 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuVAE: A Variational Autoencoder to Purify Adversarial Examples
Paper and Code
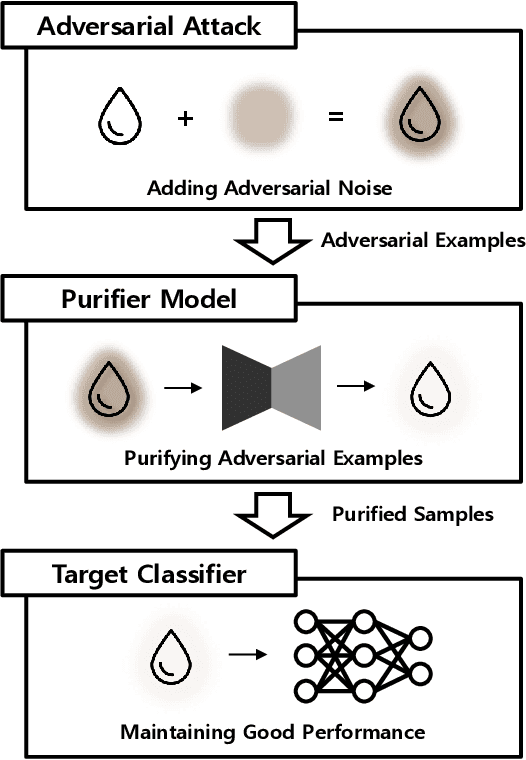

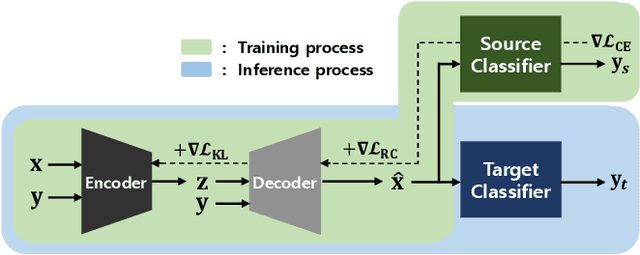
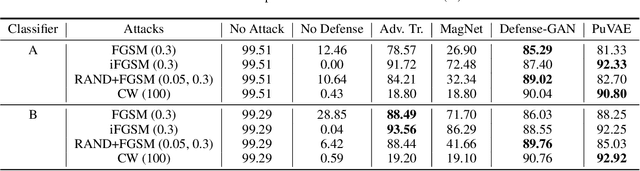
Deep neural networks are widely used and exhibit excellent performance in many areas. However, they are vulnerable to adversarial attacks that compromise the network at the inference time by applying elaborately designed perturbation to input data. Although several defense methods have been proposed to address specific attacks, other attack methods can circumvent these defense mechanisms. Therefore, we propose Purifying Variational Autoencoder (PuVAE), a method to purify adversarial examples. The proposed method eliminates an adversarial perturbation by projecting an adversarial example on the manifold of each class, and determines the closest projection as a purified sample. We experimentally illustrate the robustness of PuVAE against various attack methods without any prior knowledge. In our experiments, the proposed method exhibits performances competitive with state-of-the-art defense methods, and the inference time is approximately 130 times faster than that of Defense-GAN that is the state-of-the art purifier model.