 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Unified Speech-Text Pretraining for Spoken Dialog Modeling
Feb 08, 2024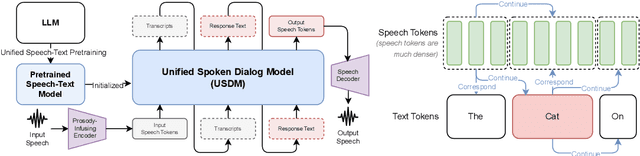
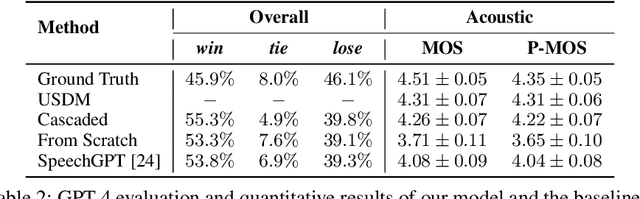
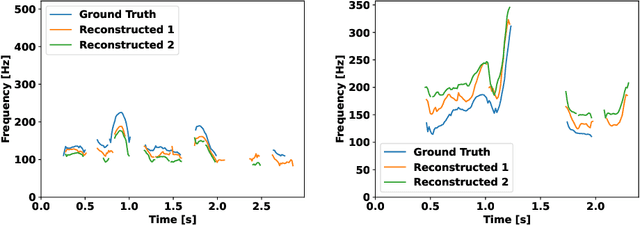
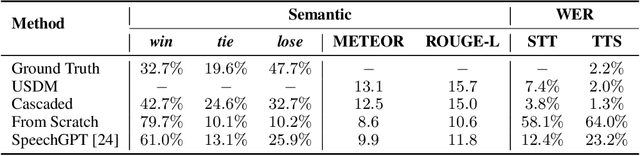
While recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech, an LLM-based strategy for modeling spoken dialogs remains elusive and calls for further investigation. This work proposes an extensive speech-text LLM framework, named the Unified Spoken Dialog Model (USDM), to generate coherent spoken responses with organic prosodic features relevant to the given input speech without relying on automatic speech recognition (ASR) or text-to-speech (TTS) solutions. Our approach employs a multi-step speech-text inference scheme that leverages chain-of-reasoning capabilities exhibited by the underlying LLM. We also propose a generalized speech-text pretraining scheme that helps with capturing cross-modal semantics. Automatic and human evaluations show that the proposed approach is effective in generating natural-sounding spoken responses, outperforming both prior and cascaded baselines. Detailed comparative studies reveal that, despite the cascaded approach being stronger in individual components, the joint speech-text modeling improves robustness against recognition errors and speech quality. Demo is available at https://unifiedsdm.github.io.
Language Model-Based Emotion Prediction Methods for Emotional Speech Synthesis Systems
Jul 01, 2022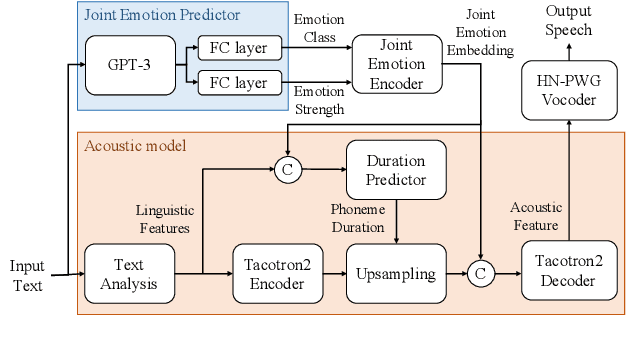

