 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDR: Compressing Audio Tokens for Efficient Autoregressive Text-to-Speech
Jun 08, 2026Codec-based autoregressive (AR) speech language models have achieved strong text-to-speech (TTS) quality by modeling speech as sequences of discrete audio tokens with large pretrained backbones. However, this token-level formulation creates a structural efficiency bottleneck: speech-token sequences are much longer than text sequences, requiring the AR backbone to perform causal computation at every token position and maintain a KV cache that grows with the sequence length. We introduce TLDR, a patch-based autoregressive framework that accelerates codec-based AR-TTS by shifting the causal modeling from token-level speech sequences to patch-level sequences. TLDR groups consecutive codec tokens into compact latent patches using a lightweight compressor, models the resulting shorter patch sequence with a frozen pretrained AR-TTS backbone adapted by LoRA, and reconstructs fine-grained speech tokens within each patch using a speaker-conditioned extractor. With a patch size of 4, TLDR achieves a 1.8x inference speedup over the baseline AR-TTS model and reduces global KV-cache memory by up to 75%. Experimental results indicate that patch-level global causal modeling can be a practical way to reduce the inference cost of pretrained codec-based AR-TTS systems without replacing the existing modules.
Omni-Persona: Systematic Benchmarking and Improving Omnimodal Personalization
May 11, 2026While multimodal large language models have advanced across text, image, and audio, personalization research has remained primarily vision-language, with unified omnimodal benchmarking that jointly covers text, image, and audio still limited, and lacking the methodological rigor to account for absent-persona scenarios or systematic grounding studies. We introduce Omni-Persona, the first comprehensive benchmark for omnimodal personalization. We formalize the task as cross-modal routing over the \emph{Persona Modality Graph}, encompassing 4 task groups and 18 fine-grained tasks across ${\sim}750$ items. To rigorously diagnose grounding behavior, we propose \emph{Calibrated Accuracy ($\mathrm{Cal}$)}, which jointly rewards correct grounding and appropriate abstention, incorporating absent-persona queries within a unified evaluation framework. On our dedicated experiments, three diagnostic findings emerge: (i) open-source models show a consistent audio-vs-visual grounding gap that RLVR partially narrows via dense rule-based supervision; (ii) answerable recall and parameter scale are incomplete diagnostics, since strong recall can coexist with absent-persona hallucination and larger models do not always achieve higher $\mathrm{Cal}$, exposing calibration as a separate evaluation axis; and (iii) SFT is bounded by the difficulty of constructing annotated ground-truth supervision at scale, while RLVR generalizes more consistently through outcome-level verifiable feedback yet drifts toward conservative behavior and lower generation quality under our reward design. Omni-Persona thus serves as a diagnostic framework that surfaces the pitfalls of omnimodal personalization, guiding future post-training and reward design.
Mask2Flow-TSE: Two-Stage Target Speaker Extraction with Masking and Flow Matching
Mar 13, 2026Target speaker extraction (TSE) extracts the target speaker's voice from overlapping speech mixtures given a reference utterance. Existing approaches typically fall into two categories: discriminative and generative. Discriminative methods apply time-frequency masking for fast inference but often over-suppress the target signal, while generative methods synthesize high-quality speech at the cost of numerous iterative steps. We propose Mask2Flow-TSE, a two-stage framework combining the strengths of both paradigms. The first stage applies discriminative masking for coarse separation, and the second stage employs flow matching to refine the output toward target speech. Unlike generative approaches that synthesize speech from Gaussian noise, our method starts from the masked spectrogram, enabling high-quality reconstruction in a single inference step. Experiments show that Mask2Flow-TSE achieves comparable performance to existing generative TSE methods with approximately 85M parameters.
EdiText: Controllable Coarse-to-Fine Text Editing with Diffusion Language Models
Feb 27, 2025We propose EdiText, a controllable text editing method that modify the reference text to desired attributes at various scales. We integrate an SDEdit-based editing technique that allows for broad adjustments in the degree of text editing. Additionally, we introduce a novel fine-level editing method based on self-conditioning, which allows subtle control of reference text. While being capable of editing on its own, this fine-grained method, integrated with the SDEdit approach, enables EdiText to make precise adjustments within the desired range. EdiText demonstrates its controllability to robustly adjust reference text at broad range of levels across various tasks, including toxicity control and sentiment control.
