 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Depth-Range Layer-Based Hologram Dataset for Machine Learning-Based 3D Computer-Generated Holography
Dec 24, 2025



Machine learning-based computer-generated holography (ML-CGH) has advanced rapidly in recent years, yet progress is constrained by the limited availability of high-quality, large-scale hologram datasets. To address this, we present KOREATECH-CGH, a publicly available dataset comprising 6,000 pairs of RGB-D images and complex holograms across resolutions ranging from 256*256 to 2048*2048, with depth ranges extending to the theoretical limits of the angular spectrum method for wide 3D scene coverage. To improve hologram quality at large depth ranges, we introduce amplitude projection, a post-processing technique that replaces amplitude components of hologram wavefields at each depth layer while preserving phase. This approach enhances reconstruction fidelity, achieving 27.01 dB PSNR and 0.87 SSIM, surpassing a recent optimized silhouette-masking layer-based method by 2.03 dB and 0.04 SSIM, respectively. We further validate the utility of KOREATECH-CGH through experiments on hologram generation and super-resolution using state-of-the-art ML models, confirming its applicability for training and evaluating next-generation ML-CGH systems.
MCAQ-YOLO: Morphological Complexity-Aware Quantization for Efficient Object Detection with Curriculum Learning
Nov 17, 2025



Most neural network quantization methods apply uniform bit precision across spatial regions, ignoring the heterogeneous structural and textural complexity of visual data. This paper introduces MCAQ-YOLO, a morphological complexity-aware quantization framework for object detection. The framework employs five morphological metrics - fractal dimension, texture entropy, gradient variance, edge density, and contour complexity - to characterize local visual morphology and guide spatially adaptive bit allocation. By correlating these metrics with quantization sensitivity, MCAQ-YOLO dynamically adjusts bit precision according to spatial complexity. In addition, a curriculum-based quantization-aware training scheme progressively increases quantization difficulty to stabilize optimization and accelerate convergence. Experimental results demonstrate a strong correlation between morphological complexity and quantization sensitivity and show that MCAQ-YOLO achieves superior detection accuracy and convergence efficiency compared with uniform quantization. On a safety equipment dataset, MCAQ-YOLO attains 85.6 percent mAP@0.5 with an average of 4.2 bits and a 7.6x compression ratio, yielding 3.5 percentage points higher mAP than uniform 4-bit quantization while introducing only 1.8 ms of additional runtime overhead per image. Cross-dataset validation on COCO and Pascal VOC further confirms consistent performance gains, indicating that morphology-driven spatial quantization can enhance efficiency and robustness for computationally constrained, safety-critical visual recognition tasks.
ReGUIDE: Data Efficient GUI Grounding via Spatial Reasoning and Search
May 21, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled autonomous agents to interact with computers via Graphical User Interfaces (GUIs), where accurately localizing the coordinates of interface elements (e.g., buttons) is often required for fine-grained actions. However, this remains significantly challenging, leading prior works to rely on large-scale web datasets to improve the grounding accuracy. In this work, we propose Reasoning Graphical User Interface Grounding for Data Efficiency (ReGUIDE), a novel and effective framework for web grounding that enables MLLMs to learn data efficiently through self-generated reasoning and spatial-aware criticism. More specifically, ReGUIDE learns to (i) self-generate a language reasoning process for the localization via online reinforcement learning, and (ii) criticize the prediction using spatial priors that enforce equivariance under input transformations. At inference time, ReGUIDE further boosts performance through a test-time scaling strategy, which combines spatial search with coordinate aggregation. Our experiments demonstrate that ReGUIDE significantly advances web grounding performance across multiple benchmarks, outperforming baselines with substantially fewer training data points (e.g., only 0.2% samples compared to the best open-sourced baselines).
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Unified Speech-Text Pretraining for Spoken Dialog Modeling
Feb 08, 2024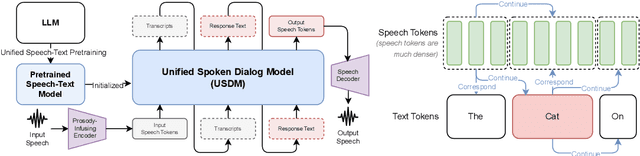
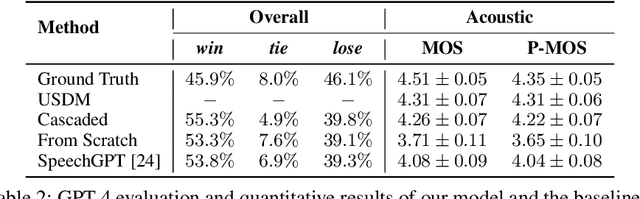
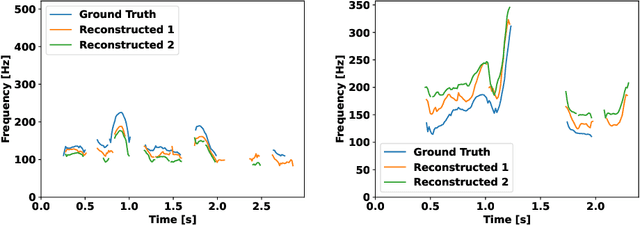
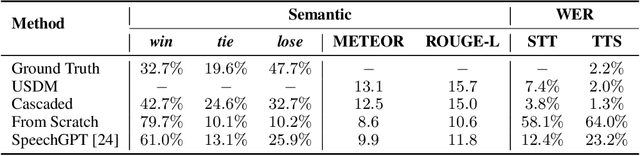
While recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech, an LLM-based strategy for modeling spoken dialogs remains elusive and calls for further investigation. This work proposes an extensive speech-text LLM framework, named the Unified Spoken Dialog Model (USDM), to generate coherent spoken responses with organic prosodic features relevant to the given input speech without relying on automatic speech recognition (ASR) or text-to-speech (TTS) solutions. Our approach employs a multi-step speech-text inference scheme that leverages chain-of-reasoning capabilities exhibited by the underlying LLM. We also propose a generalized speech-text pretraining scheme that helps with capturing cross-modal semantics. Automatic and human evaluations show that the proposed approach is effective in generating natural-sounding spoken responses, outperforming both prior and cascaded baselines. Detailed comparative studies reveal that, despite the cascaded approach being stronger in individual components, the joint speech-text modeling improves robustness against recognition errors and speech quality. Demo is available at https://unifiedsdm.github.io.