 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVoiceBench, KOpenAudioBench, and KMMAU: Agent-Driven Korean Speech Benchmarks for Evaluating SpeechLMs
May 27, 2026Speech language models (SpeechLMs) have achieved substantial progress by extending large language models (LLMs) to the speech modality. However, SpeechLM evaluation remains heavily centered on English, limiting reliable assessment of multilingual speech capabilities. Straightforward benchmark transfer through ASR, translation, normalization, and TTS can corrupt language-specific instructions, answer constraints, and spoken forms; for audio understanding, transferring source-language audio also fails to preserve target-language speaker attributes, accents, and paralinguistic properties. To address these limitations, we propose two human-agent benchmark-construction frameworks: one transfers source-language SpokenQA benchmarks into target-language SpokenQA benchmarks, and the other converts target-language ASR corpora into audio understanding benchmarks using transcriptions and speaker metadata. Using these frameworks, we construct and publicly release three Korean speech benchmarks: KVoiceBench and KOpenAudioBench for Korean SpokenQA, and KMMAU for Korean audio understanding, comprising 12,345 samples in total. We evaluate eight recent SpeechLMs and find that English-Korean performance gaps vary substantially across models and task families, and that SpokenQA and audio understanding rankings diverge, revealing complementary weaknesses invisible to English-only evaluation.
Looped Diffusion Language Models
May 25, 2026Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models for language modeling, yet the effective design of transformer architectures for MDMs remains underexplored. In this paper, we show that selectively looping the early-middle transformer layers significantly improves both training efficiency and model performance in MDMs. We call this approach LoopMDM(Looped Masked Diffusion Model), which brings two key benefits: looping layers at training-time yields a depth-scaling effect without adding parameters, while varying the number of loops at inference-time enables flexible compute scaling. Despite the simplicity, the results are striking: across multiple pre-training corpora, LoopMDM matches the performance of same-size MDMs with up to 3.3 fewer training FLOPs, while its final performance outperforms them on various reasoning benchmarks, including up to 8.5 points on GSM8K. It even surpasses deeper non-looped MDMs trained with comparable per-step compute, indicating that selective looping is more effective than naive depth scaling. Furthermore, LoopMDM can scale inference-time compute by increasing the number of loops. Adaptively adjusting the number of loops throughout the sampling process further yields additional gains in compute efficiency while maintaining performance. Lastly, with attention analysis, we provide evidence that looping is effective in MDMs by promoting interactions among masked positions. Our code and weights will be publicly released.
See and Fix the Flaws: Enabling VLMs and Diffusion Models to Comprehend Visual Artifacts via Agentic Data Synthesis
Feb 24, 2026Despite recent advances in diffusion models, AI generated images still often contain visual artifacts that compromise realism. Although more thorough pre-training and bigger models might reduce artifacts, there is no assurance that they can be completely eliminated, which makes artifact mitigation a highly crucial area of study. Previous artifact-aware methodologies depend on human-labeled artifact datasets, which are costly and difficult to scale, underscoring the need for an automated approach to reliably acquire artifact-annotated datasets. In this paper, we propose ArtiAgent, which efficiently creates pairs of real and artifact-injected images. It comprises three agents: a perception agent that recognizes and grounds entities and subentities from real images, a synthesis agent that introduces artifacts via artifact injection tools through novel patch-wise embedding manipulation within a diffusion transformer, and a curation agent that filters the synthesized artifacts and generates both local and global explanations for each instance. Using ArtiAgent, we synthesize 100K images with rich artifact annotations and demonstrate both efficacy and versatility across diverse applications. Code is available at link.
Exploring Multimodal Perception in Large Language Models Through Perceptual Strength Ratings
Mar 10, 2025This study investigated the multimodal perception of large language models (LLMs), focusing on their ability to capture human-like perceptual strength ratings across sensory modalities. Utilizing perceptual strength ratings as a benchmark, the research compared GPT-3.5, GPT-4, GPT-4o, and GPT-4o-mini, highlighting the influence of multimodal inputs on grounding and linguistic reasoning. While GPT-4 and GPT-4o demonstrated strong alignment with human evaluations and significant advancements over smaller models, qualitative analyses revealed distinct differences in processing patterns, such as multisensory overrating and reliance on loose semantic associations. Despite integrating multimodal capabilities, GPT-4o did not exhibit superior grounding compared to GPT-4, raising questions about their role in improving human-like grounding. These findings underscore how LLMs' reliance on linguistic patterns can both approximate and diverge from human embodied cognition, revealing limitations in replicating sensory experiences.
A Neural Operator-Based Emulator for Regional Shallow Water Dynamics
Feb 20, 2025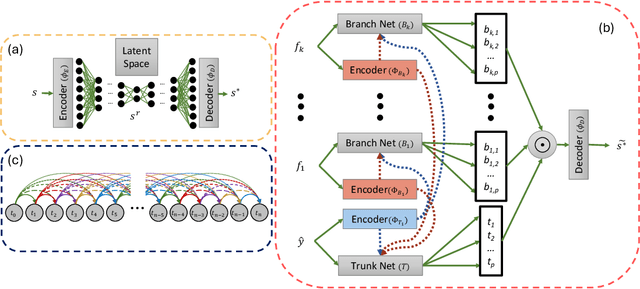

