 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Hint for Reinforcement Learning
Apr 01, 2026Group Relative Policy Optimization (GRPO) is widely used for reinforcement learning with verifiable rewards, but it often suffers from advantage collapse: when all rollouts in a group receive the same reward, the group yields zero relative advantage and thus no learning signal. For example, if a question is too hard for the reasoner, all sampled rollouts can be incorrect and receive zero reward. Recent work addresses this issue by adding hints or auxiliary scaffolds to such hard questions so that the reasoner produces mixed outcomes and recovers a non-zero update. However, existing hints are usually fixed rather than adapted to the current reasoner, and a hint that creates learning signal under the hinted input does not necessarily improve the no-hint policy used at test time. To this end, we propose Hint Learning for Reinforcement Learning (HiLL), a framework that jointly trains a hinter policy and a reasoner policy during RL. For each hard question, the hinter generates hints online conditioned on the current reasoner's incorrect rollout, allowing hint generation to adapt to the reasoner's evolving errors. We further introduce hint reliance, which measures how strongly correct hinted trajectories depend on the hint. We derive a transferability result showing that lower hint reliance implies stronger transfer from hinted success to no-hint success, and we use this result to define a transfer-weighted reward for training the hinter. Therefore, HiLL favors hints that not only recover informative GRPO groups, but also produce signals that are more likely to improve the original no-hint policy. Experiments across multiple benchmarks show that HiLL consistently outperforms GRPO and prior hint-based baselines, demonstrating the value of adaptive and transfer-aware hint learning for RL. The code is available at https://github.com/Andree-9/HiLL.
Learning to Self-Evolve
Mar 19, 2026We introduce Learning to Self-Evolve (LSE), a reinforcement learning framework that trains large language models (LLMs) to improve their own contexts at test time. We situate LSE in the setting of test-time self-evolution, where a model iteratively refines its context from feedback on seen problems to perform better on new ones. Existing approaches rely entirely on the inherent reasoning ability of the model and never explicitly train it for this task. LSE reduces the multi-step evolution problem to a single-step RL objective, where each context edit is rewarded by the improvement in downstream performance. We pair this objective with a tree-guided evolution loop. On Text-to-SQL generation (BIRD) and general question answering (MMLU-Redux), a 4B-parameter model trained with LSE outperforms self-evolving policies powered by GPT-5 and Claude Sonnet 4.5, as well as prompt optimization methods including GEPA and TextGrad, and transfers to guide other models without additional training. Our results highlight the effectiveness of treating self-evolution as a learnable skill.
DARE-bench: Evaluating Modeling and Instruction Fidelity of LLMs in Data Science
Feb 27, 2026The fast-growing demands in using Large Language Models (LLMs) to tackle complex multi-step data science tasks create an emergent need for accurate benchmarking. There are two major gaps in existing benchmarks: (i) the lack of standardized, process-aware evaluation that captures instruction adherence and process fidelity, and (ii) the scarcity of accurately labeled training data. To bridge these gaps, we introduce DARE-bench, a benchmark designed for machine learning modeling and data science instruction following. Unlike many existing benchmarks that rely on human- or model-based judges, all tasks in DARE-bench have verifiable ground truth, ensuring objective and reproducible evaluation. To cover a broad range of tasks and support agentic tools, DARE-bench consists of 6,300 Kaggle-derived tasks and provides both large-scale training data and evaluation sets. Extensive evaluations show that even highly capable models such as gpt-o4-mini struggle to achieve good performance, especially in machine learning modeling tasks. Using DARE-bench training tasks for fine-tuning can substantially improve model performance. For example, supervised fine-tuning boosts Qwen3-32B's accuracy by 1.83x and reinforcement learning boosts Qwen3-4B's accuracy by more than 8x. These significant improvements verify the importance of DARE-bench both as an accurate evaluation benchmark and critical training data.
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Feb 11, 2026Recent advances in large language model (LLM) have empowered autonomous agents to perform complex tasks that require multi-turn interactions with tools and environments. However, scaling such agent training is limited by the lack of diverse and reliable environments. In this paper, we propose Agent World Model (AWM), a fully synthetic environment generation pipeline. Using this pipeline, we scale to 1,000 environments covering everyday scenarios, in which agents can interact with rich toolsets (35 tools per environment on average) and obtain high-quality observations. Notably, these environments are code-driven and backed by databases, providing more reliable and consistent state transitions than environments simulated by LLMs. Moreover, they enable more efficient agent interaction compared with collecting trajectories from realistic environments. To demonstrate the effectiveness of this resource, we perform large-scale reinforcement learning for multi-turn tool-use agents. Thanks to the fully executable environments and accessible database states, we can also design reliable reward functions. Experiments on three benchmarks show that training exclusively in synthetic environments, rather than benchmark-specific ones, yields strong out-of-distribution generalization. The code is available at https://github.com/Snowflake-Labs/agent-world-model.
