 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Unified Speech-Text Pretraining for Spoken Dialog Modeling
Feb 08, 2024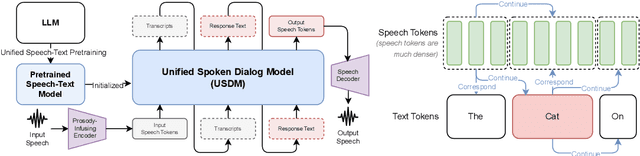
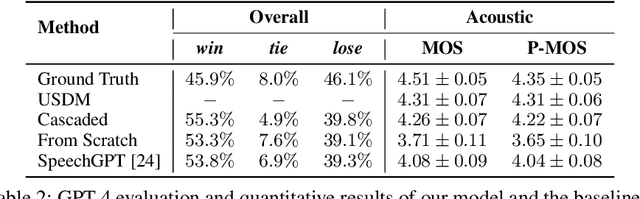
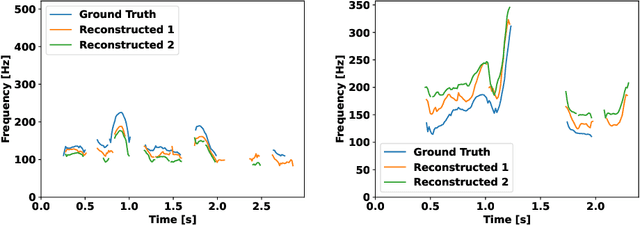
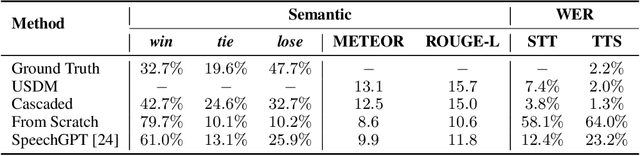
While recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech, an LLM-based strategy for modeling spoken dialogs remains elusive and calls for further investigation. This work proposes an extensive speech-text LLM framework, named the Unified Spoken Dialog Model (USDM), to generate coherent spoken responses with organic prosodic features relevant to the given input speech without relying on automatic speech recognition (ASR) or text-to-speech (TTS) solutions. Our approach employs a multi-step speech-text inference scheme that leverages chain-of-reasoning capabilities exhibited by the underlying LLM. We also propose a generalized speech-text pretraining scheme that helps with capturing cross-modal semantics. Automatic and human evaluations show that the proposed approach is effective in generating natural-sounding spoken responses, outperforming both prior and cascaded baselines. Detailed comparative studies reveal that, despite the cascaded approach being stronger in individual components, the joint speech-text modeling improves robustness against recognition errors and speech quality. Demo is available at https://unifiedsdm.github.io.
Encoder-decoder multimodal speaker change detection
Jun 01, 2023The task of speaker change detection (SCD), which detects points where speakers change in an input, is essential for several applications. Several studies solved the SCD task using audio inputs only and have shown limited performance. Recently, multimodal SCD (MMSCD) models, which utilise text modality in addition to audio, have shown improved performance. In this study, the proposed model are built upon two main proposals, a novel mechanism for modality fusion and the adoption of a encoder-decoder architecture. Different to previous MMSCD works that extract speaker embeddings from extremely short audio segments, aligned to a single word, we use a speaker embedding extracted from 1.5s. A transformer decoder layer further improves the performance of an encoder-only MMSCD model. The proposed model achieves state-of-the-art results among studies that report SCD performance and is also on par with recent work that combines SCD with automatic speech recognition via human transcription.
