 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextGuider: Training-Free Guidance for Text Rendering via Attention Alignment
Dec 13, 2025
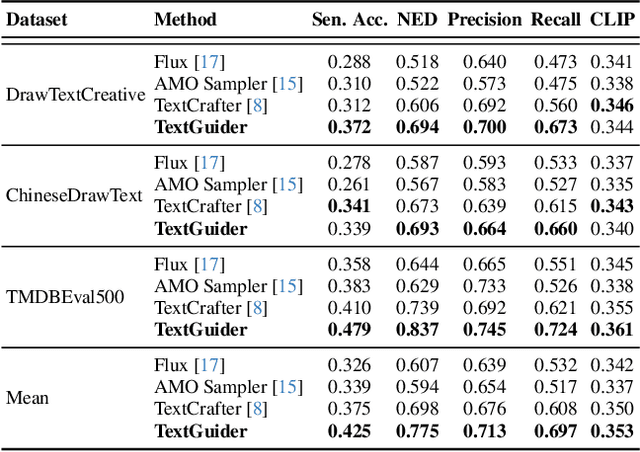
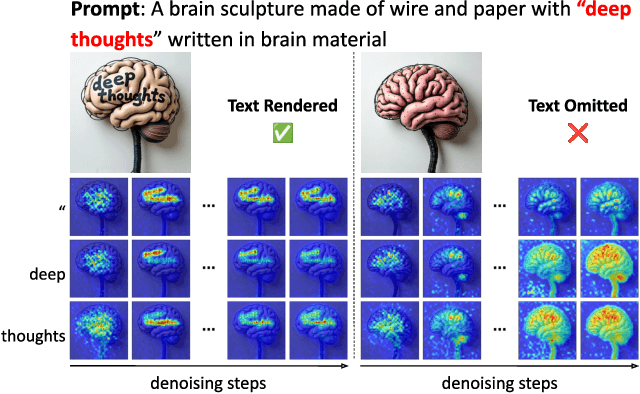
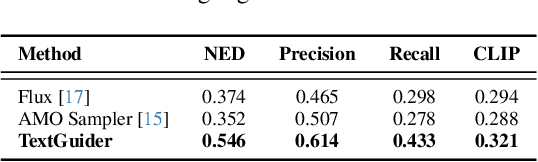
Despite recent advances, diffusion-based text-to-image models still struggle with accurate text rendering. Several studies have proposed fine-tuning or training-free refinement methods for accurate text rendering. However, the critical issue of text omission, where the desired text is partially or entirely missing, remains largely overlooked. In this work, we propose TextGuider, a novel training-free method that encourages accurate and complete text appearance by aligning textual content tokens and text regions in the image. Specifically, we analyze attention patterns in Multi-Modal Diffusion Transformer(MM-DiT) models, particularly for text-related tokens intended to be rendered in the image. Leveraging this observation, we apply latent guidance during the early stage of denoising steps based on two loss functions that we introduce. Our method achieves state-of-the-art performance in test-time text rendering, with significant gains in recall and strong results in OCR accuracy and CLIP score.
Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator
Nov 23, 2024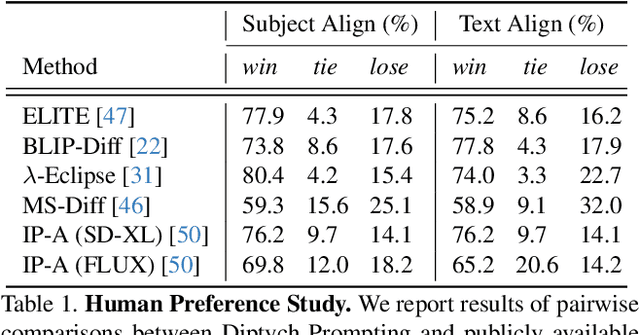

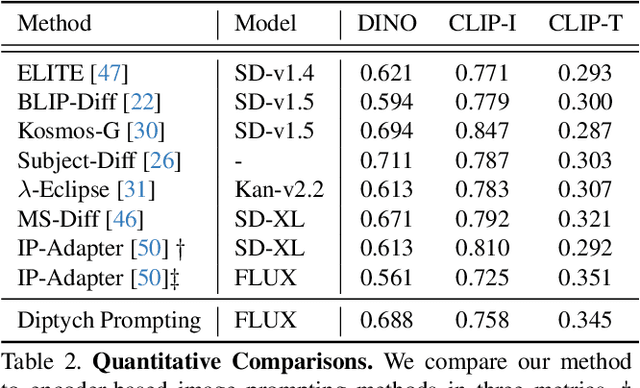
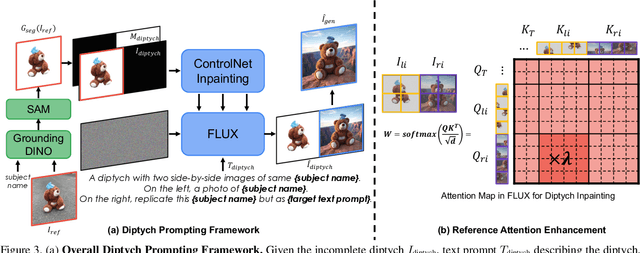
Subject-driven text-to-image generation aims to produce images of a new subject within a desired context by accurately capturing both the visual characteristics of the subject and the semantic content of a text prompt. Traditional methods rely on time- and resource-intensive fine-tuning for subject alignment, while recent zero-shot approaches leverage on-the-fly image prompting, often sacrificing subject alignment. In this paper, we introduce Diptych Prompting, a novel zero-shot approach that reinterprets as an inpainting task with precise subject alignment by leveraging the emergent property of diptych generation in large-scale text-to-image models. Diptych Prompting arranges an incomplete diptych with the reference image in the left panel, and performs text-conditioned inpainting on the right panel. We further prevent unwanted content leakage by removing the background in the reference image and improve fine-grained details in the generated subject by enhancing attention weights between the panels during inpainting. Experimental results confirm that our approach significantly outperforms zero-shot image prompting methods, resulting in images that are visually preferred by users. Additionally, our method supports not only subject-driven generation but also stylized image generation and subject-driven image editing, demonstrating versatility across diverse image generation applications. Project page: https://diptychprompting.github.io/
Style-Friendly SNR Sampler for Style-Driven Generation
Nov 22, 2024



Recent large-scale diffusion models generate high-quality images but struggle to learn new, personalized artistic styles, which limits the creation of unique style templates. Fine-tuning with reference images is the most promising approach, but it often blindly utilizes objectives and noise level distributions used for pre-training, leading to suboptimal style alignment. We propose the Style-friendly SNR sampler, which aggressively shifts the signal-to-noise ratio (SNR) distribution toward higher noise levels during fine-tuning to focus on noise levels where stylistic features emerge. This enables models to better capture unique styles and generate images with higher style alignment. Our method allows diffusion models to learn and share new "style templates", enhancing personalized content creation. We demonstrate the ability to generate styles such as personal watercolor paintings, minimal flat cartoons, 3D renderings, multi-panel images, and memes with text, thereby broadening the scope of style-driven generation.