ExCoT: Optimizing Reasoning for Text-to-SQL with Execution Feedback
Mar 25, 2025Text-to-SQL demands precise reasoning to convert natural language questions into structured queries. While large language models (LLMs) excel in many reasoning tasks, their ability to leverage Chain-of-Thought (CoT) reasoning for text-to-SQL remains underexplored. We identify critical limitations: zero-shot CoT offers minimal gains, and Direct Preference Optimization (DPO) applied without CoT yields marginal improvements. We propose ExCoT, a novel framework that iteratively optimizes open-source LLMs by combining CoT reasoning with off-policy and on-policy DPO, relying solely on execution accuracy as feedback. This approach eliminates the need for reward models or human-annotated preferences. Our experimental results demonstrate significant performance gains: ExCoT improves execution accuracy on BIRD dev set from 57.37% to 68.51% and on Spider test set from 78.81% to 86.59% for LLaMA-3 70B, with Qwen-2.5-Coder demonstrating similar improvements. Our best model achieves state-of-the-art performance in the single-model setting on both BIRD and Spider datasets, notably achieving 68.53% on the BIRD test set.
CORD: Balancing COnsistency and Rank Distillation for Robust Retrieval-Augmented Generation
Dec 19, 2024



With the adoption of retrieval-augmented generation (RAG), large language models (LLMs) are expected to ground their generation to the retrieved contexts. Yet, this is hindered by position bias of LLMs, failing to evenly attend to all contexts. Previous work has addressed this by synthesizing contexts with perturbed positions of gold segment, creating a position-diversified train set. We extend this intuition to propose consistency regularization with augmentation and distillation. First, we augment each training instance with its position perturbation to encourage consistent predictions, regardless of ordering. We also distill behaviors of this pair, although it can be counterproductive in certain RAG scenarios where the given order from the retriever is crucial for generation quality. We thus propose CORD, balancing COnsistency and Rank Distillation. CORD adaptively samples noise-controlled perturbations from an interpolation space, ensuring both consistency and respect for the rank prior. Empirical results show this balance enables CORD to outperform consistently in diverse RAG benchmarks.
Inference Scaling for Bridging Retrieval and Augmented Generation
Dec 14, 2024Retrieval-augmented generation (RAG) has emerged as a popular approach to steering the output of a large language model (LLM) by incorporating retrieved contexts as inputs. However, existing work observed the generator bias, such that improving the retrieval results may negatively affect the outcome. In this work, we show such bias can be mitigated, from inference scaling, aggregating inference calls from the permuted order of retrieved contexts. The proposed Mixture-of-Intervention (MOI) explicitly models the debiased utility of each passage with multiple forward passes to construct a new ranking. We also show that MOI can leverage the retriever's prior knowledge to reduce the computational cost by minimizing the number of permutations considered and lowering the cost per LLM call. We showcase the effectiveness of MOI on diverse RAG tasks, improving ROUGE-L on MS MARCO and EM on HotpotQA benchmarks by ~7 points.
SwiftKV: Fast Prefill-Optimized Inference with Knowledge-Preserving Model Transformation
Oct 04, 2024LLM inference for popular enterprise use cases, such as summarization, RAG, and code-generation, typically observes orders of magnitude longer prompt lengths than generation lengths. This characteristic leads to high cost of prefill and increased response latency. In this paper, we present SwiftKV, a novel model transformation and distillation procedure specifically designed to reduce the time and cost of processing prompt tokens while preserving high quality of generated tokens. SwiftKV combines three key mechanisms: i) SingleInputKV, which prefills later layers' KV cache using a much earlier layer's output, allowing prompt tokens to skip much of the model computation, ii) AcrossKV, which merges the KV caches of neighboring layers to reduce the memory footprint and support larger batch size for higher throughput, and iii) a knowledge-preserving distillation procedure that can adapt existing LLMs for SwiftKV with minimal accuracy impact and low compute and data requirement. For Llama-3.1-8B and 70B, SwiftKV reduces the compute requirement of prefill by 50% and the memory requirement of the KV cache by 62.5% while incurring minimum quality degradation across a wide range of tasks. In the end-to-end inference serving using an optimized vLLM implementation, SwiftKV realizes up to 2x higher aggregate throughput and 60% lower time per output token. It can achieve a staggering 560 TFlops/GPU of normalized inference throughput, which translates to 16K tokens/s for Llama-3.1-70B in 16-bit precision on 4x H100 GPUs.
