 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Visual Personalization in Vision-Language Models
Feb 03, 2026Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
Guiding What Not to Generate: Automated Negative Prompting for Text-Image Alignment
Dec 11, 2025Despite substantial progress in text-to-image generation, achieving precise text-image alignment remains challenging, particularly for prompts with rich compositional structure or imaginative elements. To address this, we introduce Negative Prompting for Image Correction (NPC), an automated pipeline that improves alignment by identifying and applying negative prompts that suppress unintended content. We begin by analyzing cross-attention patterns to explain why both targeted negatives-those directly tied to the prompt's alignment error-and untargeted negatives-tokens unrelated to the prompt but present in the generated image-can enhance alignment. To discover useful negatives, NPC generates candidate prompts using a verifier-captioner-proposer framework and ranks them with a salient text-space score, enabling effective selection without requiring additional image synthesis. On GenEval++ and Imagine-Bench, NPC outperforms strong baselines, achieving 0.571 vs. 0.371 on GenEval++ and the best overall performance on Imagine-Bench. By guiding what not to generate, NPC provides a principled, fully automated route to stronger text-image alignment in diffusion models. Code is released at https://github.com/wiarae/NPC.
Style-Friendly SNR Sampler for Style-Driven Generation
Nov 22, 2024



Recent large-scale diffusion models generate high-quality images but struggle to learn new, personalized artistic styles, which limits the creation of unique style templates. Fine-tuning with reference images is the most promising approach, but it often blindly utilizes objectives and noise level distributions used for pre-training, leading to suboptimal style alignment. We propose the Style-friendly SNR sampler, which aggressively shifts the signal-to-noise ratio (SNR) distribution toward higher noise levels during fine-tuning to focus on noise levels where stylistic features emerge. This enables models to better capture unique styles and generate images with higher style alignment. Our method allows diffusion models to learn and share new "style templates", enhancing personalized content creation. We demonstrate the ability to generate styles such as personal watercolor paintings, minimal flat cartoons, 3D renderings, multi-panel images, and memes with text, thereby broadening the scope of style-driven generation.
Efficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024

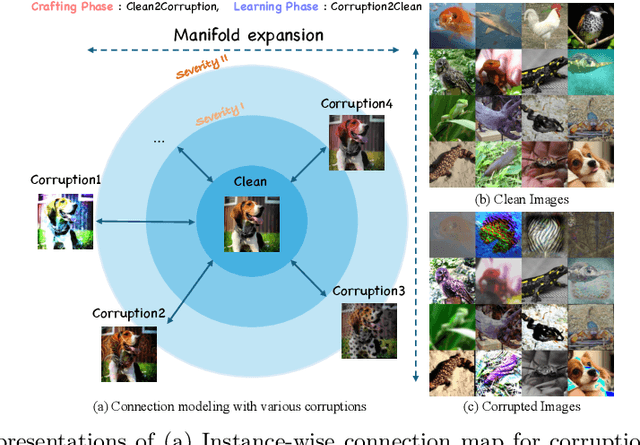

Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
On mitigating stability-plasticity dilemma in CLIP-guided image morphing via geodesic distillation loss
Jan 19, 2024Large-scale language-vision pre-training models, such as CLIP, have achieved remarkable text-guided image morphing results by leveraging several unconditional generative models. However, existing CLIP-guided image morphing methods encounter difficulties when morphing photorealistic images. Specifically, existing guidance fails to provide detailed explanations of the morphing regions within the image, leading to misguidance. In this paper, we observed that such misguidance could be effectively mitigated by simply using a proper regularization loss. Our approach comprises two key components: 1) a geodesic cosine similarity loss that minimizes inter-modality features (i.e., image and text) on a projected subspace of CLIP space, and 2) a latent regularization loss that minimizes intra-modality features (i.e., image and image) on the image manifold. By replacing the na\"ive directional CLIP loss in a drop-in replacement manner, our method achieves superior morphing results on both images and videos for various benchmarks, including CLIP-inversion.
ControlDreamer: Stylized 3D Generation with Multi-View ControlNet
Dec 02, 2023Recent advancements in text-to-3D generation have significantly contributed to the automation and democratization of 3D content creation. Building upon these developments, we aim to address the limitations of current methods in generating 3D models with creative geometry and styles. We introduce multi-view ControlNet, a novel depth-aware multi-view diffusion model trained on generated datasets from a carefully curated 100K text corpus. Our multi-view ControlNet is then integrated into our two-stage pipeline, ControlDreamer, enabling text-guided generation of stylized 3D models. Additionally, we present a comprehensive benchmark for 3D style editing, encompassing a broad range of subjects, including objects, animals, and characters, to further facilitate diverse 3D generation. Our comparative analysis reveals that this new pipeline outperforms existing text-to-3D methods as evidenced by qualitative comparisons and CLIP score metrics.