 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDrop: Layer-wise Token Pruning for Omni-modal LLMs via Query-Guidance
May 14, 2026Omni-modal large language models have demonstrated remarkable potential in holistic multimodal understanding; however, the token explosion caused by high-resolution audio and video inputs remains a critical bottleneck for real-time applications and long-form reasoning. Existing omni-modal token compression methods typically prune tokens at the input embedding level, relying on audio-video similarity or temporal co-occurrence as proxies for semantic relevance. In practice, such assumptions are often unreliable. To address this limitation, we propose OmniDrop, a training-free, layer-wise token pruning framework that progressively prunes audiovisual tokens within the LLM decoder layers rather than at the input-level, allowing early layers to preserve sufficient omni-modal information fusion before aggressively removing tokens in deeper layers. We further utilize text queries as guidance for modality-agnostic and task-adaptive token pruning. We also introduce a temporal diversity score that encourages balanced token survival to preserve global temporal context. Experimental results across various audiovisual benchmarks demonstrate that OmniDrop outperforms all baselines by up to 3.58 points while reducing prefill latency by up to 40% and memory usage by up to 14.7%.
LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
Mar 11, 2026Transformer-based large language models (LLMs) rely on key-value (KV) caching to avoid redundant computation during autoregressive inference. While this mechanism greatly improves efficiency, the cache size grows linearly with the input sequence length, quickly becoming a bottleneck for long-context tasks. Existing solutions mitigate this problem by evicting prompt KV that are deemed unimportant, guided by estimated importance scores. Notably, a recent line of work proposes to improve eviction quality by "glimpsing into the future", in which a draft generator produces a surrogate future response approximating the target model's true response, and this surrogate is subsequently used to estimate the importance of cached KV more accurately. However, these approaches rely on computationally expensive draft generation, which introduces substantial prefilling overhead and limits their practicality in real-world deployment. To address this challenge, we propose LookaheadKV, a lightweight eviction framework that leverages the strength of surrogate future response without requiring explicit draft generation. LookaheadKV augments transformer layers with parameter-efficient modules trained to predict true importance scores with high accuracy. Our design ensures negligible runtime overhead comparable to existing inexpensive heuristics, while achieving accuracy superior to more costly approximation methods. Extensive experiments on long-context understanding benchmarks, across a wide range of models, demonstrate that our method not only outperforms recent competitive baselines in various long-context understanding tasks, but also reduces the eviction cost by up to 14.5x, leading to significantly faster time-to-first-token. Our code is available at https://github.com/SamsungLabs/LookaheadKV.
On the Importance of a Multi-Scale Calibration for Quantization
Feb 07, 2026Post-training quantization (PTQ) is a cornerstone for efficiently deploying large language models (LLMs), where a small calibration set critically affects quantization performance. However, conventional practices rely on random sequences of fixed length, overlooking the variable-length nature of LLM inputs. Input length directly influences the activation distribution and, consequently, the weight importance captured by the Hessian, which in turn affects quantization outcomes. As a result, Hessian estimates derived from fixed-length calibration may fail to represent the true importance of weights across diverse input scenarios. We propose MaCa (Matryoshka Calibration), a simple yet effective method for length-aware Hessian construction. MaCa (i) incorporates multi-scale sequence length information into Hessian estimation and (ii) regularizes each sequence as an independent sample, yielding a more stable and fruitful Hessian for accurate quantization. Experiments on state-of-the-art LLMs (e.g., Qwen3, Gemma3, LLaMA3) demonstrate that MaCa consistently improves accuracy under low bit quantization, offering a lightweight enhancement compatible with existing PTQ frameworks. To the best of our knowledge, this is the first work to systematically highlight the role of multi-scale calibration in LLM quantization.