Does Your Voice Assistant Remember? Analyzing Conversational Context Recall and Utilization in Voice Interaction Models
Feb 27, 2025Recent advancements in multi-turn voice interaction models have improved user-model communication. However, while closed-source models effectively retain and recall past utterances, whether open-source models share this ability remains unexplored. To fill this gap, we systematically evaluate how well open-source interaction models utilize past utterances using ContextDialog, a benchmark we proposed for this purpose. Our findings show that speech-based models have more difficulty than text-based ones, especially when recalling information conveyed in speech, and even with retrieval-augmented generation, models still struggle with questions about past utterances. These insights highlight key limitations in open-source models and suggest ways to improve memory retention and retrieval robustness.
Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator
Nov 23, 2024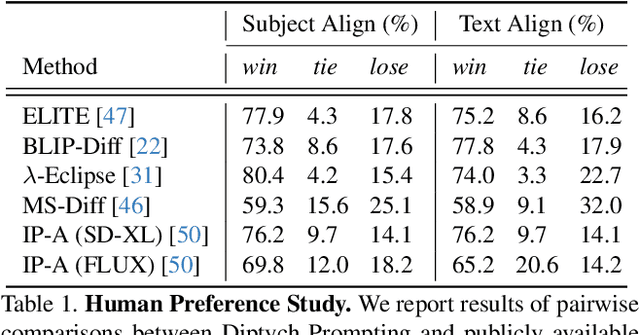

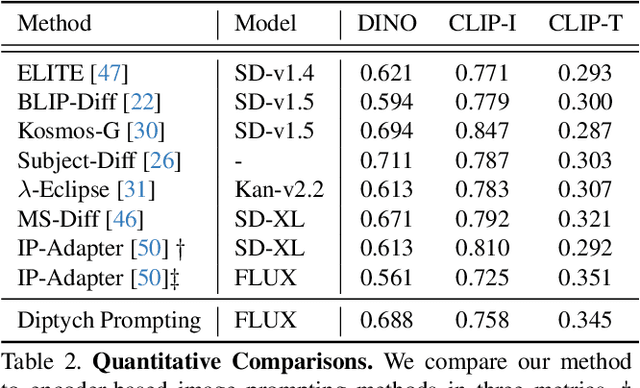
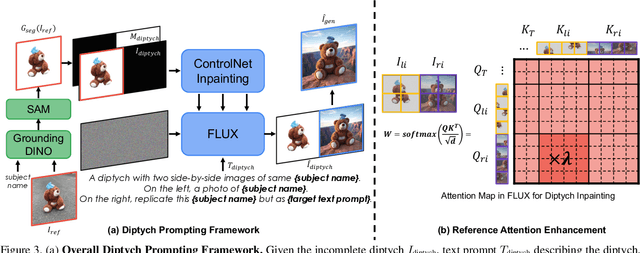
Subject-driven text-to-image generation aims to produce images of a new subject within a desired context by accurately capturing both the visual characteristics of the subject and the semantic content of a text prompt. Traditional methods rely on time- and resource-intensive fine-tuning for subject alignment, while recent zero-shot approaches leverage on-the-fly image prompting, often sacrificing subject alignment. In this paper, we introduce Diptych Prompting, a novel zero-shot approach that reinterprets as an inpainting task with precise subject alignment by leveraging the emergent property of diptych generation in large-scale text-to-image models. Diptych Prompting arranges an incomplete diptych with the reference image in the left panel, and performs text-conditioned inpainting on the right panel. We further prevent unwanted content leakage by removing the background in the reference image and improve fine-grained details in the generated subject by enhancing attention weights between the panels during inpainting. Experimental results confirm that our approach significantly outperforms zero-shot image prompting methods, resulting in images that are visually preferred by users. Additionally, our method supports not only subject-driven generation but also stylized image generation and subject-driven image editing, demonstrating versatility across diverse image generation applications. Project page: https://diptychprompting.github.io/
Style-Friendly SNR Sampler for Style-Driven Generation
Nov 22, 2024



Recent large-scale diffusion models generate high-quality images but struggle to learn new, personalized artistic styles, which limits the creation of unique style templates. Fine-tuning with reference images is the most promising approach, but it often blindly utilizes objectives and noise level distributions used for pre-training, leading to suboptimal style alignment. We propose the Style-friendly SNR sampler, which aggressively shifts the signal-to-noise ratio (SNR) distribution toward higher noise levels during fine-tuning to focus on noise levels where stylistic features emerge. This enables models to better capture unique styles and generate images with higher style alignment. Our method allows diffusion models to learn and share new "style templates", enhancing personalized content creation. We demonstrate the ability to generate styles such as personal watercolor paintings, minimal flat cartoons, 3D renderings, multi-panel images, and memes with text, thereby broadening the scope of style-driven generation.
