 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Cross-Domain Generalizability in Face Anti-Spoofing: Insights, Design, and Metrics
Jun 18, 2024



This paper presents a novel perspective for enhancing anti-spoofing performance in zero-shot data domain generalization. Unlike traditional image classification tasks, face anti-spoofing datasets display unique generalization characteristics, necessitating novel zero-shot data domain generalization. One step forward to the previous frame-wise spoofing prediction, we introduce a nuanced metric calculation that aggregates frame-level probabilities for a video-wise prediction, to tackle the gap between the reported frame-wise accuracy and instability in real-world use-case. This approach enables the quantification of bias and variance in model predictions, offering a more refined analysis of model generalization. Our investigation reveals that simply scaling up the backbone of models does not inherently improve the mentioned instability, leading us to propose an ensembled backbone method from a Bayesian perspective. The probabilistically ensembled backbone both improves model robustness measured from the proposed metric and spoofing accuracy, and also leverages the advantages of measuring uncertainty, allowing for enhanced sampling during training that contributes to model generalization across new datasets. We evaluate the proposed method from the benchmark OMIC dataset and also the public CelebA-Spoof and SiW-Mv2. Our final model outperforms existing state-of-the-art methods across the datasets, showcasing advancements in Bias, Variance, HTER, and AUC metrics.
Gaussian Mixture Proposals with Pull-Push Learning Scheme to Capture Diverse Events for Weakly Supervised Temporal Video Grounding
Dec 27, 2023



In the weakly supervised temporal video grounding study, previous methods use predetermined single Gaussian proposals which lack the ability to express diverse events described by the sentence query. To enhance the expression ability of a proposal, we propose a Gaussian mixture proposal (GMP) that can depict arbitrary shapes by learning importance, centroid, and range of every Gaussian in the mixture. In learning GMP, each Gaussian is not trained in a feature space but is implemented over a temporal location. Thus the conventional feature-based learning for Gaussian mixture model is not valid for our case. In our special setting, to learn moderately coupled Gaussian mixture capturing diverse events, we newly propose a pull-push learning scheme using pulling and pushing losses, each of which plays an opposite role to the other. The effects of components in our scheme are verified in-depth with extensive ablation studies and the overall scheme achieves state-of-the-art performance. Our code is available at https://github.com/sunoh-kim/pps.
Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation
Dec 15, 2023



This paper introduces a novel approach for topic modeling utilizing latent codebooks from Vector-Quantized Variational Auto-Encoder~(VQ-VAE), discretely encapsulating the rich information of the pre-trained embeddings such as the pre-trained language model. From the novel interpretation of the latent codebooks and embeddings as conceptual bag-of-words, we propose a new generative topic model called Topic-VQ-VAE~(TVQ-VAE) which inversely generates the original documents related to the respective latent codebook. The TVQ-VAE can visualize the topics with various generative distributions including the traditional BoW distribution and the autoregressive image generation. Our experimental results on document analysis and image generation demonstrate that TVQ-VAE effectively captures the topic context which reveals the underlying structures of the dataset and supports flexible forms of document generation. Official implementation of the proposed TVQ-VAE is available at https://github.com/clovaai/TVQ-VAE.
GeNAS: Neural Architecture Search with Better Generalization
May 18, 2023Neural Architecture Search (NAS) aims to automatically excavate the optimal network architecture with superior test performance. Recent neural architecture search (NAS) approaches rely on validation loss or accuracy to find the superior network for the target data. In this paper, we investigate a new neural architecture search measure for excavating architectures with better generalization. We demonstrate that the flatness of the loss surface can be a promising proxy for predicting the generalization capability of neural network architectures. We evaluate our proposed method on various search spaces, showing similar or even better performance compared to the state-of-the-art NAS methods. Notably, the resultant architecture found by flatness measure generalizes robustly to various shifts in data distribution (e.g. ImageNet-V2,-A,-O), as well as various tasks such as object detection and semantic segmentation. Code is available at https://github.com/clovaai/GeNAS.
