark localization still requires non-negligible annotation costs to achieve desirable performance. Besides, due to cumbersome collection procedures, the limited size of medical landmark datasets impacts the effectiveness of large-scale self-supervised pre-training methods. To address these challenges, we propose a two-stage framework for one-shot medical landmark localization, which first infers landmarks by unsupervised registration from the labeled exemplar to unlabeled targets, and then utilizes these noisy pseudo labels to train robust detectors. To handle the significant structure variations, we learn an end-to-end cascade of global alignment and local deformations, under the guidance of novel loss functions which incorporate edge information. In stage II, we explore self-consistency for selecting reliable pseudo labels and cross-consistency for semi-supervised learning. Our method achieves state-of-the-art performances on public datasets of different body parts, which demonstrates its general applicability.