 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedClassAvg: Local Representation Learning for Personalized Federated Learning on Heterogeneous Neural Networks
Oct 27, 2022



Personalized federated learning is aimed at allowing numerous clients to train personalized models while participating in collaborative training in a communication-efficient manner without exchanging private data. However, many personalized federated learning algorithms assume that clients have the same neural network architecture, and those for heterogeneous models remain understudied. In this study, we propose a novel personalized federated learning method called federated classifier averaging (FedClassAvg). Deep neural networks for supervised learning tasks consist of feature extractor and classifier layers. FedClassAvg aggregates classifier weights as an agreement on decision boundaries on feature spaces so that clients with not independently and identically distributed (non-iid) data can learn about scarce labels. In addition, local feature representation learning is applied to stabilize the decision boundaries and improve the local feature extraction capabilities for clients. While the existing methods require the collection of auxiliary data or model weights to generate a counterpart, FedClassAvg only requires clients to communicate with a couple of fully connected layers, which is highly communication-efficient. Moreover, FedClassAvg does not require extra optimization problems such as knowledge transfer, which requires intensive computation overhead. We evaluated FedClassAvg through extensive experiments and demonstrated it outperforms the current state-of-the-art algorithms on heterogeneous personalized federated learning tasks.
FICGAN: Facial Identity Controllable GAN for De-identification
Oct 02, 2021
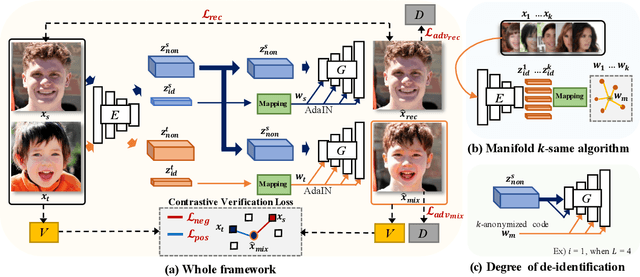


In this work, we present Facial Identity Controllable GAN (FICGAN) for not only generating high-quality de-identified face images with ensured privacy protection, but also detailed controllability on attribute preservation for enhanced data utility. We tackle the less-explored yet desired functionality in face de-identification based on the two factors. First, we focus on the challenging issue to obtain a high level of privacy protection in the de-identification task while uncompromising the image quality. Second, we analyze the facial attributes related to identity and non-identity and explore the trade-off between the degree of face de-identification and preservation of the source attributes for enhanced data utility. Based on the analysis, we develop Facial Identity Controllable GAN (FICGAN), an autoencoder-based conditional generative model that learns to disentangle the identity attributes from non-identity attributes on a face image. By applying the manifold k-same algorithm to satisfy k-anonymity for strengthened security, our method achieves enhanced privacy protection in de-identified face images. Numerous experiments demonstrate that our model outperforms others in various scenarios of face de-identification.
Memory-Augmented Neural Networks for Knowledge Tracing from the Perspective of Learning and Forgetting
Oct 01, 2018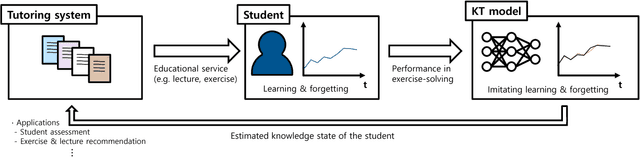