Disentangled Motion Modeling for Video Frame Interpolation
Jun 25, 2024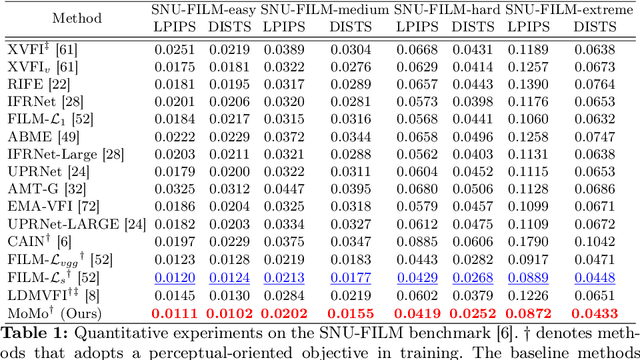
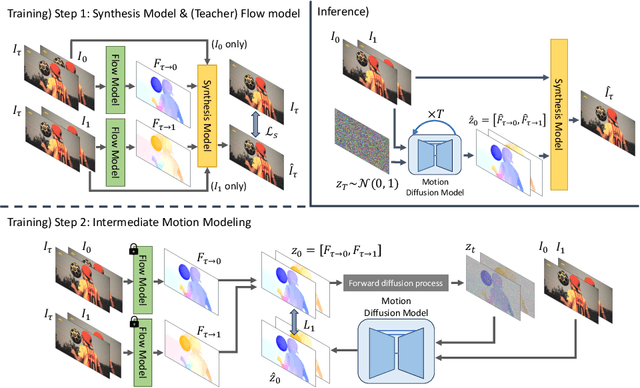

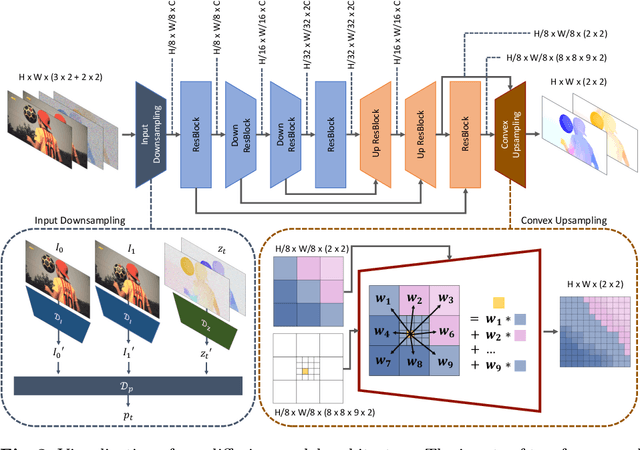
Video frame interpolation (VFI) aims to synthesize intermediate frames in between existing frames to enhance visual smoothness and quality. Beyond the conventional methods based on the reconstruction loss, recent works employ the high quality generative models for perceptual quality. However, they require complex training and large computational cost for modeling on the pixel space. In this paper, we introduce disentangled Motion Modeling (MoMo), a diffusion-based approach for VFI that enhances visual quality by focusing on intermediate motion modeling. We propose disentangled two-stage training process, initially training a frame synthesis model to generate frames from input pairs and their optical flows. Subsequently, we propose a motion diffusion model, equipped with our novel diffusion U-Net architecture designed for optical flow, to produce bi-directional flows between frames. This method, by leveraging the simpler low-frequency representation of motions, achieves superior perceptual quality with reduced computational demands compared to generative modeling methods on the pixel space. Our method surpasses state-of-the-art methods in perceptual metrics across various benchmarks, demonstrating its efficacy and efficiency in VFI. Our code is available at: https://github.com/JHLew/MoMo
Improving Diffusion-Based Generative Models via Approximated Optimal Transport
Mar 08, 2024



We introduce the Approximated Optimal Transport (AOT) technique, a novel training scheme for diffusion-based generative models. Our approach aims to approximate and integrate optimal transport into the training process, significantly enhancing the ability of diffusion models to estimate the denoiser outputs accurately. This improvement leads to ODE trajectories of diffusion models with lower curvature and reduced truncation errors during sampling. We achieve superior image quality and reduced sampling steps by employing AOT in training. Specifically, we achieve FID scores of 1.88 with just 27 NFEs and 1.73 with 29 NFEs in unconditional and conditional generations, respectively. Furthermore, when applying AOT to train the discriminator for guidance, we establish new state-of-the-art FID scores of 1.68 and 1.58 for unconditional and conditional generations, respectively, each with 29 NFEs. This outcome demonstrates the effectiveness of AOT in enhancing the performance of diffusion models.