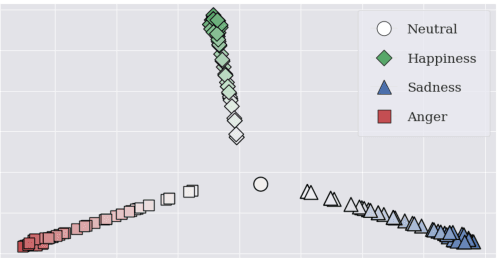

This paper proposes an effective emotional text-to-speech (TTS) system with a pre-trained language model (LM)-based emotion prediction method. Unlike conventional systems that require auxiliary inputs such as manually defined emotion classes, our system directly estimates emotion-related attributes from the input text. Specifically, we utilize generative pre-trained transformer (GPT)-3 to jointly predict both an emotion class and its strength in representing emotions coarse and fine properties, respectively. Then, these attributes are combined in the emotional embedding space and used as conditional features of the TTS model for generating output speech signals. Consequently, the proposed system can produce emotional speech only from text without any auxiliary inputs. Furthermore, because the GPT-3 enables to capture emotional context among the consecutive sentences, the proposed method can effectively handle the paragraph-level generation of emotional speech.
TTS-by-TTS 2: Data-selective augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder
Jun 30, 2022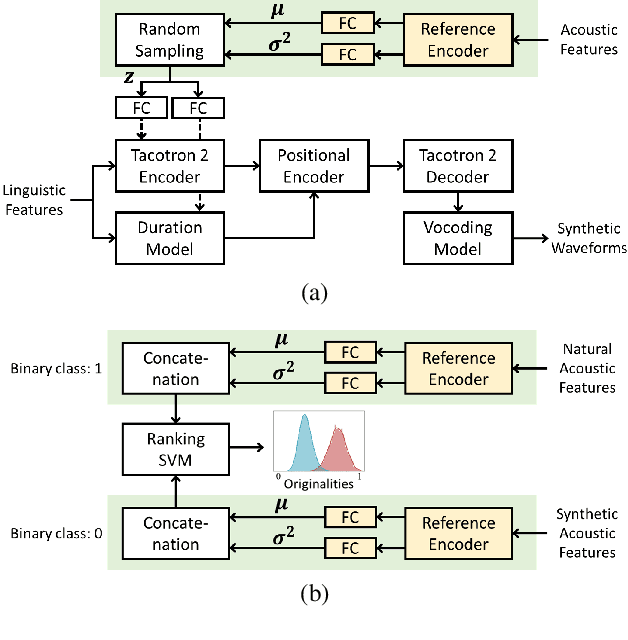

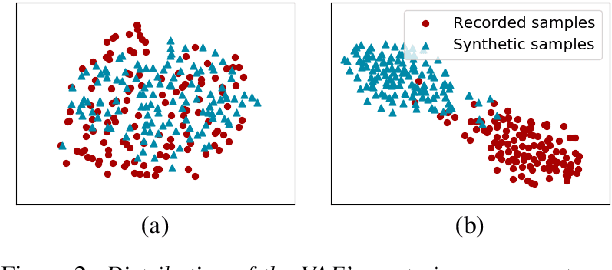
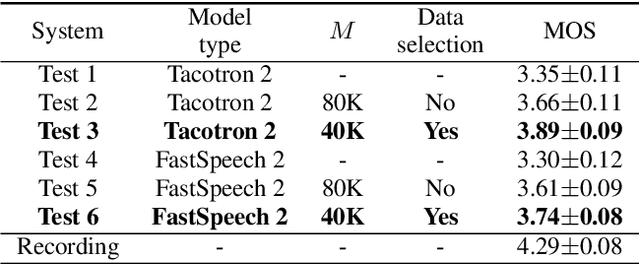
Recent advances in synthetic speech quality have enabled us to train text-to-speech (TTS) systems by using synthetic corpora. However, merely increasing the amount of synthetic data is not always advantageous for improving training efficiency. Our aim in this study is to selectively choose synthetic data that are beneficial to the training process. In the proposed method, we first adopt a variational autoencoder whose posterior distribution is utilized to extract latent features representing acoustic similarity between the recorded and synthetic corpora. By using those learned features, we then train a ranking support vector machine (RankSVM) that is well known for effectively ranking relative attributes among binary classes. By setting the recorded and synthetic ones as two opposite classes, RankSVM is used to determine how the synthesized speech is acoustically similar to the recorded data. Then, synthetic TTS data, whose distribution is close to the recorded data, are selected from large-scale synthetic corpora. By using these data for retraining the TTS model, the synthetic quality can be significantly improved. Objective and subjective evaluation results show the superiority of the proposed method over the conventional methods.
Improved parallel WaveGAN vocoder with perceptually weighted spectrogram loss
Jan 19, 2021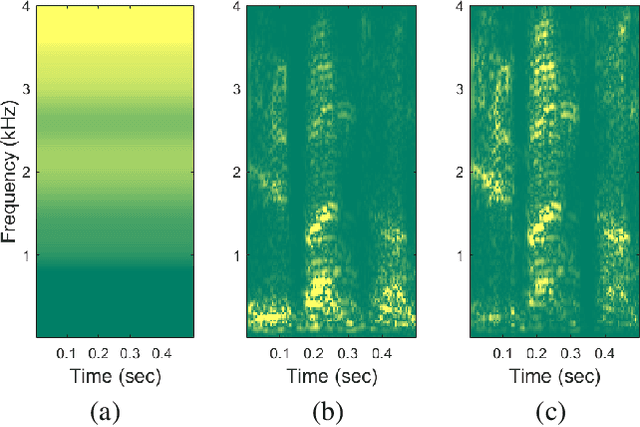


