 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust Hyper-Detailed Image Captioning: A Multiagent Approach and Dual Evaluation Metrics for Factuality and Coverage
Dec 24, 2024Multimodal large language models (MLLMs) excel at generating highly detailed captions but often produce hallucinations. Our analysis reveals that existing hallucination detection methods struggle with detailed captions. We attribute this to the increasing reliance of MLLMs on their generated text, rather than the input image, as the sequence length grows. To address this issue, we propose a multiagent approach that leverages LLM-MLLM collaboration to correct given captions. Additionally, we introduce an evaluation framework and a benchmark dataset to facilitate the systematic analysis of detailed captions. Our experiments demonstrate that our proposed evaluation method better aligns with human judgments of factuality than existing metrics and that existing approaches to improve the MLLM factuality may fall short in hyper-detailed image captioning tasks. In contrast, our proposed method significantly enhances the factual accuracy of captions, even improving those generated by GPT-4V. Finally, we highlight a limitation of VQA-centric benchmarking by demonstrating that an MLLM's performance on VQA benchmarks may not correlate with its ability to generate detailed image captions.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Unleashing Multi-Hop Reasoning Potential in Large Language Models through Repetition of Misordered Context
Oct 09, 2024



Multi-hop reasoning, which requires multi-step reasoning based on the supporting documents within a given context, remains challenging for large language models (LLMs). LLMs often struggle to filter out irrelevant documents within the context, and their performance is sensitive to the position of supporting documents within that context. In this paper, we identify an additional challenge: LLMs' performance is also sensitive to the order in which the supporting documents are presented. We refer to this as the misordered context problem. To address this issue, we propose a simple yet effective method called context repetition (CoRe), which involves prompting the model by repeatedly presenting the context to ensure the supporting documents are presented in the optimal order for the model. Using CoRe, we improve the F1 score by up to 30%p on multi-hop QA tasks and increase accuracy by up to 70%p on a synthetic task. Additionally, CoRe helps mitigate the well-known "lost-in-the-middle" problem in LLMs and can be effectively combined with retrieval-based approaches utilizing Chain-of-Thought (CoT) reasoning.