VoiceGuider: Enhancing Out-of-Domain Performance in Parameter-Efficient Speaker-Adaptive Text-to-Speech via Autoguidance
Sep 24, 2024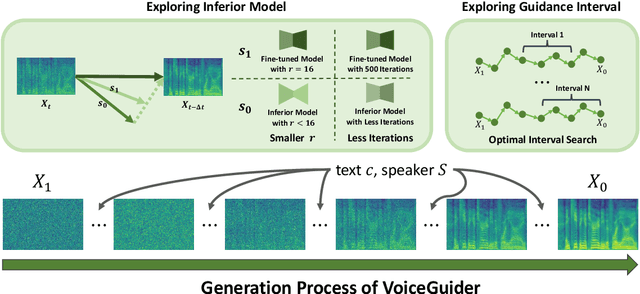
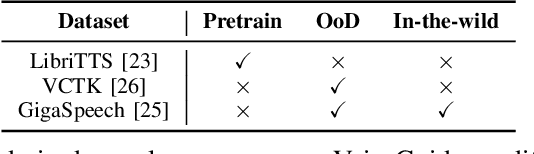
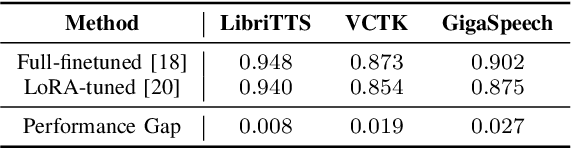
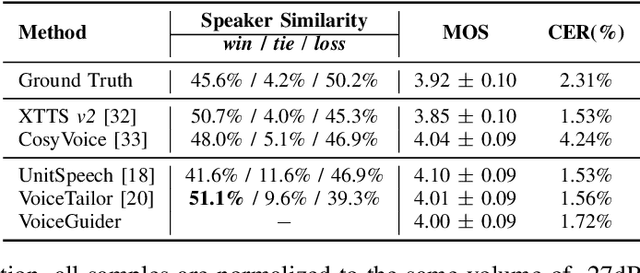
When applying parameter-efficient finetuning via LoRA onto speaker adaptive text-to-speech models, adaptation performance may decline compared to full-finetuned counterparts, especially for out-of-domain speakers. Here, we propose VoiceGuider, a parameter-efficient speaker adaptive text-to-speech system reinforced with autoguidance to enhance the speaker adaptation performance, reducing the gap against full-finetuned models. We carefully explore various ways of strengthening autoguidance, ultimately finding the optimal strategy. VoiceGuider as a result shows robust adaptation performance especially on extreme out-of-domain speech data. We provide audible samples in our demo page.
NanoVoice: Efficient Speaker-Adaptive Text-to-Speech for Multiple Speakers
Sep 24, 2024



We present NanoVoice, a personalized text-to-speech model that efficiently constructs voice adapters for multiple speakers simultaneously. NanoVoice introduces a batch-wise speaker adaptation technique capable of fine-tuning multiple references in parallel, significantly reducing training time. Beyond building separate adapters for each speaker, we also propose a parameter sharing technique that reduces the number of parameters used for speaker adaptation. By incorporating a novel trainable scale matrix, NanoVoice mitigates potential performance degradation during parameter sharing. NanoVoice achieves performance comparable to the baselines, while training 4 times faster and using 45 percent fewer parameters for speaker adaptation with 40 reference voices. Extensive ablation studies and analysis further validate the efficiency of our model.
