 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Speech-Text Pretraining for Spoken Dialog Modeling
Feb 08, 2024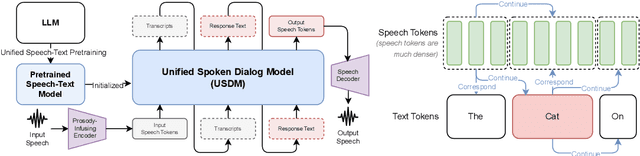
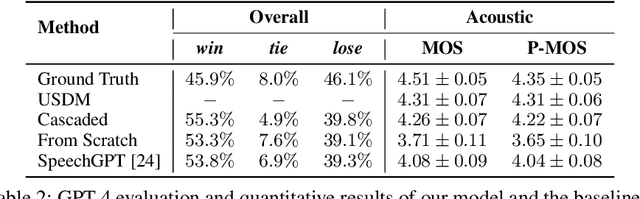
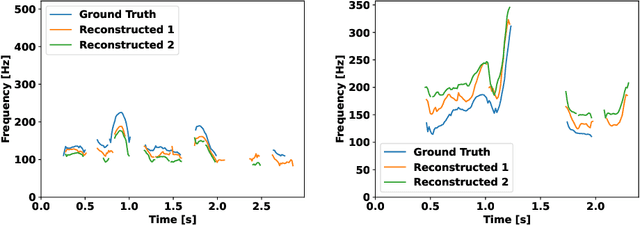
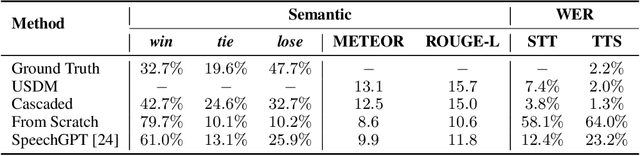
While recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech, an LLM-based strategy for modeling spoken dialogs remains elusive and calls for further investigation. This work proposes an extensive speech-text LLM framework, named the Unified Spoken Dialog Model (USDM), to generate coherent spoken responses with organic prosodic features relevant to the given input speech without relying on automatic speech recognition (ASR) or text-to-speech (TTS) solutions. Our approach employs a multi-step speech-text inference scheme that leverages chain-of-reasoning capabilities exhibited by the underlying LLM. We also propose a generalized speech-text pretraining scheme that helps with capturing cross-modal semantics. Automatic and human evaluations show that the proposed approach is effective in generating natural-sounding spoken responses, outperforming both prior and cascaded baselines. Detailed comparative studies reveal that, despite the cascaded approach being stronger in individual components, the joint speech-text modeling improves robustness against recognition errors and speech quality. Demo is available at https://unifiedsdm.github.io.
Incorporating L2 Phonemes Using Articulatory Features for Robust Speech Recognition
Jun 05, 2023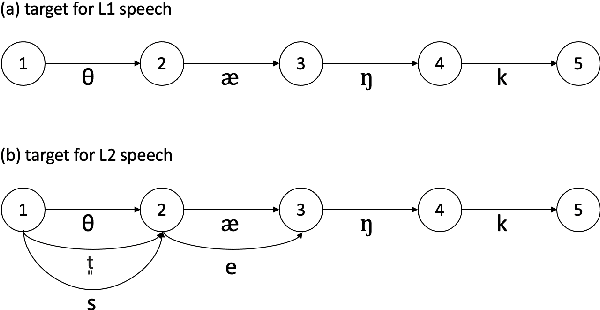

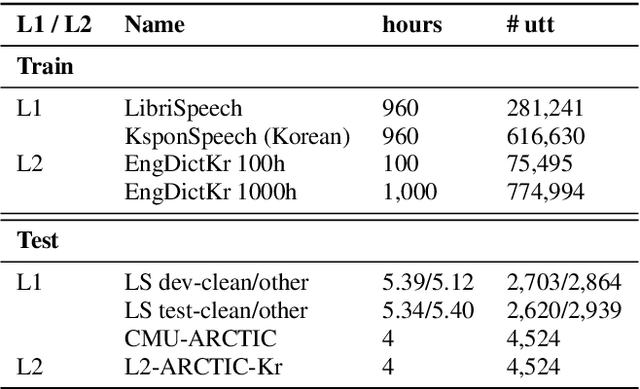

The limited availability of non-native speech datasets presents a major challenge in automatic speech recognition (ASR) to narrow the performance gap between native and non-native speakers. To address this, the focus of this study is on the efficient incorporation of the L2 phonemes, which in this work refer to Korean phonemes, through articulatory feature analysis. This not only enables accurate modeling of pronunciation variants but also allows for the utilization of both native Korean and English speech datasets. We employ the lattice-free maximum mutual information (LF-MMI) objective in an end-to-end manner, to train the acoustic model to align and predict one of multiple pronunciation candidates. Experimental results show that the proposed method improves ASR accuracy for Korean L2 speech by training solely on L1 speech data. Furthermore, fine-tuning on L2 speech improves recognition accuracy for both L1 and L2 speech without performance trade-offs.
