 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Spatial Frequency: Pixel-wise Temporal Frequency-based Deepfake Video Detection
Jul 03, 2025We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. Traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect temporal artifacts in the pixel plane. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.
DECOR:Decomposition and Projection of Text Embeddings for Text-to-Image Customization
Dec 12, 2024Text-to-image (T2I) models can effectively capture the content or style of reference images to perform high-quality customization. A representative technique for this is fine-tuning using low-rank adaptations (LoRA), which enables efficient model customization with reference images. However, fine-tuning with a limited number of reference images often leads to overfitting, resulting in issues such as prompt misalignment or content leakage. These issues prevent the model from accurately following the input prompt or generating undesired objects during inference. To address this problem, we examine the text embeddings that guide the diffusion model during inference. This study decomposes the text embedding matrix and conducts a component analysis to understand the embedding space geometry and identify the cause of overfitting. Based on this, we propose DECOR, which projects text embeddings onto a vector space orthogonal to undesired token vectors, thereby reducing the influence of unwanted semantics in the text embeddings. Experimental results demonstrate that DECOR outperforms state-of-the-art customization models and achieves Pareto frontier performance across text and visual alignment evaluation metrics. Furthermore, it generates images more faithful to the input prompts, showcasing its effectiveness in addressing overfitting and enhancing text-to-image customization.
Advancing Cross-Domain Generalizability in Face Anti-Spoofing: Insights, Design, and Metrics
Jun 18, 2024



This paper presents a novel perspective for enhancing anti-spoofing performance in zero-shot data domain generalization. Unlike traditional image classification tasks, face anti-spoofing datasets display unique generalization characteristics, necessitating novel zero-shot data domain generalization. One step forward to the previous frame-wise spoofing prediction, we introduce a nuanced metric calculation that aggregates frame-level probabilities for a video-wise prediction, to tackle the gap between the reported frame-wise accuracy and instability in real-world use-case. This approach enables the quantification of bias and variance in model predictions, offering a more refined analysis of model generalization. Our investigation reveals that simply scaling up the backbone of models does not inherently improve the mentioned instability, leading us to propose an ensembled backbone method from a Bayesian perspective. The probabilistically ensembled backbone both improves model robustness measured from the proposed metric and spoofing accuracy, and also leverages the advantages of measuring uncertainty, allowing for enhanced sampling during training that contributes to model generalization across new datasets. We evaluate the proposed method from the benchmark OMIC dataset and also the public CelebA-Spoof and SiW-Mv2. Our final model outperforms existing state-of-the-art methods across the datasets, showcasing advancements in Bias, Variance, HTER, and AUC metrics.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Exploiting Style Latent Flows for Generalizing Deepfake Detection Video Detection
Mar 11, 2024



This paper presents a new approach for the detection of fake videos, based on the analysis of style latent vectors and their abnormal behavior in temporal changes in the generated videos. We discovered that the generated facial videos suffer from the temporal distinctiveness in the temporal changes of style latent vectors, which are inevitable during the generation of temporally stable videos with various facial expressions and geometric transformations. Our framework utilizes the StyleGRU module, trained by contrastive learning, to represent the dynamic properties of style latent vectors. Additionally, we introduce a style attention module that integrates StyleGRU-generated features with content-based features, enabling the detection of visual and temporal artifacts. We demonstrate our approach across various benchmark scenarios in deepfake detection, showing its superiority in cross-dataset and cross-manipulation scenarios. Through further analysis, we also validate the importance of using temporal changes of style latent vectors to improve the generality of deepfake video detection.
One-Shot Structure-Aware Stylized Image Synthesis
Feb 27, 2024