This paper proposes a spectral-domain perceptual weighting technique for Parallel WaveGAN-based text-to-speech (TTS) systems. The recently proposed Parallel WaveGAN vocoder successfully generates waveform sequences using a fast non-autoregressive WaveNet model. By employing multi-resolution short-time Fourier transform (MR-STFT) criteria with a generative adversarial network, the light-weight convolutional networks can be effectively trained without any distillation process. To further improve the vocoding performance, we propose the application of frequency-dependent weighting to the MR-STFT loss function. The proposed method penalizes perceptually-sensitive errors in the frequency domain; thus, the model is optimized toward reducing auditory noise in the synthesized speech. Subjective listening test results demonstrate that our proposed method achieves 4.21 and 4.26 TTS mean opinion scores for female and male Korean speakers, respectively.
Effective parameter estimation methods for an ExcitNet model in generative text-to-speech systems
May 21, 2019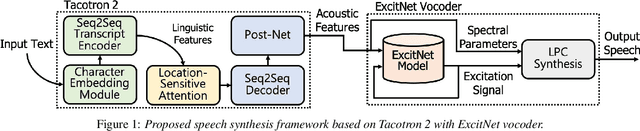

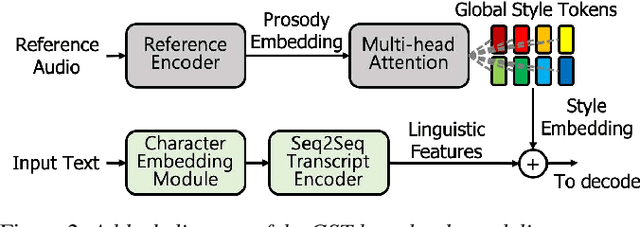
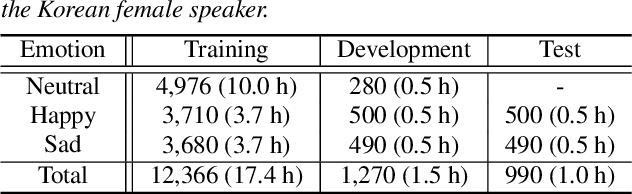
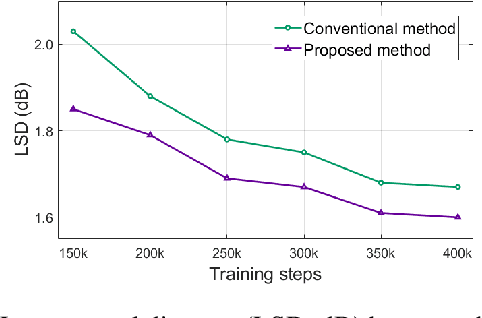
In this paper, we propose a high-quality generative text-to-speech (TTS) system using an effective spectrum and excitation estimation method. Our previous research verified the effectiveness of the ExcitNet-based speech generation model in a parametric TTS framework. However, the challenge remains to build a high-quality speech synthesis system because auxiliary conditional features estimated by a simple deep neural network often contain large prediction errors, and the errors are inevitably propagated throughout the autoregressive generation process of the ExcitNet vocoder. To generate more natural speech signals, we exploited a sequence-to-sequence (seq2seq) acoustic model with an attention-based generative network (e.g., Tacotron 2) to estimate the condition parameters of the ExcitNet vocoder. Because the seq2seq acoustic model accurately estimates spectral parameters, and because the ExcitNet model effectively generates the corresponding time-domain excitation signals, combining these two models can synthesize natural speech signals. Furthermore, we verified the merit of the proposed method in producing expressive speech segments by adopting a global style token-based emotion embedding method. The experimental results confirmed that the proposed system significantly outperforms the systems with a similarly configured conventional WaveNet vocoder and our best prior parametric TTS counterpart.