 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-BENCH: Evaluating Multi-Agent Collaboration under Privacy Constraints
Apr 13, 2026We are entering an era in which individuals and organizations increasingly deploy dedicated AI agents that interact and collaborate with other agents. However, the dynamics of multi-agent collaboration under privacy constraints remain poorly understood. In this work, we present $PAC\text{-}Bench$, a benchmark for systematic evaluation of multi-agent collaboration under privacy constraints. Experiments on $PAC\text{-}Bench$ show that privacy constraints substantially degrade collaboration performance and make outcomes depend more on the initiating agent than the partner. Further analysis reveals that this degradation is driven by recurring coordination breakdowns, including early-stage privacy violations, overly conservative abstraction, and privacy-induced hallucinations. Together, our findings identify privacy-aware multi-agent collaboration as a distinct and unresolved challenge that requires new coordination mechanisms beyond existing agent capabilities.
LLM Meets Scene Graph: Can Large Language Models Understand and Generate Scene Graphs? A Benchmark and Empirical Study
May 26, 2025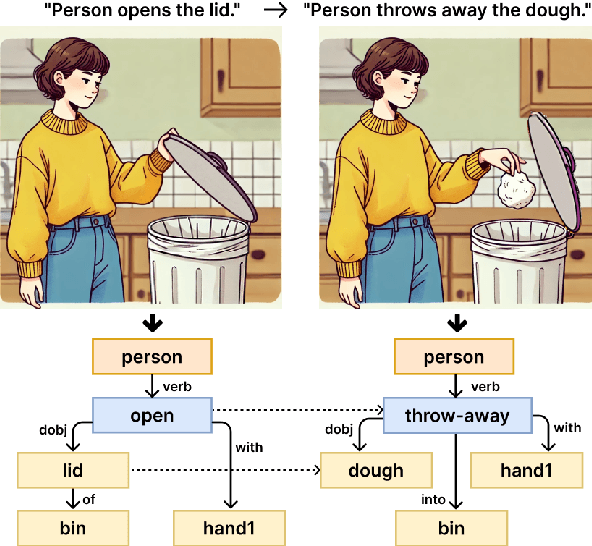

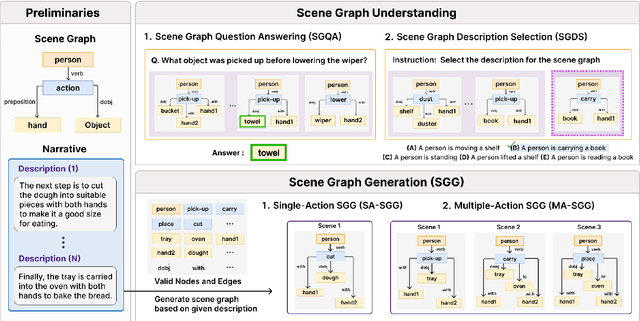

The remarkable reasoning and generalization capabilities of Large Language Models (LLMs) have paved the way for their expanding applications in embodied AI, robotics, and other real-world tasks. To effectively support these applications, grounding in spatial and temporal understanding in multimodal environments is essential. To this end, recent works have leveraged scene graphs, a structured representation that encodes entities, attributes, and their relationships in a scene. However, a comprehensive evaluation of LLMs' ability to utilize scene graphs remains limited. In this work, we introduce Text-Scene Graph (TSG) Bench, a benchmark designed to systematically assess LLMs' ability to (1) understand scene graphs and (2) generate them from textual narratives. With TSG Bench we evaluate 11 LLMs and reveal that, while models perform well on scene graph understanding, they struggle with scene graph generation, particularly for complex narratives. Our analysis indicates that these models fail to effectively decompose discrete scenes from a complex narrative, leading to a bottleneck when generating scene graphs. These findings underscore the need for improved methodologies in scene graph generation and provide valuable insights for future research. The demonstration of our benchmark is available at https://tsg-bench.netlify.app. Additionally, our code and evaluation data are publicly available at https://anonymous.4open.science/r/TSG-Bench.
Improving Geometry in Sparse-View 3DGS via Reprojection-based DoF Separation
Dec 19, 2024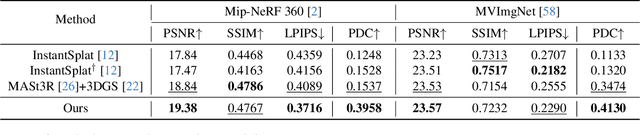