Unsupervised Homography Estimation on Multimodal Image Pair via Alternating Optimization
Nov 20, 2024


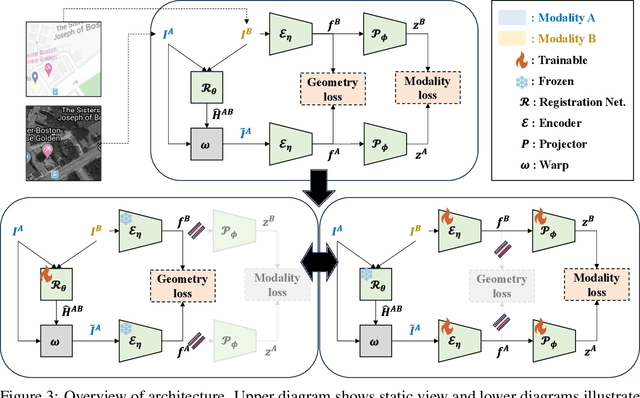
Estimating the homography between two images is crucial for mid- or high-level vision tasks, such as image stitching and fusion. However, using supervised learning methods is often challenging or costly due to the difficulty of collecting ground-truth data. In response, unsupervised learning approaches have emerged. Most early methods, though, assume that the given image pairs are from the same camera or have minor lighting differences. Consequently, while these methods perform effectively under such conditions, they generally fail when input image pairs come from different domains, referred to as multimodal image pairs. To address these limitations, we propose AltO, an unsupervised learning framework for estimating homography in multimodal image pairs. Our method employs a two-phase alternating optimization framework, similar to Expectation-Maximization (EM), where one phase reduces the geometry gap and the other addresses the modality gap. To handle these gaps, we use Barlow Twins loss for the modality gap and propose an extended version, Geometry Barlow Twins, for the geometry gap. As a result, we demonstrate that our method, AltO, can be trained on multimodal datasets without any ground-truth data. It not only outperforms other unsupervised methods but is also compatible with various architectures of homography estimators. The source code can be found at:~\url{https://github.com/songsang7/AltO}
DAFA: Distance-Aware Fair Adversarial Training
Jan 23, 2024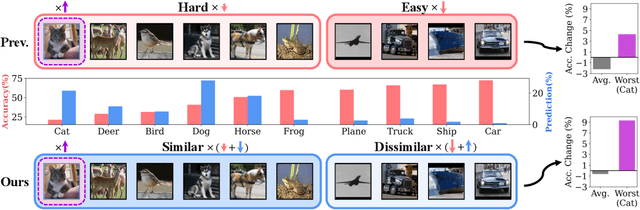
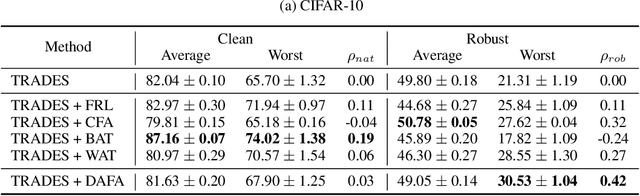
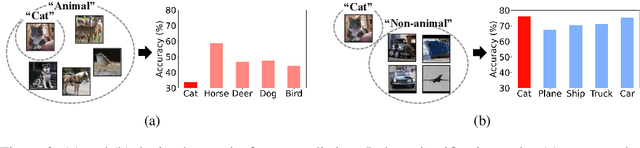
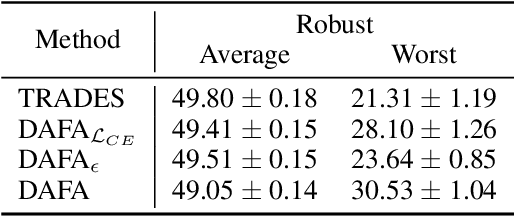
The disparity in accuracy between classes in standard training is amplified during adversarial training, a phenomenon termed the robust fairness problem. Existing methodologies aimed to enhance robust fairness by sacrificing the model's performance on easier classes in order to improve its performance on harder ones. However, we observe that under adversarial attacks, the majority of the model's predictions for samples from the worst class are biased towards classes similar to the worst class, rather than towards the easy classes. Through theoretical and empirical analysis, we demonstrate that robust fairness deteriorates as the distance between classes decreases. Motivated by these insights, we introduce the Distance-Aware Fair Adversarial training (DAFA) methodology, which addresses robust fairness by taking into account the similarities between classes. Specifically, our method assigns distinct loss weights and adversarial margins to each class and adjusts them to encourage a trade-off in robustness among similar classes. Experimental results across various datasets demonstrate that our method not only maintains average robust accuracy but also significantly improves the worst robust accuracy, indicating a marked improvement in robust fairness compared to existing methods.