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech
Aug 27, 2024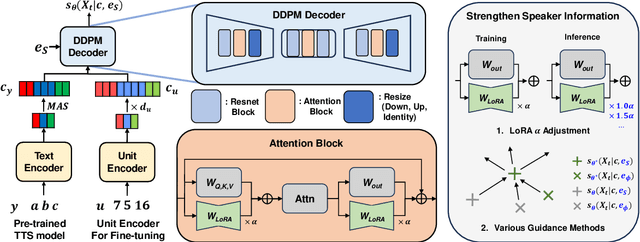
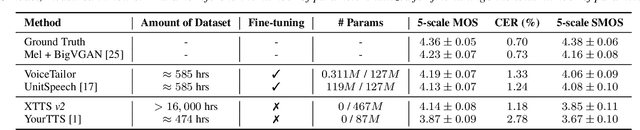
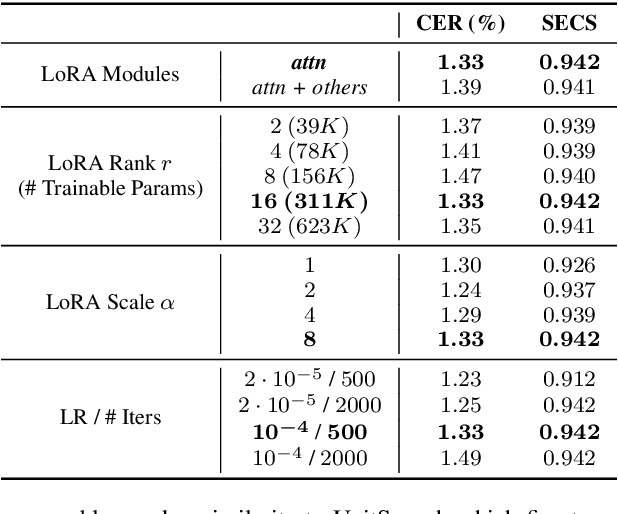
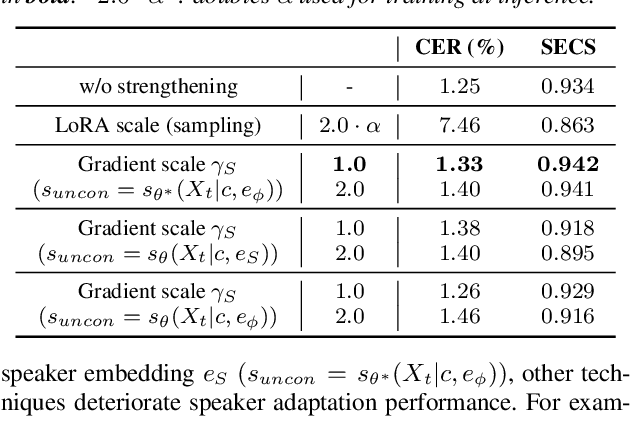
We propose VoiceTailor, a parameter-efficient speaker-adaptive text-to-speech (TTS) system, by equipping a pre-trained diffusion-based TTS model with a personalized adapter. VoiceTailor identifies pivotal modules that benefit from the adapter based on a weight change ratio analysis. We utilize Low-Rank Adaptation (LoRA) as a parameter-efficient adaptation method and incorporate the adapter into pivotal modules of the pre-trained diffusion decoder. To achieve powerful adaptation performance with few parameters, we explore various guidance techniques for speaker adaptation and investigate the best strategies to strengthen speaker information. VoiceTailor demonstrates comparable speaker adaptation performance to existing adaptive TTS models by fine-tuning only 0.25\% of the total parameters. VoiceTailor shows strong robustness when adapting to a wide range of real-world speakers, as shown in the demo.