Learning Features with Parameter-Free Layers
Feb 06, 2022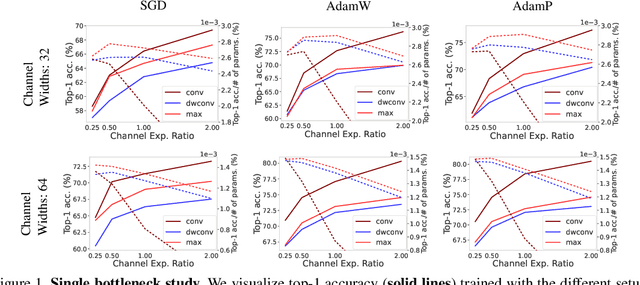
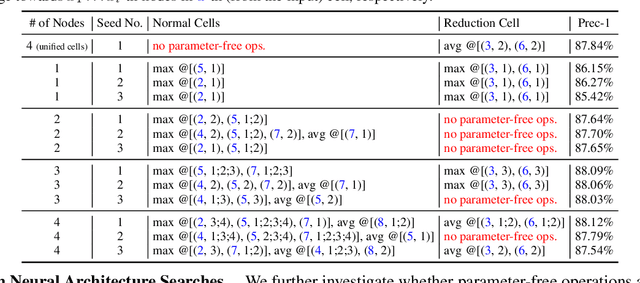
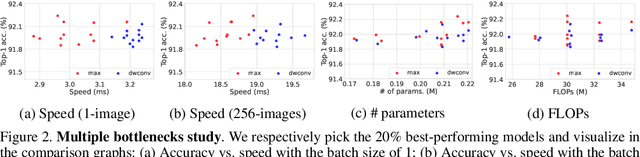
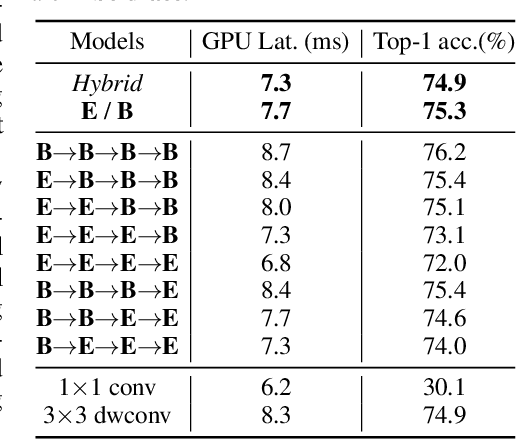
Trainable layers such as convolutional building blocks are the standard network design choices by learning parameters to capture the global context through successive spatial operations. When designing an efficient network, trainable layers such as the depthwise convolution is the source of efficiency in the number of parameters and FLOPs, but there was little improvement to the model speed in practice. This paper argues that simple built-in parameter-free operations can be a favorable alternative to the efficient trainable layers replacing spatial operations in a network architecture. We aim to break the stereotype of organizing the spatial operations of building blocks into trainable layers. Extensive experimental analyses based on layer-level studies with fully-trained models and neural architecture searches are provided to investigate whether parameter-free operations such as the max-pool are functional. The studies eventually give us a simple yet effective idea for redesigning network architectures, where the parameter-free operations are heavily used as the main building block without sacrificing the model accuracy as much. Experimental results on the ImageNet dataset demonstrate that the network architectures with parameter-free operations could enjoy the advantages of further efficiency in terms of model speed, the number of the parameters, and FLOPs. Code and ImageNet pretrained models are available at https://github.com/naver-ai/PfLayer.
Rainbow Memory: Continual Learning with a Memory of Diverse Samples
Mar 31, 2021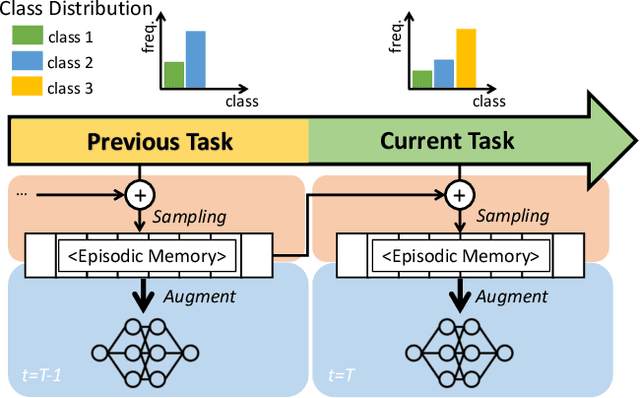
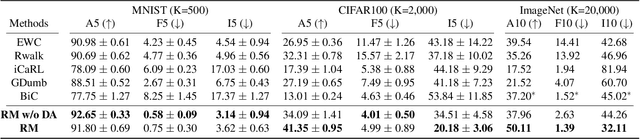
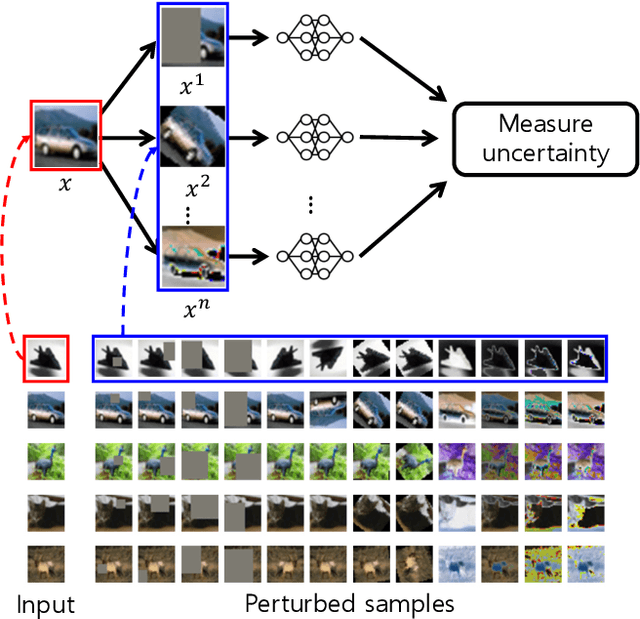
