 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Semantic Layer from Execution for Text-to-SQL
Jun 04, 2026Real-world text-to-SQL is often under-specified until user phrases are grounded in how the database stores values. Prior work attempts to address this by requiring a semantic layer to specify groundings in advance, but such specifications are often incomplete, especially in expert domains where domain-specific conventions are under-documented. As this leaves multiple grounding hypotheses open for the same SQL part, we introduce GATE (Grouding After Test from Execution), which bootstraps missing groundings from execution feedback. GATE keeps grounding hypotheses open while executing the already grounded parts to obtain observations. Then, only the hypothesis supported by that observation is grounded and stored as a memory entry, recording what was tested and how the open part should be written in SQL. These entries accumulate into execution-grounded memory, allowing later steps to reuse supported groundings. Across real-world and controlled benchmarks, GATE consistently improves over strong baselines, demonstrating that execution can serve not only as validation but also as a bootstrapping mechanism for reusable memory in text-to-SQL.
RoToR: Towards More Reliable Responses for Order-Invariant Inputs
Feb 10, 2025Mitigating positional bias of language models (LMs) for listwise inputs is a well-known and important problem (e.g., lost-in-the-middle). While zero-shot order-invariant LMs have been proposed to solve this issue, their success on practical listwise problems has been limited. In this work, as a first contribution, we identify and overcome two limitations to make zero-shot invariant LMs more practical: (1) training and inference distribution mismatch arising from modifying positional ID assignments to enforce invariance, and (2) failure to adapt to a mixture of order-invariant and sensitive inputs in practical listwise problems. To overcome, we propose (1) RoToR, a zero-shot invariant LM for genuinely order-invariant inputs with minimal modifications of positional IDs, and (2) Selective Routing, an adaptive framework that handles both order-invariant and order-sensitive inputs in listwise tasks. On the Lost in the middle (LitM), Knowledge Graph Question Answering (KGQA), and MMLU benchmarks, we show that RoToR with Selective Routing can effectively handle practical listwise input tasks in a zero-shot manner.
CORD: Balancing COnsistency and Rank Distillation for Robust Retrieval-Augmented Generation
Dec 19, 2024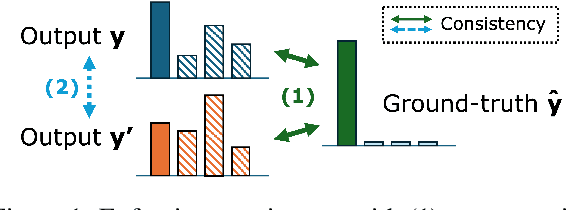



With the adoption of retrieval-augmented generation (RAG), large language models (LLMs) are expected to ground their generation to the retrieved contexts. Yet, this is hindered by position bias of LLMs, failing to evenly attend to all contexts. Previous work has addressed this by synthesizing contexts with perturbed positions of gold segment, creating a position-diversified train set. We extend this intuition to propose consistency regularization with augmentation and distillation. First, we augment each training instance with its position perturbation to encourage consistent predictions, regardless of ordering. We also distill behaviors of this pair, although it can be counterproductive in certain RAG scenarios where the given order from the retriever is crucial for generation quality. We thus propose CORD, balancing COnsistency and Rank Distillation. CORD adaptively samples noise-controlled perturbations from an interpolation space, ensuring both consistency and respect for the rank prior. Empirical results show this balance enables CORD to outperform consistently in diverse RAG benchmarks.
PERC: Plan-As-Query Example Retrieval for Underrepresented Code Generation
Dec 17, 2024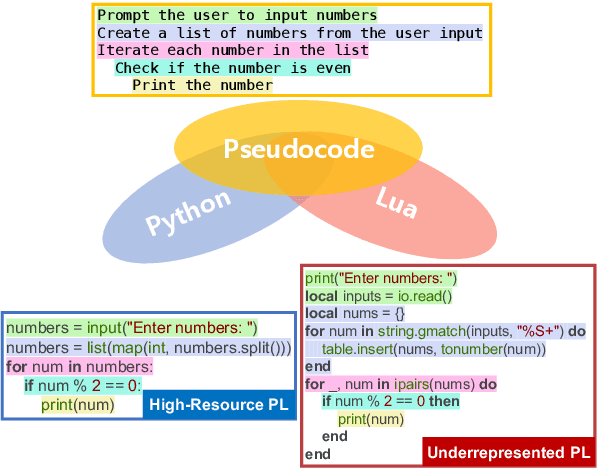