Knowledge tracing (KT) refers to a machine learning technique to assess a student's level of understanding (or knowledge state) based on the student's past performance in exercise-solving. KT accepts a series of question-answer pairs as an input and iteratively updates the knowledge state of the student, eventually returning the probability of the student solving a given question. To estimate the accurate knowledge state, a KT model should imitate the learning and forgetting mechanisms of the student. Deep learning-based KT models, proposed recently, show a higher predictive performance than traditional machine learning-based KT models due to the representative power of neural networks. The dynamic key value memory network (DKVMN), a kind of memory augmented neural network (MANN), is a state-of-the-art KT model, but it has some limitations. DKVMN does not utilize information from a current knowledge state and overestimates the amount of forgetting when updating the knowledge state. To improve the learning and forgetting mechanism of the DKVMN, we propose a knowledge tracing model that incorporates: (1) an adaptive knowledge growth depending on the current knowledge state, and (2) an additional loss term that can regularize the degree of forgetting. To measure the degree of forgetting of the KT model, we define a positive update ratio (PUR) that can complement the predictive performance metric (AUC). According to our experiments using four public benchmarks, the proposed approaches outperform the original DKVMN in terms of both AUC (predictive performance) and PUR (degree of forgetting).
Security and Privacy Issues in Deep Learning
Jul 31, 2018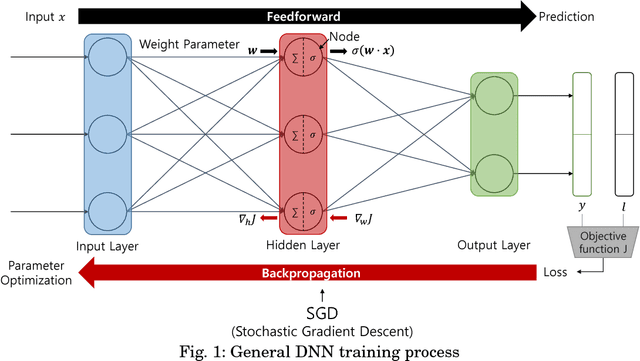
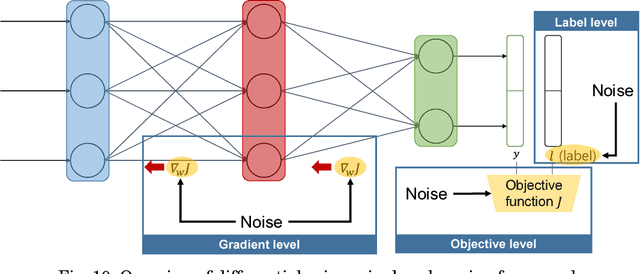
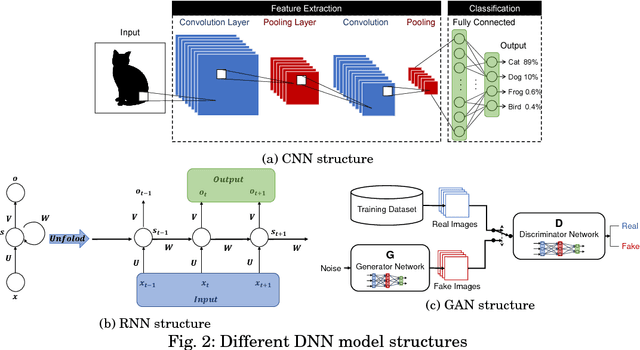
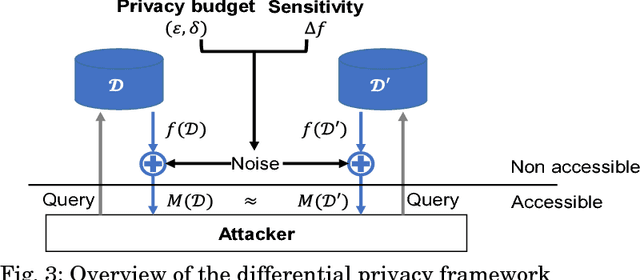
With the development of machine learning, expectations for artificial intelligence (AI) technology are increasing day by day. In particular, deep learning has shown enriched performance results in a variety of fields. There are many applications that are closely related to our daily life, such as making significant decisions in application area based on predictions or classifications, in which a deep learning (DL) model could be relevant. Hence, if a DL model causes mispredictions or misclassifications due to malicious external influences, it can cause very large difficulties in real life. Moreover, training deep learning models involves relying on an enormous amount of data and the training data often includes sensitive information. Therefore, deep learning models should not expose the privacy of such data. In this paper, we reviewed the threats and developed defense methods on the security of the models and the data privacy under the notion of SPAI: Secure and Private AI. We also discuss current challenges and open issues.
Reinforcement Learning based Recommender System using Biclustering Technique
Jan 17, 2018
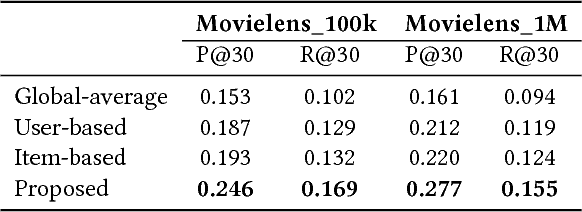

A recommender system aims to recommend items that a user is interested in among many items. The need for the recommender system has been expanded by the information explosion. Various approaches have been suggested for providing meaningful recommendations to users. One of the proposed approaches is to consider a recommender system as a Markov decision process (MDP) problem and try to solve it using reinforcement learning (RL). However, existing RL-based methods have an obvious drawback. To solve an MDP in a recommender system, they encountered a problem with the large number of discrete actions that bring RL to a larger class of problems. In this paper, we propose a novel RL-based recommender system. We formulate a recommender system as a gridworld game by using a biclustering technique that can reduce the state and action space significantly. Using biclustering not only reduces space but also improves the recommendation quality effectively handling the cold-start problem. In addition, our approach can provide users with some explanation why the system recommends certain items. Lastly, we examine the proposed algorithm on a real-world dataset and achieve a better performance than the widely used recommendation algorithm.
Energy-Based Sequence GANs for Recommendation and Their Connection to Imitation Learning
Jun 28, 2017
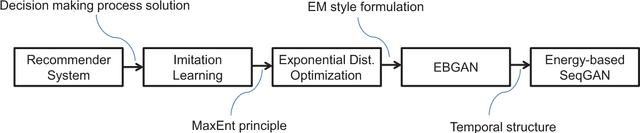
Recommender systems aim to find an accurate and efficient mapping from historic data of user-preferred items to a new item that is to be liked by a user. Towards this goal, energy-based sequence generative adversarial nets (EB-SeqGANs) are adopted for recommendation by learning a generative model for the time series of user-preferred items. By recasting the energy function as the feature function, the proposed EB-SeqGANs is interpreted as an instance of maximum-entropy imitation learning.