Continual learning is a realistic learning scenario for AI models. Prevalent scenario of continual learning, however, assumes disjoint sets of classes as tasks and is less realistic rather artificial. Instead, we focus on 'blurry' task boundary; where tasks shares classes and is more realistic and practical. To address such task, we argue the importance of diversity of samples in an episodic memory. To enhance the sample diversity in the memory, we propose a novel memory management strategy based on per-sample classification uncertainty and data augmentation, named Rainbow Memory (RM). With extensive empirical validations on MNIST, CIFAR10, CIFAR100, and ImageNet datasets, we show that the proposed method significantly improves the accuracy in blurry continual learning setups, outperforming state of the arts by large margins despite its simplicity. Code and data splits will be available in https://github.com/clovaai/rainbow-memory.
ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
Jul 02, 2020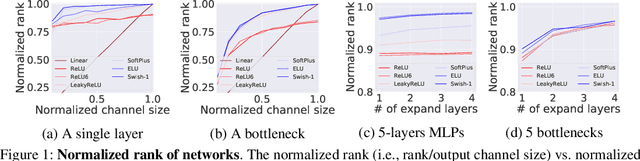

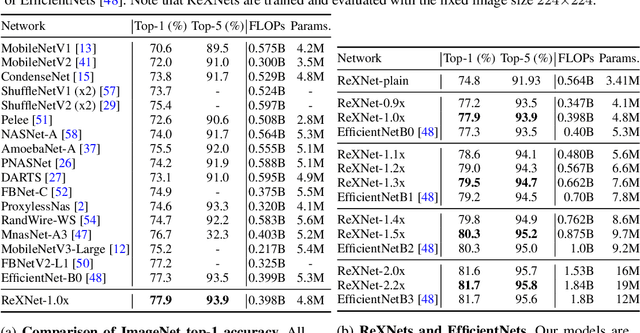
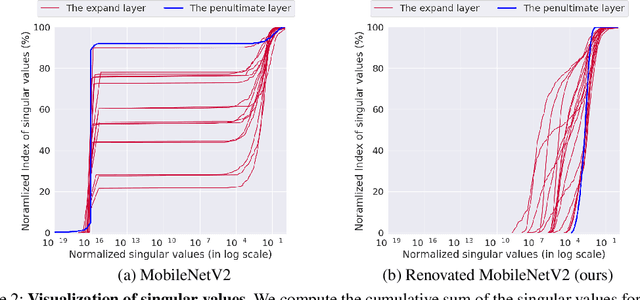
This paper addresses representational bottleneck in a network and propose a set of design principles that improves model performance significantly. We argue that a representational bottleneck may happen in a network designed by a conventional design and results in degrading the model performance. To investigate the representational bottleneck, we study the matrix rank of the features generated by ten thousand random networks. We further study the entire layer's channel configuration towards designing more accurate network architectures. Based on the investigation, we propose simple yet effective design principles to mitigate the representational bottleneck. Slight changes on baseline networks by following the principle leads to achieving remarkable performance improvements on ImageNet classification. Additionally, COCO object detection results and transfer learning results on several datasets provide other backups of the link between diminishing representational bottleneck of a network and improving performance. Code and pretrained models are available at https://github.com/clovaai/rexnet.