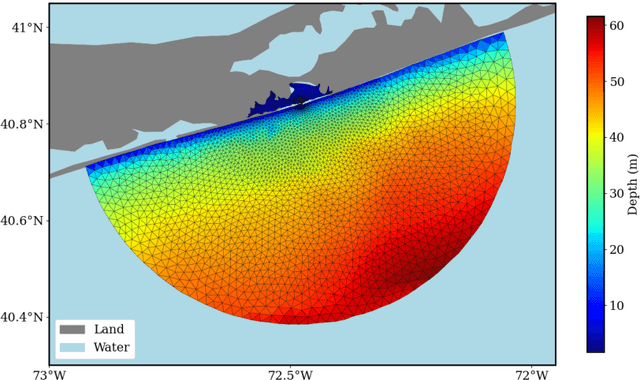
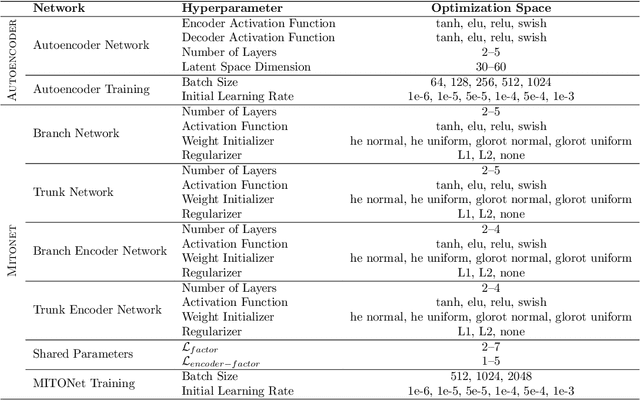
Coastal regions are particularly vulnerable to the impacts of rising sea levels and extreme weather events. Accurate real-time forecasting of hydrodynamic processes in these areas is essential for infrastructure planning and climate adaptation. In this study, we present the Multiple-Input Temporal Operator Network (MITONet), a novel autoregressive neural emulator that employs dimensionality reduction to efficiently approximate high-dimensional numerical solvers for complex, nonlinear problems that are governed by time-dependent, parameterized partial differential equations. Although MITONet is applicable to a wide range of problems, we showcase its capabilities by forecasting regional tide-driven dynamics described by the two-dimensional shallow-water equations, while incorporating initial conditions, boundary conditions, and a varying domain parameter. We demonstrate MITONet's performance in a real-world application, highlighting its ability to make accurate predictions by extrapolating both in time and parametric space.
Multi-fidelity Hamiltonian Monte Carlo
May 08, 2024


