 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024

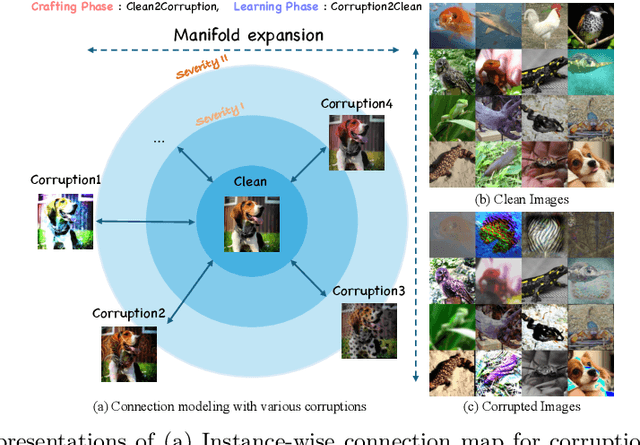

Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
SF$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation
Mar 16, 2024



In the face of the deep learning model's vulnerability to domain shift, source-free domain adaptation (SFDA) methods have been proposed to adapt models to new, unseen target domains without requiring access to source domain data. Although the potential benefits of applying data augmentation to SFDA are attractive, several challenges arise such as the dependence on prior knowledge of class-preserving transformations and the increase in memory and computational requirements. In this paper, we propose Source-free Domain Adaptation Through the Lens of Data Augmentation (SF(DA)$^2$), a novel approach that leverages the benefits of data augmentation without suffering from these challenges. We construct an augmentation graph in the feature space of the pretrained model using the neighbor relationships between target features and propose spectral neighborhood clustering to identify partitions in the prediction space. Furthermore, we propose implicit feature augmentation and feature disentanglement as regularization loss functions that effectively utilize class semantic information within the feature space. These regularizers simulate the inclusion of an unlimited number of augmented target features into the augmentation graph while minimizing computational and memory demands. Our method shows superior adaptation performance in SFDA scenarios, including 2D image and 3D point cloud datasets and a highly imbalanced dataset.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.
Improving Diffusion-Based Generative Models via Approximated Optimal Transport
Mar 08, 2024



We introduce the Approximated Optimal Transport (AOT) technique, a novel training scheme for diffusion-based generative models. Our approach aims to approximate and integrate optimal transport into the training process, significantly enhancing the ability of diffusion models to estimate the denoiser outputs accurately. This improvement leads to ODE trajectories of diffusion models with lower curvature and reduced truncation errors during sampling. We achieve superior image quality and reduced sampling steps by employing AOT in training. Specifically, we achieve FID scores of 1.88 with just 27 NFEs and 1.73 with 29 NFEs in unconditional and conditional generations, respectively. Furthermore, when applying AOT to train the discriminator for guidance, we establish new state-of-the-art FID scores of 1.68 and 1.58 for unconditional and conditional generations, respectively, each with 29 NFEs. This outcome demonstrates the effectiveness of AOT in enhancing the performance of diffusion models.
Gradient Alignment with Prototype Feature for Fully Test-time Adaptation
Feb 14, 2024