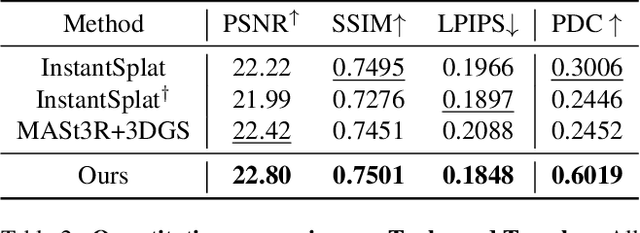
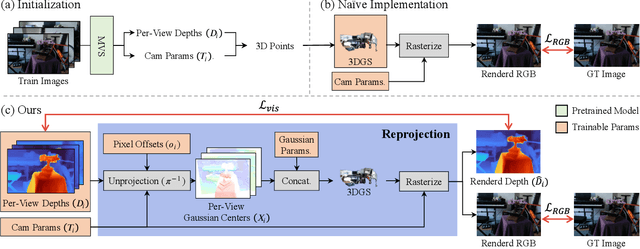
Recent learning-based Multi-View Stereo models have demonstrated state-of-the-art performance in sparse-view 3D reconstruction. However, directly applying 3D Gaussian Splatting (3DGS) as a refinement step following these models presents challenges. We hypothesize that the excessive positional degrees of freedom (DoFs) in Gaussians induce geometry distortion, fitting color patterns at the cost of structural fidelity. To address this, we propose reprojection-based DoF separation, a method distinguishing positional DoFs in terms of uncertainty: image-plane-parallel DoFs and ray-aligned DoF. To independently manage each DoF, we introduce a reprojection process along with tailored constraints for each DoF. Through experiments across various datasets, we confirm that separating the positional DoFs of Gaussians and applying targeted constraints effectively suppresses geometric artifacts, producing reconstruction results that are both visually and geometrically plausible.
Gradient Alignment with Prototype Feature for Fully Test-time Adaptation
Feb 14, 2024



In context of Test-time Adaptation(TTA), we propose a regularizer, dubbed Gradient Alignment with Prototype feature (GAP), which alleviates the inappropriate guidance from entropy minimization loss from misclassified pseudo label. We developed a gradient alignment loss to precisely manage the adaptation process, ensuring that changes made for some data don't negatively impact the model's performance on other data. We introduce a prototype feature of a class as a proxy measure of the negative impact. To make GAP regularizer feasible under the TTA constraints, where model can only access test data without labels, we tailored its formula in two ways: approximating prototype features with weight vectors of the classifier, calculating gradient without back-propagation. We demonstrate GAP significantly improves TTA methods across various datasets, which proves its versatility and effectiveness.
ControlDreamer: Stylized 3D Generation with Multi-View ControlNet
Dec 02, 2023Recent advancements in text-to-3D generation have significantly contributed to the automation and democratization of 3D content creation. Building upon these developments, we aim to address the limitations of current methods in generating 3D models with creative geometry and styles. We introduce multi-view ControlNet, a novel depth-aware multi-view diffusion model trained on generated datasets from a carefully curated 100K text corpus. Our multi-view ControlNet is then integrated into our two-stage pipeline, ControlDreamer, enabling text-guided generation of stylized 3D models. Additionally, we present a comprehensive benchmark for 3D style editing, encompassing a broad range of subjects, including objects, animals, and characters, to further facilitate diverse 3D generation. Our comparative analysis reveals that this new pipeline outperforms existing text-to-3D methods as evidenced by qualitative comparisons and CLIP score metrics.