Unsupervised Speech Domain Adaptation Based on Disentangled Representation Learning for Robust Speech Recognition
Apr 12, 2019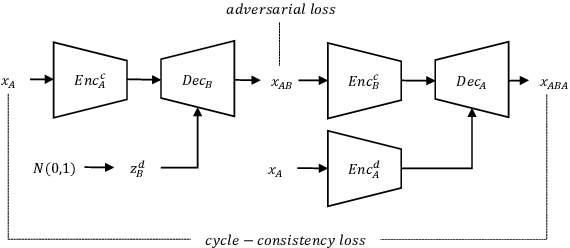
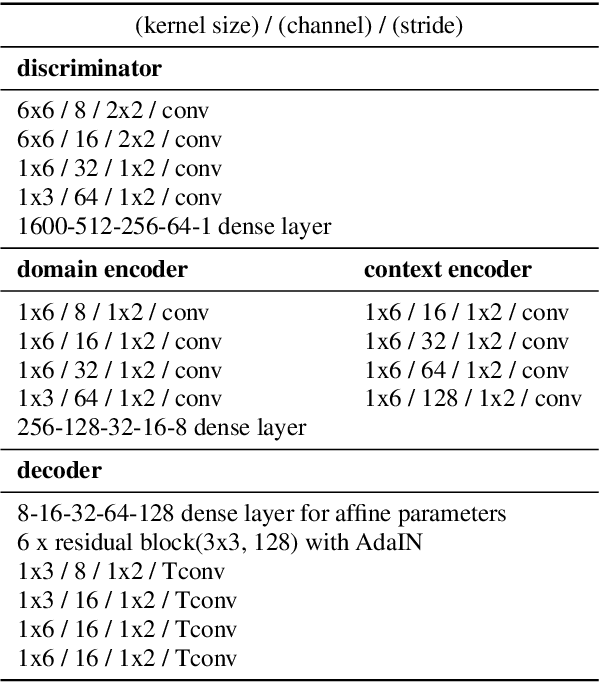
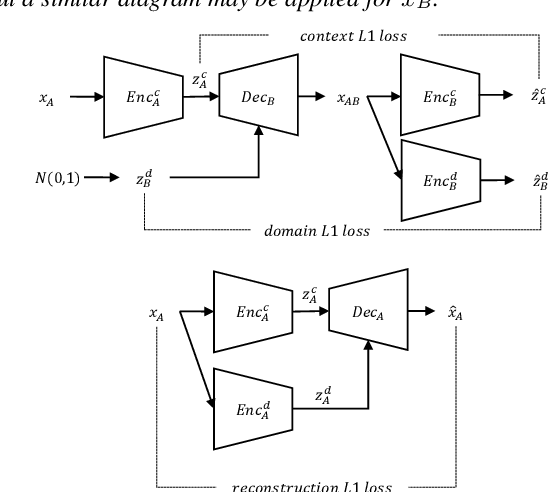
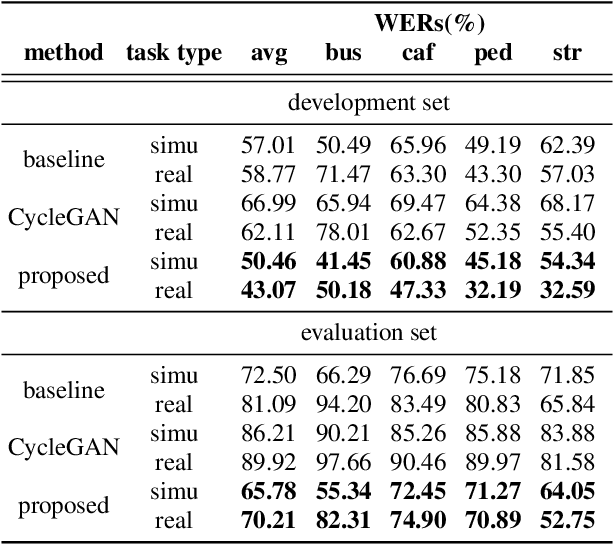
In general, the performance of automatic speech recognition (ASR) systems is significantly degraded due to the mismatch between training and test environments. Recently, a deep-learning-based image-to-image translation technique to translate an image from a source domain to a desired domain was presented, and cycle-consistent adversarial network (CycleGAN) was applied to learn a mapping for speech-to-speech conversion from a speaker to a target speaker. However, this method might not be adequate to remove corrupting noise components for robust ASR because it was designed to convert speech itself. In this paper, we propose a domain adaptation method based on generative adversarial nets (GANs) with disentangled representation learning to achieve robustness in ASR systems. In particular, two separated encoders, context and domain encoders, are introduced to learn distinct latent variables. The latent variables allow us to convert the domain of speech according to its context and domain representation. We improved word accuracies by 6.55~15.70\% for the CHiME4 challenge corpus by applying a noisy-to-clean environment adaptation for robust ASR. In addition, similar to the method based on the CycleGAN, this method can be used for gender adaptation in gender-mismatched recognition.