PUCA: Patch-Unshuffle and Channel Attention for Enhanced Self-Supervised Image Denoising
Oct 16, 2023


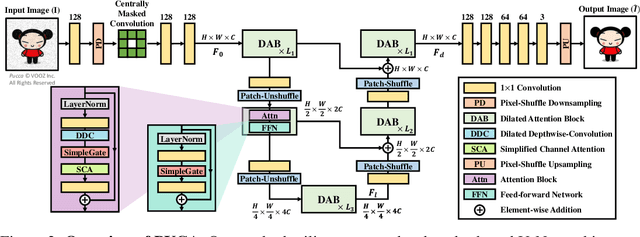
Although supervised image denoising networks have shown remarkable performance on synthesized noisy images, they often fail in practice due to the difference between real and synthesized noise. Since clean-noisy image pairs from the real world are extremely costly to gather, self-supervised learning, which utilizes noisy input itself as a target, has been studied. To prevent a self-supervised denoising model from learning identical mapping, each output pixel should not be influenced by its corresponding input pixel; This requirement is known as J-invariance. Blind-spot networks (BSNs) have been a prevalent choice to ensure J-invariance in self-supervised image denoising. However, constructing variations of BSNs by injecting additional operations such as downsampling can expose blinded information, thereby violating J-invariance. Consequently, convolutions designed specifically for BSNs have been allowed only, limiting architectural flexibility. To overcome this limitation, we propose PUCA, a novel J-invariant U-Net architecture, for self-supervised denoising. PUCA leverages patch-unshuffle/shuffle to dramatically expand receptive fields while maintaining J-invariance and dilated attention blocks (DABs) for global context incorporation. Experimental results demonstrate that PUCA achieves state-of-the-art performance, outperforming existing methods in self-supervised image denoising.
New Insights for the Stability-Plasticity Dilemma in Online Continual Learning
Feb 17, 2023The aim of continual learning is to learn new tasks continuously (i.e., plasticity) without forgetting previously learned knowledge from old tasks (i.e., stability). In the scenario of online continual learning, wherein data comes strictly in a streaming manner, the plasticity of online continual learning is more vulnerable than offline continual learning because the training signal that can be obtained from a single data point is limited. To overcome the stability-plasticity dilemma in online continual learning, we propose an online continual learning framework named multi-scale feature adaptation network (MuFAN) that utilizes a richer context encoding extracted from different levels of a pre-trained network. Additionally, we introduce a novel structure-wise distillation loss and replace the commonly used batch normalization layer with a newly proposed stability-plasticity normalization module to train MuFAN that simultaneously maintains high plasticity and stability. MuFAN outperforms other state-of-the-art continual learning methods on the SVHN, CIFAR100, miniImageNet, and CORe50 datasets. Extensive experiments and ablation studies validate the significance and scalability of each proposed component: 1) multi-scale feature maps from a pre-trained encoder, 2) the structure-wise distillation loss, and 3) the stability-plasticity normalization module in MuFAN. Code is publicly available at https://github.com/whitesnowdrop/MuFAN.