Blank Collapse: Compressing CTC emission for the faster decoding
Oct 31, 2022
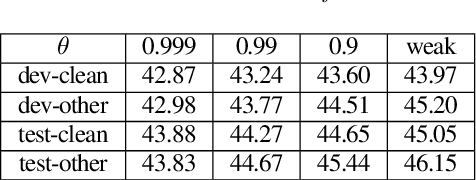

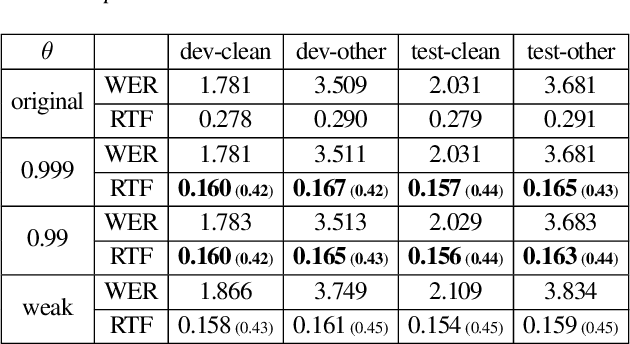
Connectionist Temporal Classification (CTC) model is a very efficient method for modeling sequences, especially for speech data. In order to use CTC model as an Automatic Speech Recognition (ASR) task, the beam search decoding with an external language model like n-gram LM is necessary to obtain reasonable results. In this paper we analyze the blank label in CTC beam search deeply and propose a very simple method to reduce the amount of calculation resulting in faster beam search decoding speed. With this method, we can get up to 78% faster decoding speed than ordinary beam search decoding with a very small loss of accuracy in LibriSpeech datasets. We prove this method is effective not only practically by experiments but also theoretically by mathematical reasoning. We also observe that this reduction is more obvious if the accuracy of the model is higher.
Self-Attentive Multi-Layer Aggregation with Feature Recalibration and Normalization for End-to-End Speaker Verification System
Jul 28, 2020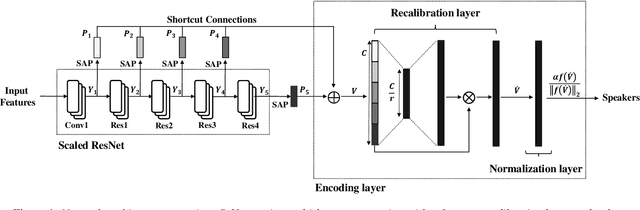
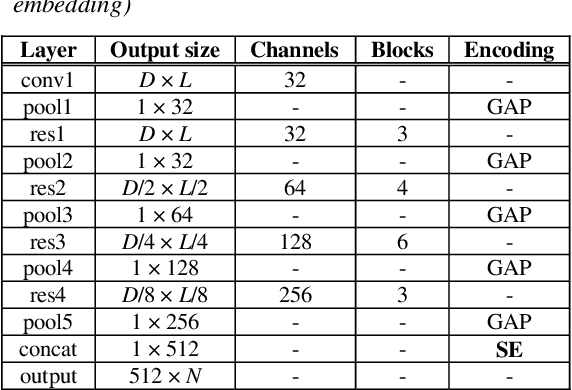
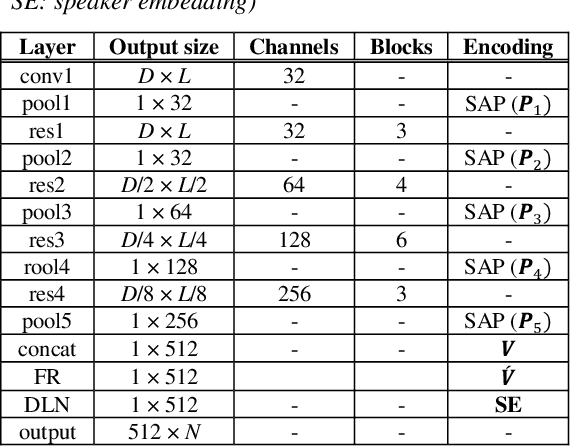

One of the most important parts of an end-to-end speaker verification system is the speaker embedding generation. In our previous paper, we reported that shortcut connections-based multi-layer aggregation improves the representational power of the speaker embedding. However, the number of model parameters is relatively large and the unspecified variations increase in the multi-layer aggregation. Therefore, we propose a self-attentive multi-layer aggregation with feature recalibration and normalization for end-to-end speaker verification system. To reduce the number of model parameters, the ResNet, which scaled channel width and layer depth, is used as a baseline. To control the variability in the training, a self-attention mechanism is applied to perform the multi-layer aggregation with dropout regularizations and batch normalizations. Then, a feature recalibration layer is applied to the aggregated feature using fully-connected layers and nonlinear activation functions. Deep length normalization is also used on a recalibrated feature in the end-to-end training process. Experimental results using the VoxCeleb1 evaluation dataset showed that the performance of the proposed methods was comparable to that of state-of-the-art models (equal error rate of 4.95% and 2.86%, using the VoxCeleb1 and VoxCeleb2 training datasets, respectively).