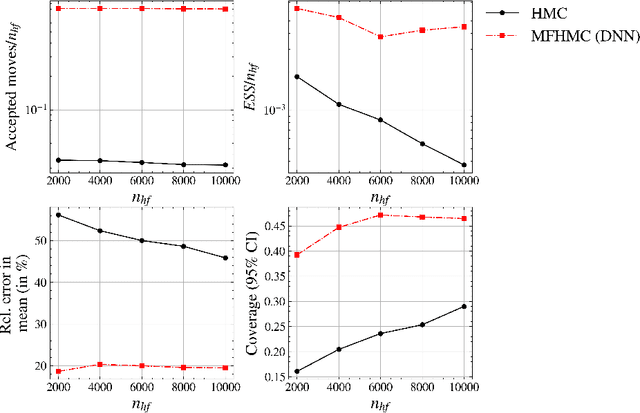
Numerous applications in biology, statistics, science, and engineering require generating samples from high-dimensional probability distributions. In recent years, the Hamiltonian Monte Carlo (HMC) method has emerged as a state-of-the-art Markov chain Monte Carlo technique, exploiting the shape of such high-dimensional target distributions to efficiently generate samples. Despite its impressive empirical success and increasing popularity, its wide-scale adoption remains limited due to the high computational cost of gradient calculation. Moreover, applying this method is impossible when the gradient of the posterior cannot be computed (for example, with black-box simulators). To overcome these challenges, we propose a novel two-stage Hamiltonian Monte Carlo algorithm with a surrogate model. In this multi-fidelity algorithm, the acceptance probability is computed in the first stage via a standard HMC proposal using an inexpensive differentiable surrogate model, and if the proposal is accepted, the posterior is evaluated in the second stage using the high-fidelity (HF) numerical solver. Splitting the standard HMC algorithm into these two stages allows for approximating the gradient of the posterior efficiently, while producing accurate posterior samples by using HF numerical solvers in the second stage. We demonstrate the effectiveness of this algorithm for a range of problems, including linear and nonlinear Bayesian inverse problems with in-silico data and experimental data. The proposed algorithm is shown to seamlessly integrate with various low-fidelity and HF models, priors, and datasets. Remarkably, our proposed method outperforms the traditional HMC algorithm in both computational and statistical efficiency by several orders of magnitude, all while retaining or improving the accuracy in computed posterior statistics.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Efficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024

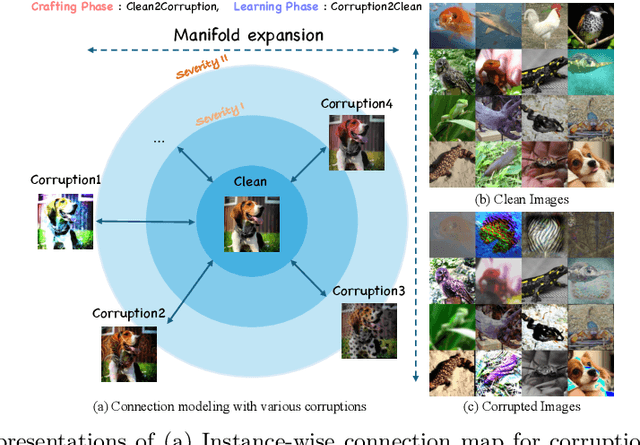

Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
SF$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation
Mar 16, 2024



In the face of the deep learning model's vulnerability to domain shift, source-free domain adaptation (SFDA) methods have been proposed to adapt models to new, unseen target domains without requiring access to source domain data. Although the potential benefits of applying data augmentation to SFDA are attractive, several challenges arise such as the dependence on prior knowledge of class-preserving transformations and the increase in memory and computational requirements. In this paper, we propose Source-free Domain Adaptation Through the Lens of Data Augmentation (SF(DA)$^2$), a novel approach that leverages the benefits of data augmentation without suffering from these challenges. We construct an augmentation graph in the feature space of the pretrained model using the neighbor relationships between target features and propose spectral neighborhood clustering to identify partitions in the prediction space. Furthermore, we propose implicit feature augmentation and feature disentanglement as regularization loss functions that effectively utilize class semantic information within the feature space. These regularizers simulate the inclusion of an unlimited number of augmented target features into the augmentation graph while minimizing computational and memory demands. Our method shows superior adaptation performance in SFDA scenarios, including 2D image and 3D point cloud datasets and a highly imbalanced dataset.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024



Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.