 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Incorporating L2 Phonemes Using Articulatory Features for Robust Speech Recognition
Jun 05, 2023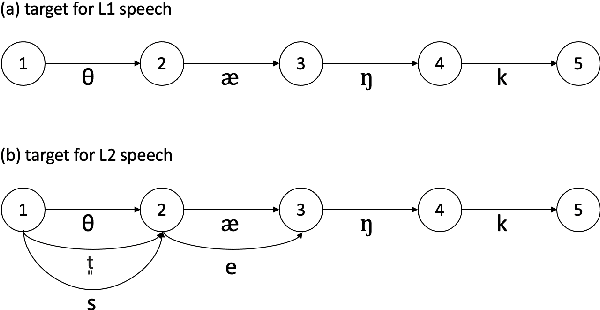


The limited availability of non-native speech datasets presents a major challenge in automatic speech recognition (ASR) to narrow the performance gap between native and non-native speakers. To address this, the focus of this study is on the efficient incorporation of the L2 phonemes, which in this work refer to Korean phonemes, through articulatory feature analysis. This not only enables accurate modeling of pronunciation variants but also allows for the utilization of both native Korean and English speech datasets. We employ the lattice-free maximum mutual information (LF-MMI) objective in an end-to-end manner, to train the acoustic model to align and predict one of multiple pronunciation candidates. Experimental results show that the proposed method improves ASR accuracy for Korean L2 speech by training solely on L1 speech data. Furthermore, fine-tuning on L2 speech improves recognition accuracy for both L1 and L2 speech without performance trade-offs.