ControlDreamer: Stylized 3D Generation with Multi-View ControlNet
Dec 02, 2023Recent advancements in text-to-3D generation have significantly contributed to the automation and democratization of 3D content creation. Building upon these developments, we aim to address the limitations of current methods in generating 3D models with creative geometry and styles. We introduce multi-view ControlNet, a novel depth-aware multi-view diffusion model trained on generated datasets from a carefully curated 100K text corpus. Our multi-view ControlNet is then integrated into our two-stage pipeline, ControlDreamer, enabling text-guided generation of stylized 3D models. Additionally, we present a comprehensive benchmark for 3D style editing, encompassing a broad range of subjects, including objects, animals, and characters, to further facilitate diverse 3D generation. Our comparative analysis reveals that this new pipeline outperforms existing text-to-3D methods as evidenced by qualitative comparisons and CLIP score metrics.
Diffusion-Stego: Training-free Diffusion Generative Steganography via Message Projection
May 30, 2023Generative steganography is the process of hiding secret messages in generated images instead of cover images. Existing studies on generative steganography use GAN or Flow models to obtain high hiding message capacity and anti-detection ability over cover images. However, they create relatively unrealistic stego images because of the inherent limitations of generative models. We propose Diffusion-Stego, a generative steganography approach based on diffusion models which outperform other generative models in image generation. Diffusion-Stego projects secret messages into latent noise of diffusion models and generates stego images with an iterative denoising process. Since the naive hiding of secret messages into noise boosts visual degradation and decreases extracted message accuracy, we introduce message projection, which hides messages into noise space while addressing these issues. We suggest three options for message projection to adjust the trade-off between extracted message accuracy, anti-detection ability, and image quality. Diffusion-Stego is a training-free approach, so we can apply it to pre-trained diffusion models which generate high-quality images, or even large-scale text-to-image models, such as Stable diffusion. Diffusion-Stego achieved a high capacity of messages (3.0 bpp of binary messages with 98% accuracy, and 6.0 bpp with 90% accuracy) as well as high quality (with a FID score of 2.77 for 1.0 bpp on the FFHQ 64$\times$64 dataset) that makes it challenging to distinguish from real images in the PNG format.
Edit-A-Video: Single Video Editing with Object-Aware Consistency
Apr 01, 2023
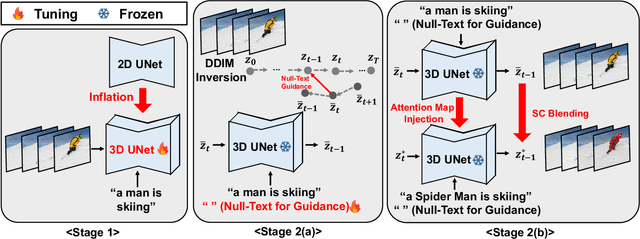
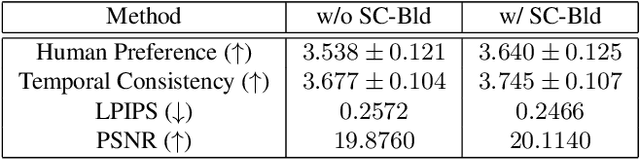

Despite the fact that text-to-video (TTV) model has recently achieved remarkable success, there have been few approaches on TTV for its extension to video editing. Motivated by approaches on TTV models adapting from diffusion-based text-to-image (TTI) models, we suggest the video editing framework given only a pretrained TTI model and a single <text, video> pair, which we term Edit-A-Video. The framework consists of two stages: (1) inflating the 2D model into the 3D model by appending temporal modules and tuning on the source video (2) inverting the source video into the noise and editing with target text prompt and attention map injection. Each stage enables the temporal modeling and preservation of semantic attributes of the source video. One of the key challenges for video editing include a background inconsistency problem, where the regions not included for the edit suffer from undesirable and inconsistent temporal alterations. To mitigate this issue, we also introduce a novel mask blending method, termed as sparse-causal blending (SC Blending). We improve previous mask blending methods to reflect the temporal consistency so that the area where the editing is applied exhibits smooth transition while also achieving spatio-temporal consistency of the unedited regions. We present extensive experimental results over various types of text and videos, and demonstrate the superiority of the proposed method compared to baselines in terms of background consistency, text alignment, and video editing quality.
