 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoToR: Towards More Reliable Responses for Order-Invariant Inputs
Feb 10, 2025Mitigating positional bias of language models (LMs) for listwise inputs is a well-known and important problem (e.g., lost-in-the-middle). While zero-shot order-invariant LMs have been proposed to solve this issue, their success on practical listwise problems has been limited. In this work, as a first contribution, we identify and overcome two limitations to make zero-shot invariant LMs more practical: (1) training and inference distribution mismatch arising from modifying positional ID assignments to enforce invariance, and (2) failure to adapt to a mixture of order-invariant and sensitive inputs in practical listwise problems. To overcome, we propose (1) RoToR, a zero-shot invariant LM for genuinely order-invariant inputs with minimal modifications of positional IDs, and (2) Selective Routing, an adaptive framework that handles both order-invariant and order-sensitive inputs in listwise tasks. On the Lost in the middle (LitM), Knowledge Graph Question Answering (KGQA), and MMLU benchmarks, we show that RoToR with Selective Routing can effectively handle practical listwise input tasks in a zero-shot manner.
Blank Collapse: Compressing CTC emission for the faster decoding
Oct 31, 2022
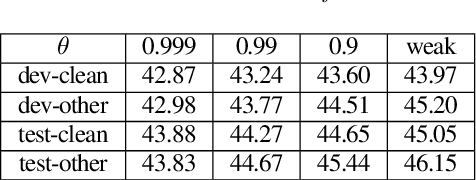

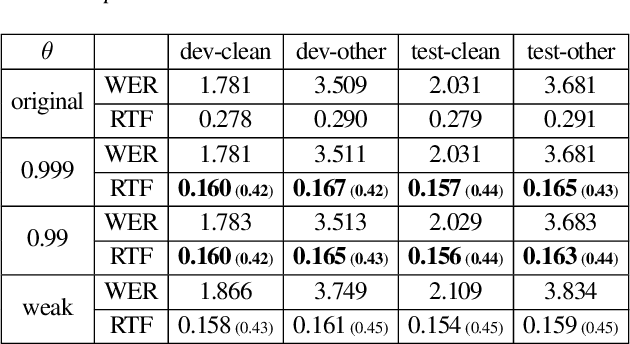
Connectionist Temporal Classification (CTC) model is a very efficient method for modeling sequences, especially for speech data. In order to use CTC model as an Automatic Speech Recognition (ASR) task, the beam search decoding with an external language model like n-gram LM is necessary to obtain reasonable results. In this paper we analyze the blank label in CTC beam search deeply and propose a very simple method to reduce the amount of calculation resulting in faster beam search decoding speed. With this method, we can get up to 78% faster decoding speed than ordinary beam search decoding with a very small loss of accuracy in LibriSpeech datasets. We prove this method is effective not only practically by experiments but also theoretically by mathematical reasoning. We also observe that this reduction is more obvious if the accuracy of the model is higher.