Textual Training for the Hassle-Free Removal of Unwanted Visual Data
Sep 30, 2024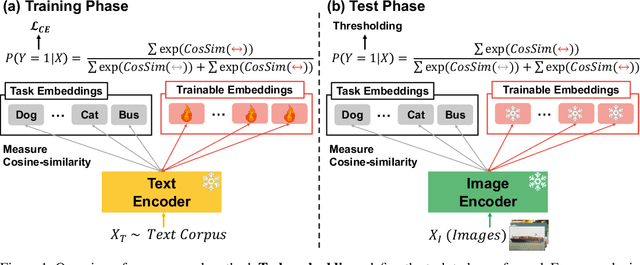
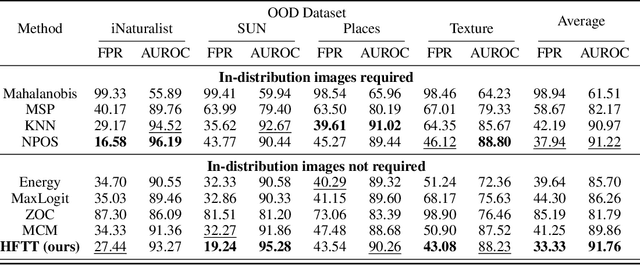
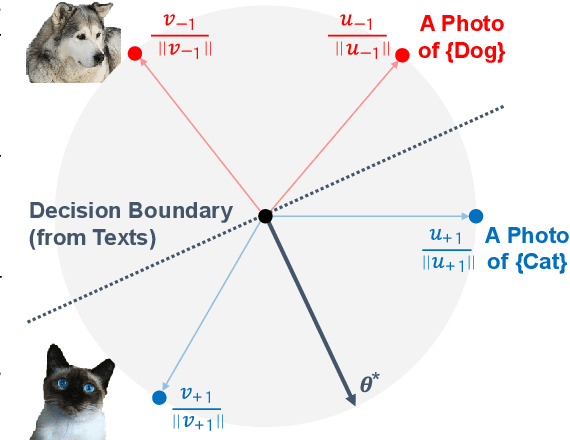
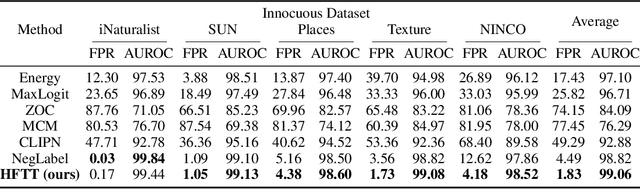
In our study, we explore methods for detecting unwanted content lurking in visual datasets. We provide a theoretical analysis demonstrating that a model capable of successfully partitioning visual data can be obtained using only textual data. Based on the analysis, we propose Hassle-Free Textual Training (HFTT), a streamlined method capable of acquiring detectors for unwanted visual content, using only synthetic textual data in conjunction with pre-trained vision-language models. HFTT features an innovative objective function that significantly reduces the necessity for human involvement in data annotation. Furthermore, HFTT employs a clever textual data synthesis method, effectively emulating the integration of unknown visual data distribution into the training process at no extra cost. The unique characteristics of HFTT extend its utility beyond traditional out-of-distribution detection, making it applicable to tasks that address more abstract concepts. We complement our analyses with experiments in out-of-distribution detection and hateful image detection. Our codes are available at https://github.com/Saehyung-Lee/HFTT
Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
Jun 05, 2024
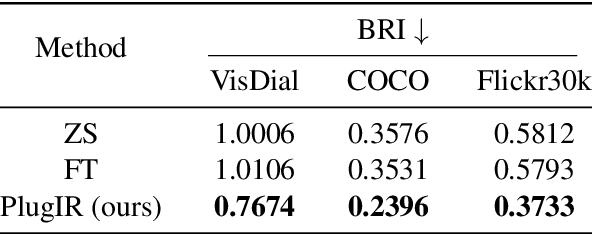
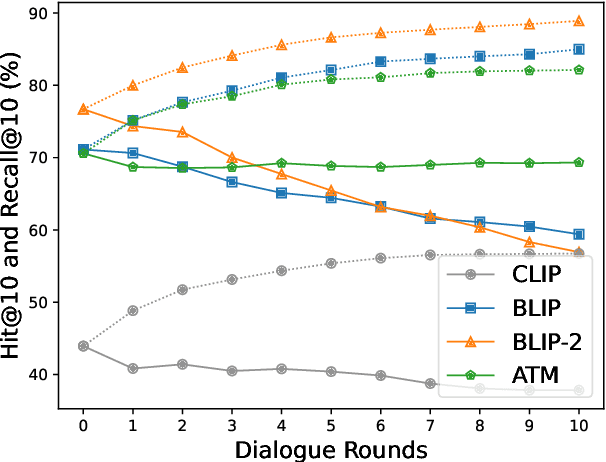

In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024



Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.
Gradient Alignment with Prototype Feature for Fully Test-time Adaptation
Feb 14, 2024



In context of Test-time Adaptation(TTA), we propose a regularizer, dubbed Gradient Alignment with Prototype feature (GAP), which alleviates the inappropriate guidance from entropy minimization loss from misclassified pseudo label. We developed a gradient alignment loss to precisely manage the adaptation process, ensuring that changes made for some data don't negatively impact the model's performance on other data. We introduce a prototype feature of a class as a proxy measure of the negative impact. To make GAP regularizer feasible under the TTA constraints, where model can only access test data without labels, we tailored its formula in two ways: approximating prototype features with weight vectors of the classifier, calculating gradient without back-propagation. We demonstrate GAP significantly improves TTA methods across various datasets, which proves its versatility and effectiveness.