Masked cross self-attention encoding for deep speaker embedding
Jan 28, 2020
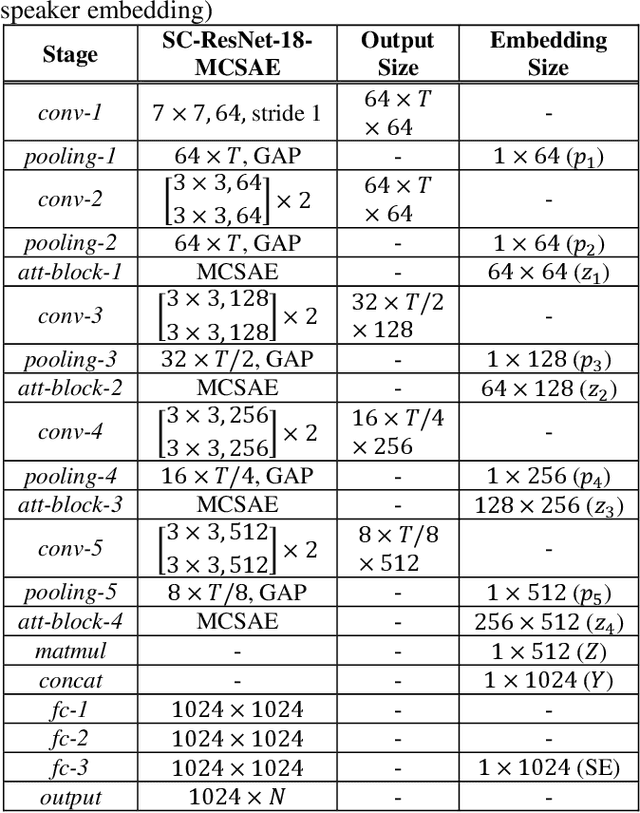
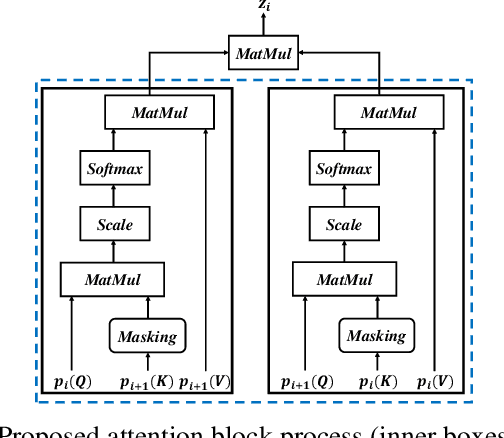
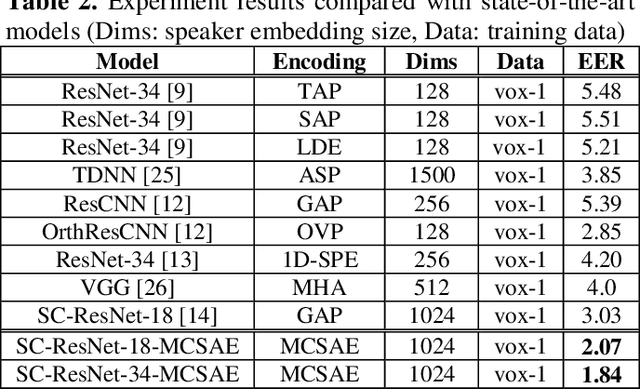
In general, speaker verification tasks require the extraction of speaker embedding from a deep neural network. As speaker embedding may contain additional information such as noise besides speaker information, its variability controlling is needed. Our previous model have used multiple pooling based on shortcut connections to amplify speaker information by deepening the dimension; however, the problem of variability remains. In this paper, we propose a masked cross self-attention encoding (MCSAE) for deep speaker embedding. This method controls the variability of speaker embedding by focusing on each masked output of multiple pooling on each other. The output of the MCSAE is used to construct the deep speaker embedding. Experimental results on VoxCeleb data set demonstrate that the proposed approach improves performance as compared with previous state-of-the-art models.