Stein Latent Optimization for GANs
Jun 09, 2021
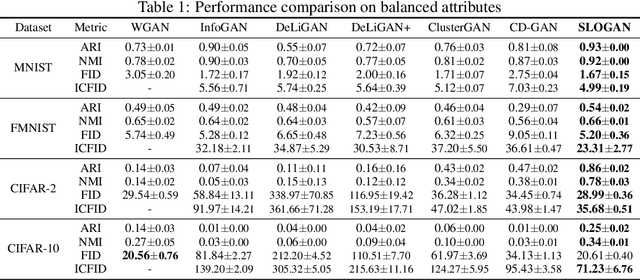
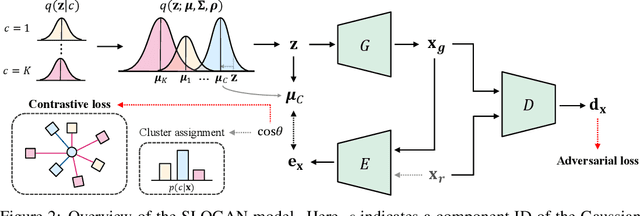
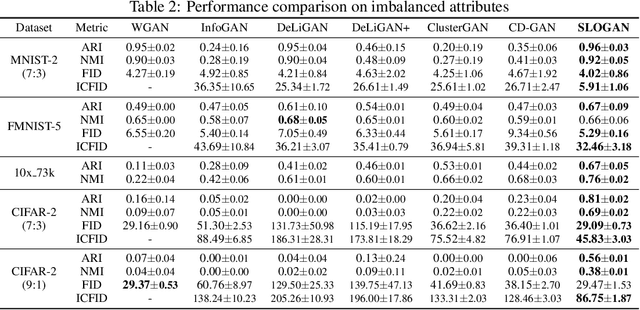
Generative adversarial networks (GANs) with clustered latent spaces can perform conditional generation in a completely unsupervised manner. However, the salient attributes of unlabeled data in the real-world are mostly imbalanced. Existing unsupervised conditional GANs cannot properly cluster the attributes in their latent spaces because they assume uniform distributions of the attributes. To address this problem, we theoretically derive Stein latent optimization that provides reparameterizable gradient estimations of the latent distribution parameters assuming a Gaussian mixture prior in a continuous latent space. Structurally, we introduce an encoder network and a novel contrastive loss to help generated data from a single mixture component to represent a single attribute. We confirm that the proposed method, named Stein Latent Optimization for GANs (SLOGAN), successfully learns the balanced or imbalanced attributes and performs unsupervised tasks such as unsupervised conditional generation, unconditional generation, and cluster assignment even in the absence of information of the attributes (e.g. the imbalance ratio). Moreover, we demonstrate that the attributes to be learned can be manipulated using a small amount of probe data.
PuVAE: A Variational Autoencoder to Purify Adversarial Examples
Mar 02, 2019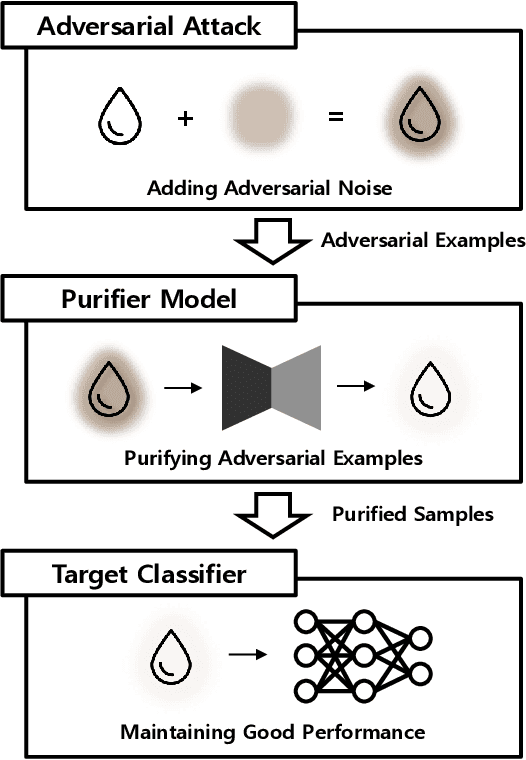

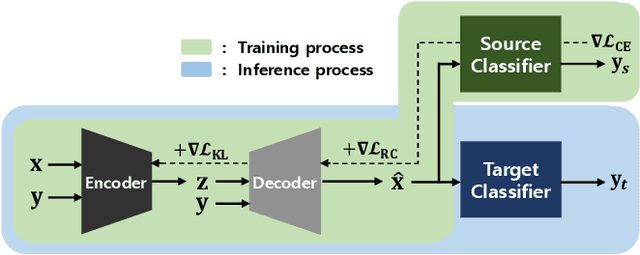
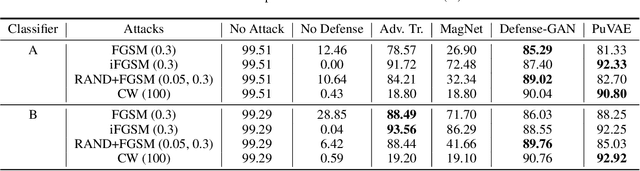
Deep neural networks are widely used and exhibit excellent performance in many areas. However, they are vulnerable to adversarial attacks that compromise the network at the inference time by applying elaborately designed perturbation to input data. Although several defense methods have been proposed to address specific attacks, other attack methods can circumvent these defense mechanisms. Therefore, we propose Purifying Variational Autoencoder (PuVAE), a method to purify adversarial examples. The proposed method eliminates an adversarial perturbation by projecting an adversarial example on the manifold of each class, and determines the closest projection as a purified sample. We experimentally illustrate the robustness of PuVAE against various attack methods without any prior knowledge. In our experiments, the proposed method exhibits performances competitive with state-of-the-art defense methods, and the inference time is approximately 130 times faster than that of Defense-GAN that is the state-of-the art purifier model.