In context of Test-time Adaptation(TTA), we propose a regularizer, dubbed Gradient Alignment with Prototype feature (GAP), which alleviates the inappropriate guidance from entropy minimization loss from misclassified pseudo label. We developed a gradient alignment loss to precisely manage the adaptation process, ensuring that changes made for some data don't negatively impact the model's performance on other data. We introduce a prototype feature of a class as a proxy measure of the negative impact. To make GAP regularizer feasible under the TTA constraints, where model can only access test data without labels, we tailored its formula in two ways: approximating prototype features with weight vectors of the classifier, calculating gradient without back-propagation. We demonstrate GAP significantly improves TTA methods across various datasets, which proves its versatility and effectiveness.
On mitigating stability-plasticity dilemma in CLIP-guided image morphing via geodesic distillation loss
Jan 19, 2024Large-scale language-vision pre-training models, such as CLIP, have achieved remarkable text-guided image morphing results by leveraging several unconditional generative models. However, existing CLIP-guided image morphing methods encounter difficulties when morphing photorealistic images. Specifically, existing guidance fails to provide detailed explanations of the morphing regions within the image, leading to misguidance. In this paper, we observed that such misguidance could be effectively mitigated by simply using a proper regularization loss. Our approach comprises two key components: 1) a geodesic cosine similarity loss that minimizes inter-modality features (i.e., image and text) on a projected subspace of CLIP space, and 2) a latent regularization loss that minimizes intra-modality features (i.e., image and image) on the image manifold. By replacing the na\"ive directional CLIP loss in a drop-in replacement manner, our method achieves superior morphing results on both images and videos for various benchmarks, including CLIP-inversion.
Stein Latent Optimization for GANs
Jun 09, 2021
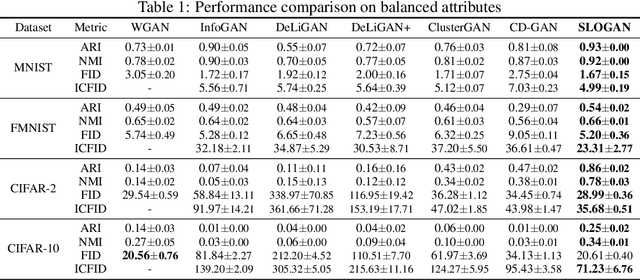
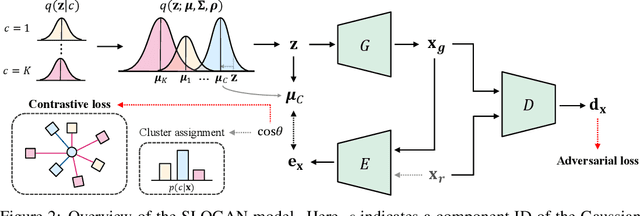
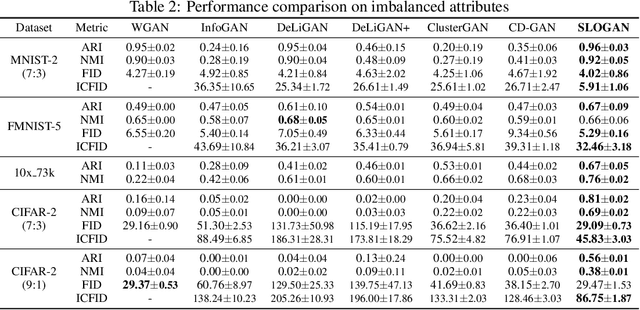
Generative adversarial networks (GANs) with clustered latent spaces can perform conditional generation in a completely unsupervised manner. However, the salient attributes of unlabeled data in the real-world are mostly imbalanced. Existing unsupervised conditional GANs cannot properly cluster the attributes in their latent spaces because they assume uniform distributions of the attributes. To address this problem, we theoretically derive Stein latent optimization that provides reparameterizable gradient estimations of the latent distribution parameters assuming a Gaussian mixture prior in a continuous latent space. Structurally, we introduce an encoder network and a novel contrastive loss to help generated data from a single mixture component to represent a single attribute. We confirm that the proposed method, named Stein Latent Optimization for GANs (SLOGAN), successfully learns the balanced or imbalanced attributes and performs unsupervised tasks such as unsupervised conditional generation, unconditional generation, and cluster assignment even in the absence of information of the attributes (e.g. the imbalance ratio). Moreover, we demonstrate that the attributes to be learned can be manipulated using a small amount of probe data.
PuVAE: A Variational Autoencoder to Purify Adversarial Examples
Mar 02, 2019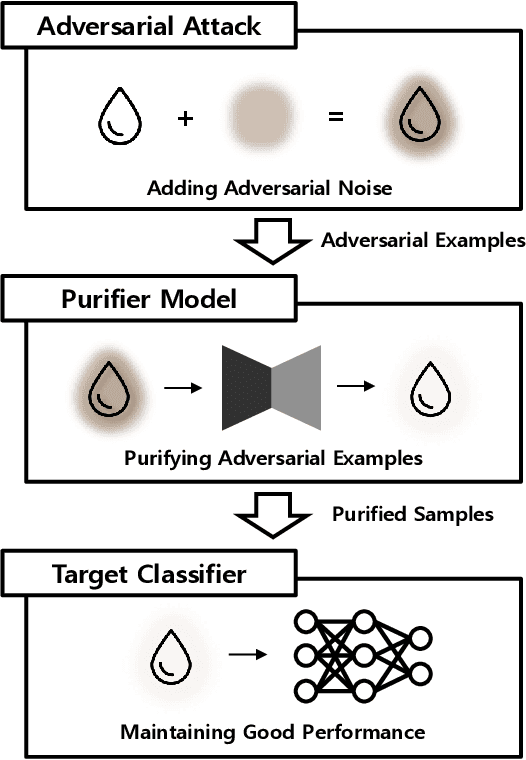