DAFA: Distance-Aware Fair Adversarial Training
Jan 23, 2024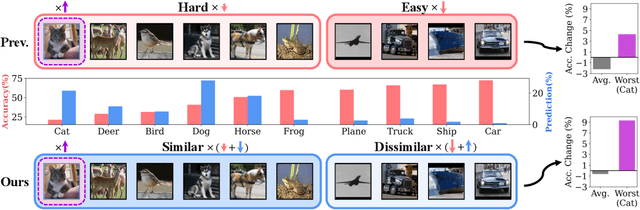
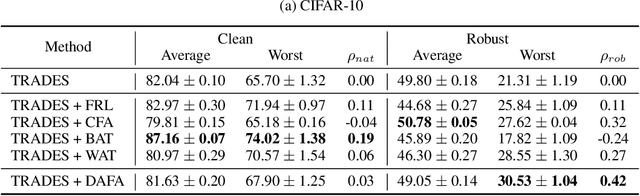
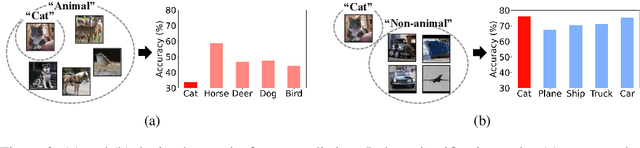
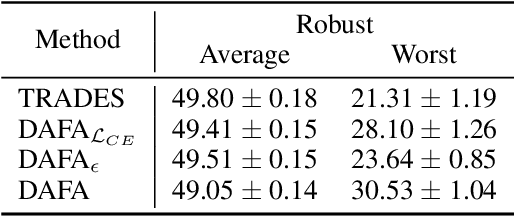
The disparity in accuracy between classes in standard training is amplified during adversarial training, a phenomenon termed the robust fairness problem. Existing methodologies aimed to enhance robust fairness by sacrificing the model's performance on easier classes in order to improve its performance on harder ones. However, we observe that under adversarial attacks, the majority of the model's predictions for samples from the worst class are biased towards classes similar to the worst class, rather than towards the easy classes. Through theoretical and empirical analysis, we demonstrate that robust fairness deteriorates as the distance between classes decreases. Motivated by these insights, we introduce the Distance-Aware Fair Adversarial training (DAFA) methodology, which addresses robust fairness by taking into account the similarities between classes. Specifically, our method assigns distinct loss weights and adversarial margins to each class and adjusts them to encourage a trade-off in robustness among similar classes. Experimental results across various datasets demonstrate that our method not only maintains average robust accuracy but also significantly improves the worst robust accuracy, indicating a marked improvement in robust fairness compared to existing methods.
On mitigating stability-plasticity dilemma in CLIP-guided image morphing via geodesic distillation loss
Jan 19, 2024Large-scale language-vision pre-training models, such as CLIP, have achieved remarkable text-guided image morphing results by leveraging several unconditional generative models. However, existing CLIP-guided image morphing methods encounter difficulties when morphing photorealistic images. Specifically, existing guidance fails to provide detailed explanations of the morphing regions within the image, leading to misguidance. In this paper, we observed that such misguidance could be effectively mitigated by simply using a proper regularization loss. Our approach comprises two key components: 1) a geodesic cosine similarity loss that minimizes inter-modality features (i.e., image and text) on a projected subspace of CLIP space, and 2) a latent regularization loss that minimizes intra-modality features (i.e., image and image) on the image manifold. By replacing the na\"ive directional CLIP loss in a drop-in replacement manner, our method achieves superior morphing results on both images and videos for various benchmarks, including CLIP-inversion.
On the Powerfulness of Textual Outlier Exposure for Visual OoD Detection
Oct 25, 2023Successful detection of Out-of-Distribution (OoD) data is becoming increasingly important to ensure safe deployment of neural networks. One of the main challenges in OoD detection is that neural networks output overconfident predictions on OoD data, make it difficult to determine OoD-ness of data solely based on their predictions. Outlier exposure addresses this issue by introducing an additional loss that encourages low-confidence predictions on OoD data during training. While outlier exposure has shown promising potential in improving OoD detection performance, all previous studies on outlier exposure have been limited to utilizing visual outliers. Drawing inspiration from the recent advancements in vision-language pre-training, this paper venture out to the uncharted territory of textual outlier exposure. First, we uncover the benefits of using textual outliers by replacing real or virtual outliers in the image-domain with textual equivalents. Then, we propose various ways of generating preferable textual outliers. Our extensive experiments demonstrate that generated textual outliers achieve competitive performance on large-scale OoD and hard OoD benchmarks. Furthermore, we conduct empirical analyses of textual outliers to provide primary criteria for designing advantageous textual outliers: near-distribution, descriptiveness, and inclusion of visual semantics.