Security and Privacy Issues in Deep Learning
Jul 31, 2018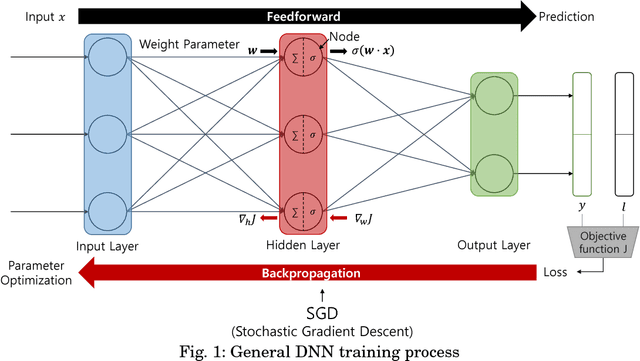
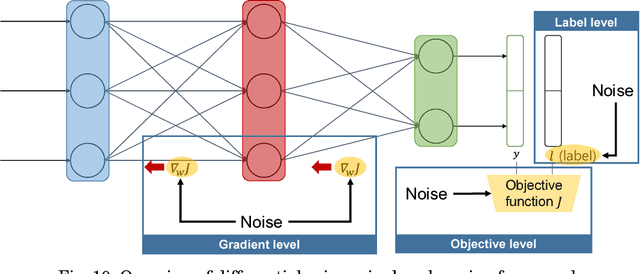
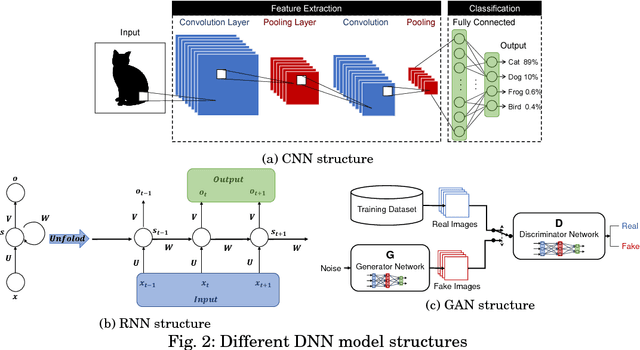
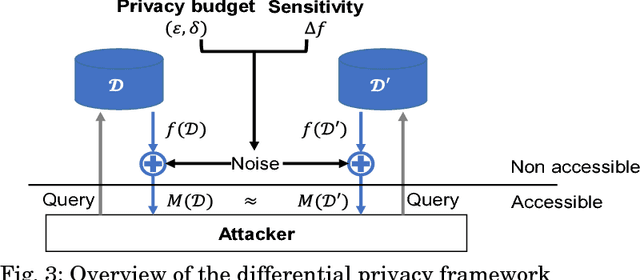
With the development of machine learning, expectations for artificial intelligence (AI) technology are increasing day by day. In particular, deep learning has shown enriched performance results in a variety of fields. There are many applications that are closely related to our daily life, such as making significant decisions in application area based on predictions or classifications, in which a deep learning (DL) model could be relevant. Hence, if a DL model causes mispredictions or misclassifications due to malicious external influences, it can cause very large difficulties in real life. Moreover, training deep learning models involves relying on an enormous amount of data and the training data often includes sensitive information. Therefore, deep learning models should not expose the privacy of such data. In this paper, we reviewed the threats and developed defense methods on the security of the models and the data privacy under the notion of SPAI: Secure and Private AI. We also discuss current challenges and open issues.