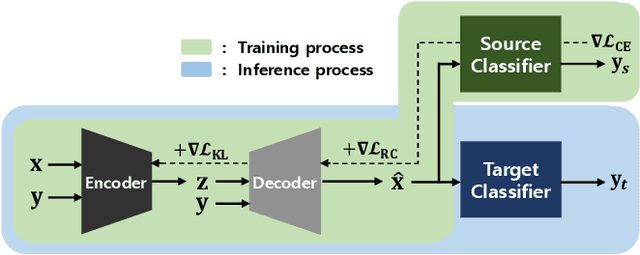
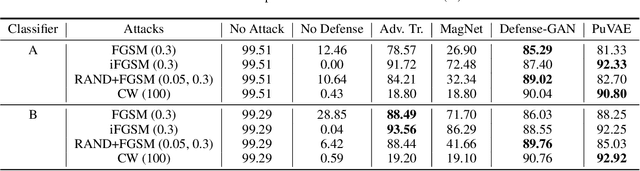
Deep neural networks are widely used and exhibit excellent performance in many areas. However, they are vulnerable to adversarial attacks that compromise the network at the inference time by applying elaborately designed perturbation to input data. Although several defense methods have been proposed to address specific attacks, other attack methods can circumvent these defense mechanisms. Therefore, we propose Purifying Variational Autoencoder (PuVAE), a method to purify adversarial examples. The proposed method eliminates an adversarial perturbation by projecting an adversarial example on the manifold of each class, and determines the closest projection as a purified sample. We experimentally illustrate the robustness of PuVAE against various attack methods without any prior knowledge. In our experiments, the proposed method exhibits performances competitive with state-of-the-art defense methods, and the inference time is approximately 130 times faster than that of Defense-GAN that is the state-of-the art purifier model.
HexaGAN: Generative Adversarial Nets for Real World Classification
Feb 26, 2019
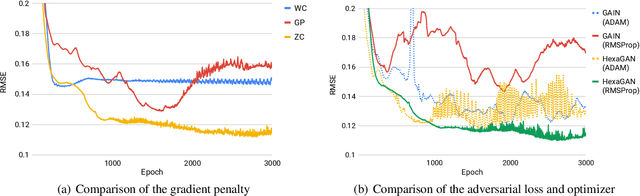
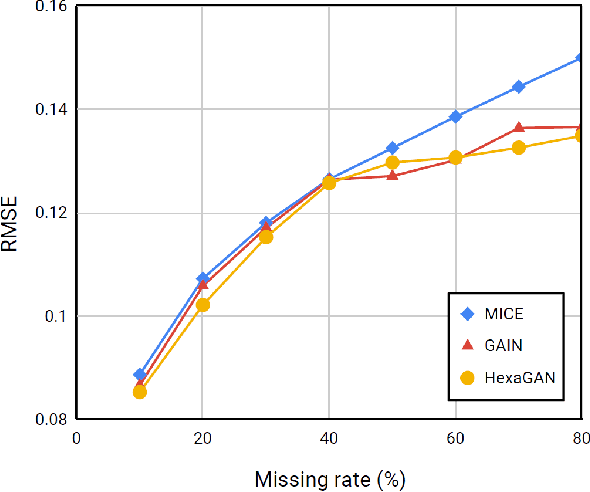
Most deep learning classification studies assume clean data. However, dirty data is prevalent in real world, and this undermines the classification performance. The data we practically encounter has problems such as 1) missing data, 2) class imbalance, and 3) missing label. Preprocessing techniques assume one of these problems and mitigate it, but an algorithm that assumes all three problems and resolves them has not yet been proposed. Therefore, in this paper, we propose HexaGAN, a generative adversarial network (GAN) framework that shows good classification performance for all three problems. We interpret the three problems from a similar perspective to solve them jointly. To enable this, the framework consists of six components, which interact in an end-to-end manner. We also devise novel loss functions corresponding to the architecture. The designed loss functions achieve state-of-the-art imputation performance with up to a 14% improvement and high-quality class-conditional data. We evaluate the classification performance (F1-score) of the proposed method with 20% missingness and confirm up to a 5% improvement in comparison with the combinations of state-of-the-art methods.
Memory-Augmented Neural Networks for Knowledge Tracing from the Perspective of Learning and Forgetting
Oct 01, 2018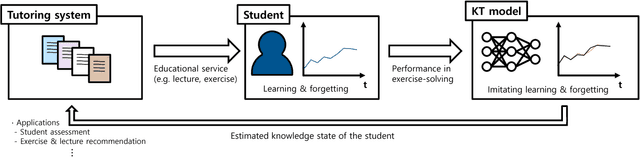



Knowledge tracing (KT) refers to a machine learning technique to assess a student's level of understanding (or knowledge state) based on the student's past performance in exercise-solving. KT accepts a series of question-answer pairs as an input and iteratively updates the knowledge state of the student, eventually returning the probability of the student solving a given question. To estimate the accurate knowledge state, a KT model should imitate the learning and forgetting mechanisms of the student. Deep learning-based KT models, proposed recently, show a higher predictive performance than traditional machine learning-based KT models due to the representative power of neural networks. The dynamic key value memory network (DKVMN), a kind of memory augmented neural network (MANN), is a state-of-the-art KT model, but it has some limitations. DKVMN does not utilize information from a current knowledge state and overestimates the amount of forgetting when updating the knowledge state. To improve the learning and forgetting mechanism of the DKVMN, we propose a knowledge tracing model that incorporates: (1) an adaptive knowledge growth depending on the current knowledge state, and (2) an additional loss term that can regularize the degree of forgetting. To measure the degree of forgetting of the KT model, we define a positive update ratio (PUR) that can complement the predictive performance metric (AUC). According to our experiments using four public benchmarks, the proposed approaches outperform the original DKVMN in terms of both AUC (predictive performance) and PUR (degree of forgetting).