While GAN-based models have been successful in image stylization tasks, they often struggle with structure preservation while stylizing a wide range of input images. Recently, diffusion models have been adopted for image stylization but still lack the capability to maintain the original quality of input images. Building on this, we propose OSASIS: a novel one-shot stylization method that is robust in structure preservation. We show that OSASIS is able to effectively disentangle the semantics from the structure of an image, allowing it to control the level of content and style implemented to a given input. We apply OSASIS to various experimental settings, including stylization with out-of-domain reference images and stylization with text-driven manipulation. Results show that OSASIS outperforms other stylization methods, especially for input images that were rarely encountered during training, providing a promising solution to stylization via diffusion models.
Noise Map Guidance: Inversion with Spatial Context for Real Image Editing
Feb 07, 2024Text-guided diffusion models have become a popular tool in image synthesis, known for producing high-quality and diverse images. However, their application to editing real images often encounters hurdles primarily due to the text condition deteriorating the reconstruction quality and subsequently affecting editing fidelity. Null-text Inversion (NTI) has made strides in this area, but it fails to capture spatial context and requires computationally intensive per-timestep optimization. Addressing these challenges, we present Noise Map Guidance (NMG), an inversion method rich in a spatial context, tailored for real-image editing. Significantly, NMG achieves this without necessitating optimization, yet preserves the editing quality. Our empirical investigations highlight NMG's adaptability across various editing techniques and its robustness to variants of DDIM inversions.
Compose and Conquer: Diffusion-Based 3D Depth Aware Composable Image Synthesis
Jan 17, 2024Addressing the limitations of text as a source of accurate layout representation in text-conditional diffusion models, many works incorporate additional signals to condition certain attributes within a generated image. Although successful, previous works do not account for the specific localization of said attributes extended into the three dimensional plane. In this context, we present a conditional diffusion model that integrates control over three-dimensional object placement with disentangled representations of global stylistic semantics from multiple exemplar images. Specifically, we first introduce \textit{depth disentanglement training} to leverage the relative depth of objects as an estimator, allowing the model to identify the absolute positions of unseen objects through the use of synthetic image triplets. We also introduce \textit{soft guidance}, a method for imposing global semantics onto targeted regions without the use of any additional localization cues. Our integrated framework, \textsc{Compose and Conquer (CnC)}, unifies these techniques to localize multiple conditions in a disentangled manner. We demonstrate that our approach allows perception of objects at varying depths while offering a versatile framework for composing localized objects with different global semantics. Code: https://github.com/tomtom1103/compose-and-conquer/
Scaling of Class-wise Training Losses for Post-hoc Calibration
Jun 19, 2023The class-wise training losses often diverge as a result of the various levels of intra-class and inter-class appearance variation, and we find that the diverging class-wise training losses cause the uncalibrated prediction with its reliability. To resolve the issue, we propose a new calibration method to synchronize the class-wise training losses. We design a new training loss to alleviate the variance of class-wise training losses by using multiple class-wise scaling factors. Since our framework can compensate the training losses of overfitted classes with those of under-fitted classes, the integrated training loss is preserved, preventing the performance drop even after the model calibration. Furthermore, our method can be easily employed in the post-hoc calibration methods, allowing us to use the pre-trained model as an initial model and reduce the additional computation for model calibration. We validate the proposed framework by employing it in the various post-hoc calibration methods, which generally improves calibration performance while preserving accuracy, and discover through the investigation that our approach performs well with unbalanced datasets and untuned hyperparameters.
FrePGAN: Robust Deepfake Detection Using Frequency-level Perturbations
Feb 07, 2022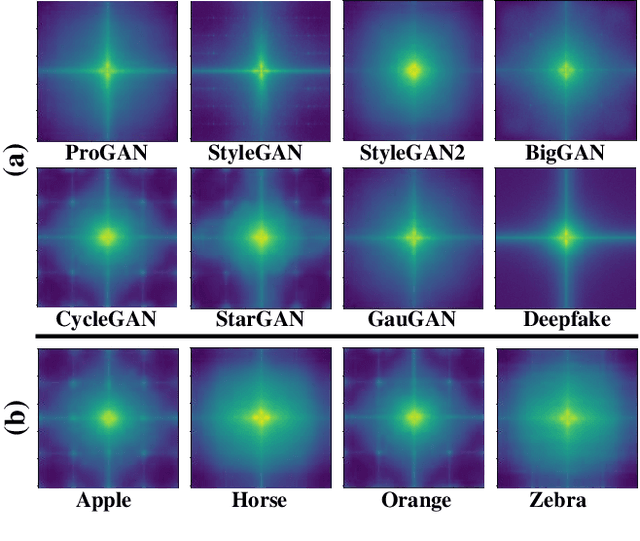

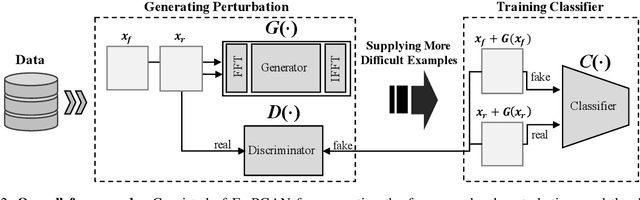
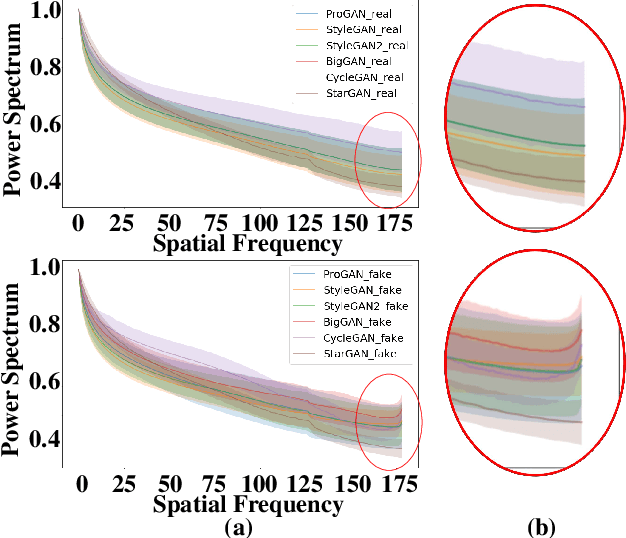
Various deepfake detectors have been proposed, but challenges still exist to detect images of unknown categories or GAN models outside of the training settings. Such issues arise from the overfitting issue, which we discover from our own analysis and the previous studies to originate from the frequency-level artifacts in generated images. We find that ignoring the frequency-level artifacts can improve the detector's generalization across various GAN models, but it can reduce the model's performance for the trained GAN models. Thus, we design a framework to generalize the deepfake detector for both the known and unseen GAN models. Our framework generates the frequency-level perturbation maps to make the generated images indistinguishable from the real images. By updating the deepfake detector along with the training of the perturbation generator, our model is trained to detect the frequency-level artifacts at the initial iterations and consider the image-level irregularities at the last iterations. For experiments, we design new test scenarios varying from the training settings in GAN models, color manipulations, and object categories. Numerous experiments validate the state-of-the-art performance of our deepfake detector.