STUN: Structured-Then-Unstructured Pruning for Scalable MoE Pruning
Sep 10, 2024



Mixture-of-experts (MoEs) have been adopted for reducing inference costs by sparsely activating experts in Large language models (LLMs). Despite this reduction, the massive number of experts in MoEs still makes them expensive to serve. In this paper, we study how to address this, by pruning MoEs. Among pruning methodologies, unstructured pruning has been known to achieve the highest performance for a given pruning ratio, compared to structured pruning, since the latter imposes constraints on the sparsification structure. This is intuitive, as the solution space of unstructured pruning subsumes that of structured pruning. However, our counterintuitive finding reveals that expert pruning, a form of structured pruning, can actually precede unstructured pruning to outperform unstructured-only pruning. As existing expert pruning, requiring $O(\frac{k^n}{\sqrt{n}})$ forward passes for $n$ experts, cannot scale for recent MoEs, we propose a scalable alternative with $O(1)$ complexity, yet outperforming the more expensive methods. The key idea is leveraging a latent structure between experts, based on behavior similarity, such that the greedy decision of whether to prune closely captures the joint pruning effect. Ours is highly effective -- for Snowflake Arctic, a 480B-sized MoE with 128 experts, our method needs only one H100 and two hours to achieve nearly no loss in performance with 40% sparsity, even in generative tasks such as GSM8K, where state-of-the-art unstructured pruning fails to. The code will be made publicly available.
AI and Memory Wall
Mar 21, 2024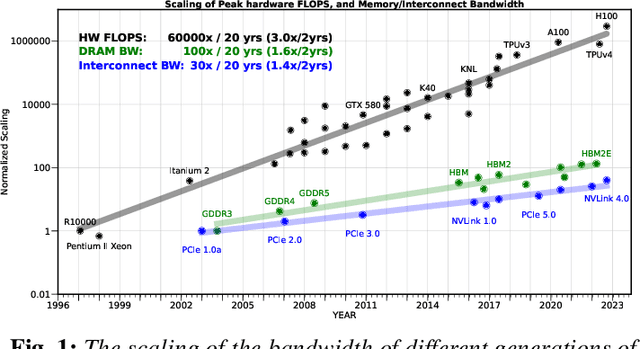
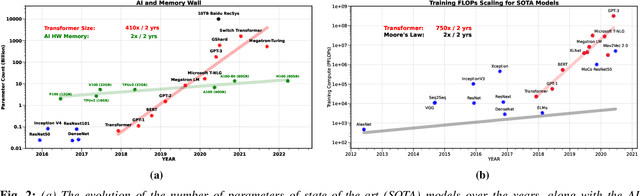
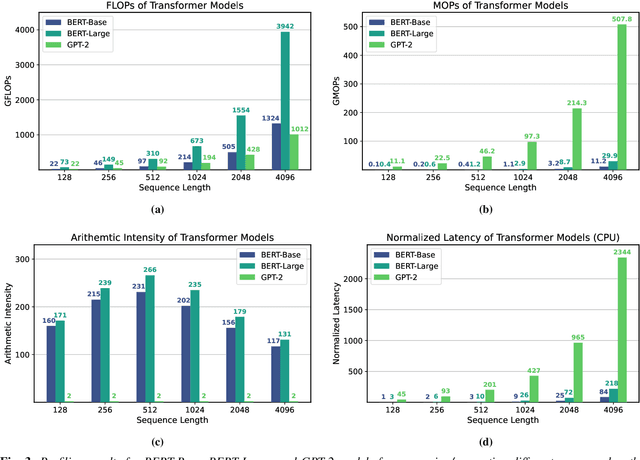
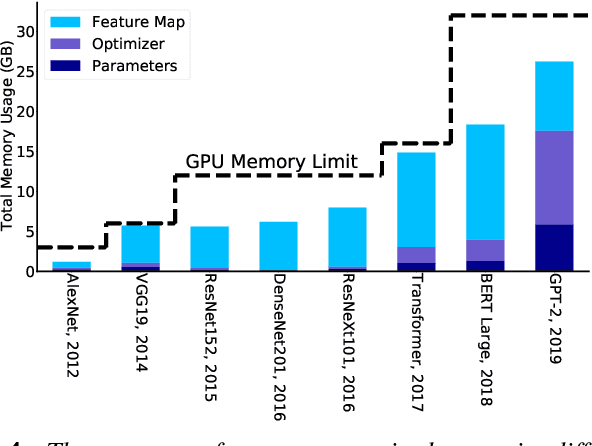
The availability of unprecedented unsupervised training data, along with neural scaling laws, has resulted in an unprecedented surge in model size and compute requirements for serving/training LLMs. However, the main performance bottleneck is increasingly shifting to memory bandwidth. Over the past 20 years, peak server hardware FLOPS has been scaling at 3.0x/2yrs, outpacing the growth of DRAM and interconnect bandwidth, which have only scaled at 1.6 and 1.4 times every 2 years, respectively. This disparity has made memory, rather than compute, the primary bottleneck in AI applications, particularly in serving. Here, we analyze encoder and decoder Transformer models and show how memory bandwidth can become the dominant bottleneck for decoder models. We argue for a redesign in model architecture, training, and deployment strategies to overcome this memory limitation.