Out of Sight, Out of Mind: A Source-View-Wise Feature Aggregation for Multi-View Image-Based Rendering
Jun 10, 2022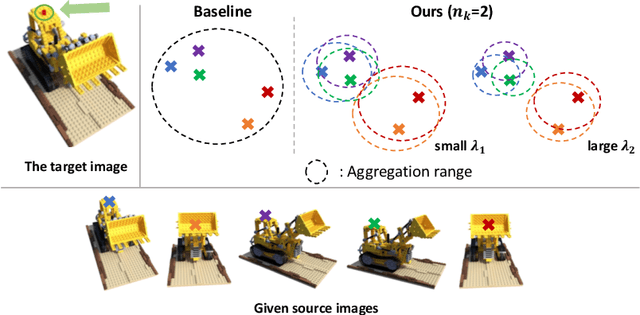
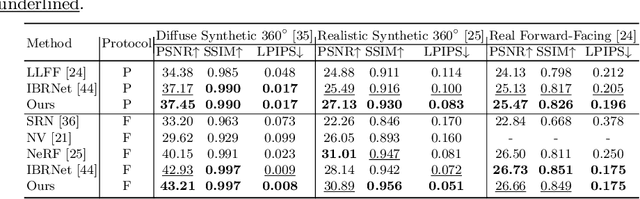
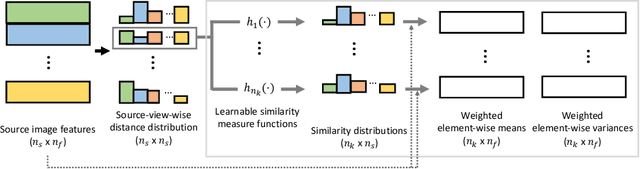

To estimate the volume density and color of a 3D point in the multi-view image-based rendering, a common approach is to inspect the consensus existence among the given source image features, which is one of the informative cues for the estimation procedure. To this end, most of the previous methods utilize equally-weighted aggregation features. However, this could make it hard to check the consensus existence when some outliers, which frequently occur by occlusions, are included in the source image feature set. In this paper, we propose a novel source-view-wise feature aggregation method, which facilitates us to find out the consensus in a robust way by leveraging local structures in the feature set. We first calculate the source-view-wise distance distribution for each source feature for the proposed aggregation. After that, the distance distribution is converted to several similarity distributions with the proposed learnable similarity mapping functions. Finally, for each element in the feature set, the aggregation features are extracted by calculating the weighted means and variances, where the weights are derived from the similarity distributions. In experiments, we validate the proposed method on various benchmark datasets, including synthetic and real image scenes. The experimental results demonstrate that incorporating the proposed features improves the performance by a large margin, resulting in the state-of-the-art performance.
Perception Prioritized Training of Diffusion Models
Apr 01, 2022
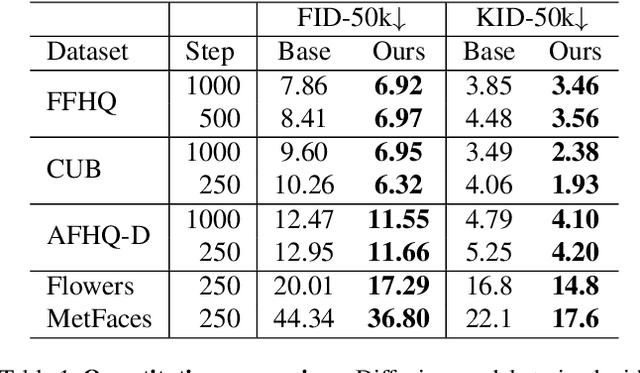


Diffusion models learn to restore noisy data, which is corrupted with different levels of noise, by optimizing the weighted sum of the corresponding loss terms, i.e., denoising score matching loss. In this paper, we show that restoring data corrupted with certain noise levels offers a proper pretext task for the model to learn rich visual concepts. We propose to prioritize such noise levels over other levels during training, by redesigning the weighting scheme of the objective function. We show that our simple redesign of the weighting scheme significantly improves the performance of diffusion models regardless of the datasets, architectures, and sampling strategies.