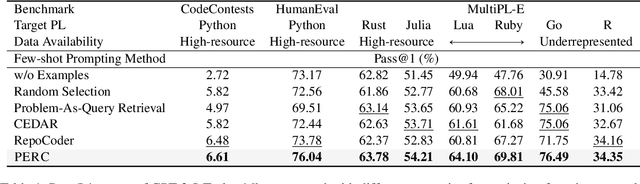
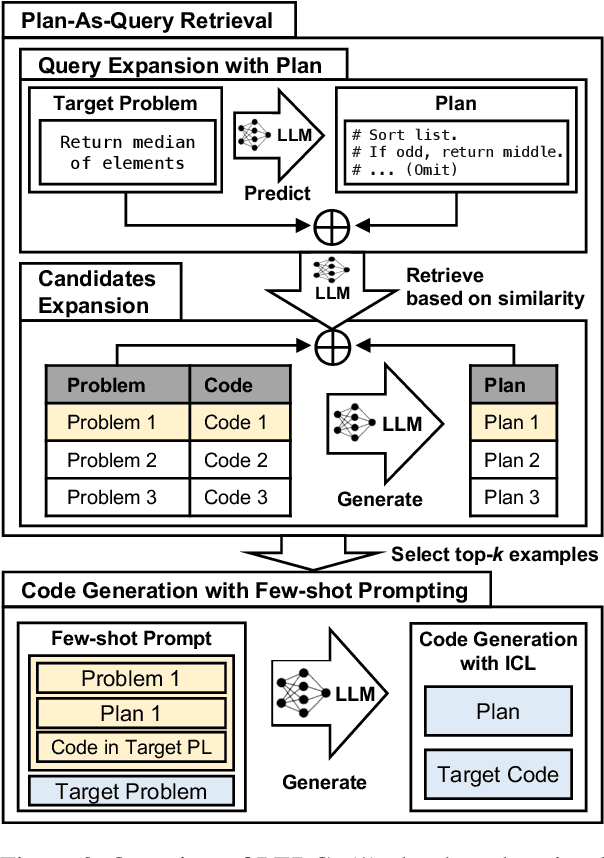
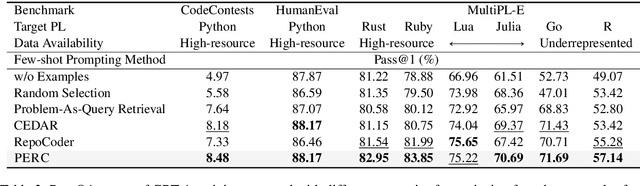
Code generation with large language models has shown significant promise, especially when employing retrieval-augmented generation (RAG) with few-shot examples. However, selecting effective examples that enhance generation quality remains a challenging task, particularly when the target programming language (PL) is underrepresented. In this study, we present two key findings: (1) retrieving examples whose presented algorithmic plans can be referenced for generating the desired behavior significantly improves generation accuracy, and (2) converting code into pseudocode effectively captures such algorithmic plans, enhancing retrieval quality even when the source and the target PLs are different. Based on these findings, we propose Plan-as-query Example Retrieval for few-shot prompting in Code generation (PERC), a novel framework that utilizes algorithmic plans to identify and retrieve effective examples. We validate the effectiveness of PERC through extensive experiments on the CodeContests, HumanEval and MultiPL-E benchmarks: PERC consistently outperforms the state-of-the-art RAG methods in code generation, both when the source and target programming languages match or differ, highlighting its adaptability and robustness in diverse coding environments.
Inference Scaling for Bridging Retrieval and Augmented Generation
Dec 14, 2024Retrieval-augmented generation (RAG) has emerged as a popular approach to steering the output of a large language model (LLM) by incorporating retrieved contexts as inputs. However, existing work observed the generator bias, such that improving the retrieval results may negatively affect the outcome. In this work, we show such bias can be mitigated, from inference scaling, aggregating inference calls from the permuted order of retrieved contexts. The proposed Mixture-of-Intervention (MOI) explicitly models the debiased utility of each passage with multiple forward passes to construct a new ranking. We also show that MOI can leverage the retriever's prior knowledge to reduce the computational cost by minimizing the number of permutations considered and lowering the cost per LLM call. We showcase the effectiveness of MOI on diverse RAG tasks, improving ROUGE-L on MS MARCO and EM on HotpotQA benchmarks by ~7 points.
ArchCode: Incorporating Software Requirements in Code Generation with Large Language Models
Aug 02, 2024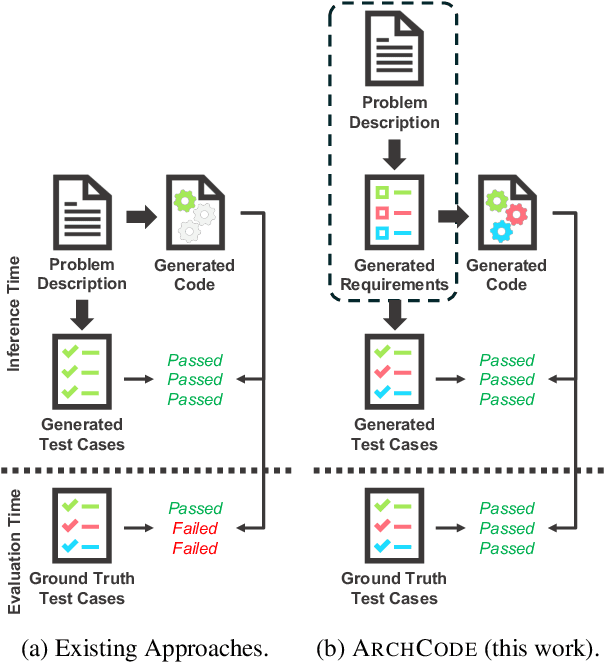



This paper aims to extend the code generation capability of large language models (LLMs) to automatically manage comprehensive software requirements from given textual descriptions. Such requirements include both functional (i.e. achieving expected behavior for inputs) and non-functional (e.g., time/space performance, robustness, maintainability) requirements. However, textual descriptions can either express requirements verbosely or may even omit some of them. We introduce ARCHCODE, a novel framework that leverages in-context learning to organize requirements observed in descriptions and to extrapolate unexpressed requirements from them. ARCHCODE generates requirements from given descriptions, conditioning them to produce code snippets and test cases. Each test case is tailored to one of the requirements, allowing for the ranking of code snippets based on the compliance of their execution results with the requirements. Public benchmarks show that ARCHCODE enhances to satisfy functional requirements, significantly improving Pass@k scores. Furthermore, we introduce HumanEval-NFR, the first evaluation of LLMs' non-functional requirements in code generation, demonstrating ARCHCODE's superiority over baseline methods. The implementation of ARCHCODE and the HumanEval-NFR benchmark are both publicly accessible.