 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiFeat: Supercharge GNN Training via Graph Feature Quantization
Paper and Code
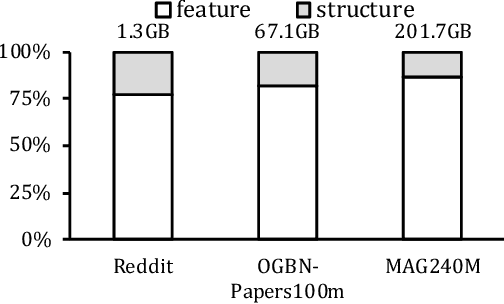
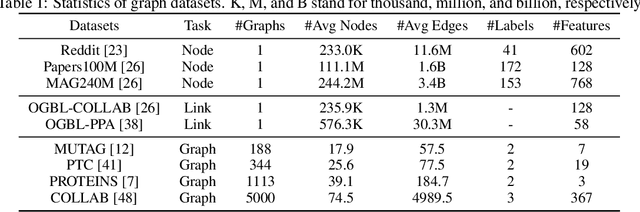
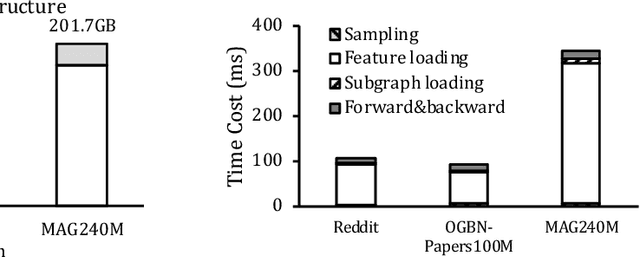
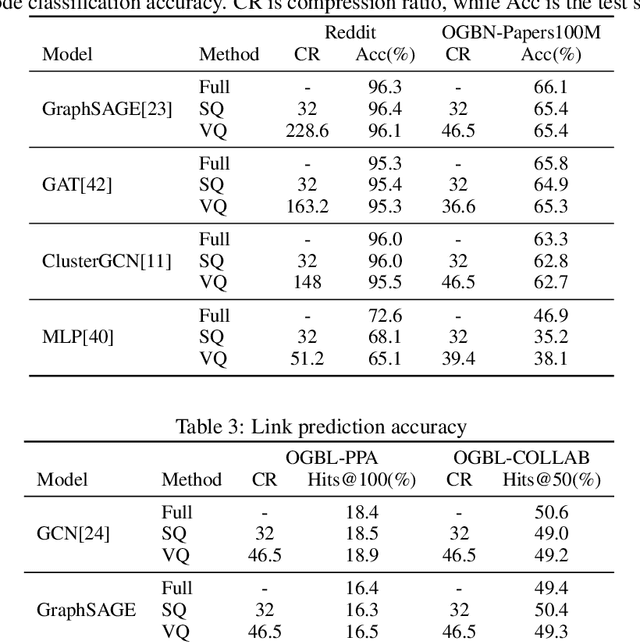
Graph Neural Networks (GNNs) is a promising approach for applications with nonEuclidean data. However, training GNNs on large scale graphs with hundreds of millions nodes is both resource and time consuming. Different from DNNs, GNNs usually have larger memory footprints, and thus the GPU memory capacity and PCIe bandwidth are the main resource bottlenecks in GNN training. To address this problem, we present BiFeat: a graph feature quantization methodology to accelerate GNN training by significantly reducing the memory footprint and PCIe bandwidth requirement so that GNNs can take full advantage of GPU computing capabilities. Our key insight is that unlike DNN, GNN is less prone to the information loss of input features caused by quantization. We identify the main accuracy impact factors in graph feature quantization and theoretically prove that BiFeat training converges to a network where the loss is within $\epsilon$ of the optimal loss of uncompressed network. We perform extensive evaluation of BiFeat using several popular GNN models and datasets, including GraphSAGE on MAG240M, the largest public graph dataset. The results demonstrate that BiFeat achieves a compression ratio of more than 30 and improves GNN training speed by 200%-320% with marginal accuracy loss. In particular, BiFeat achieves a record by training GraphSAGE on MAG240M within one hour using only four GPUs.