Efficient Active Learning for Automatic Speech Recognition via Augmented Consistency Regularization
Jun 19, 2020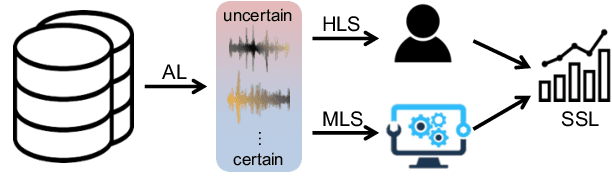
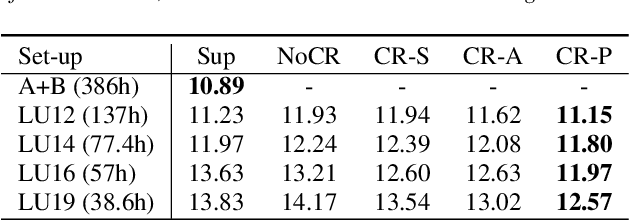
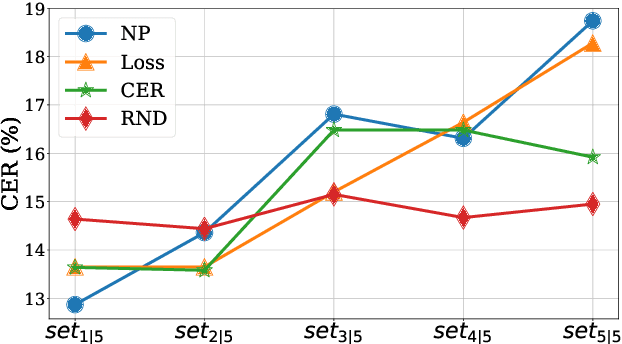
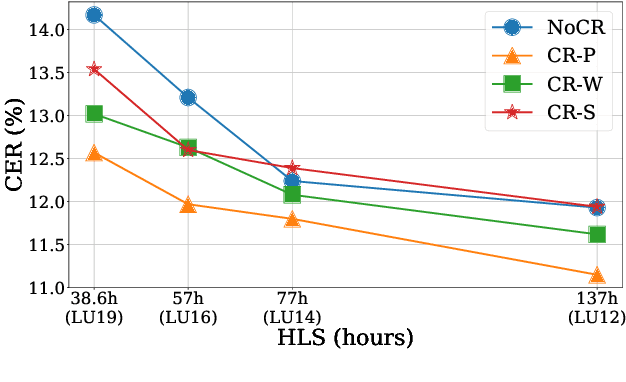
The cost of labeling transcriptions for large speech corpora becomes a bottleneck to maximally enjoy the potential capacity of deep neural network-based automatic speech recognition (ASR) models. Therefore, in this paper, we present a new training scheme that minimizes the labeling cost by adopting the concepts of semi-supervised learning (SSL) and active learning (AL) approaches and making a synergy from them. While AL studies only focus on selecting minimized the number of samples to be labeled with a criterion and taking advantage of such samples, we show that the training efficiency can be further improved by utilizing the unlabeled samples by sophisticatedly designing unsupervised loss that complements the unwanted behavior of supervised loss effectively. Our unsupervised loss is built on Consistency-Regularization (CR) approach, and we propose appropriate augmentation techniques to adopt CR in ASR field successfully. From the qualitative and quantitative experiments on the real-world dataset from deployed end-user voice assistant services, we show that the proposed methods can handle a large number of unlabeled speech data to achieve competitive model performance, with a sustainable amount of human labeling cost.
SINet: Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder
Dec 09, 2019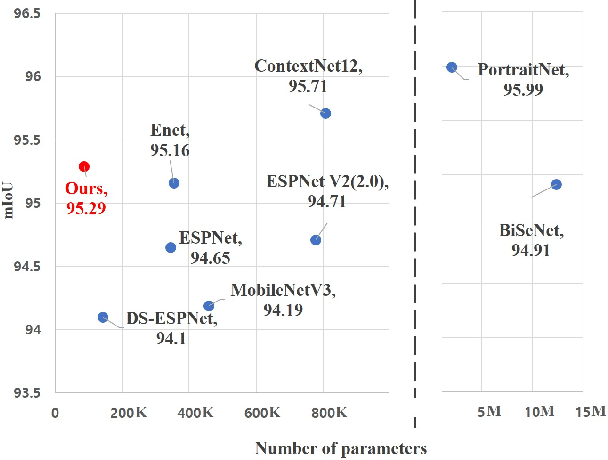


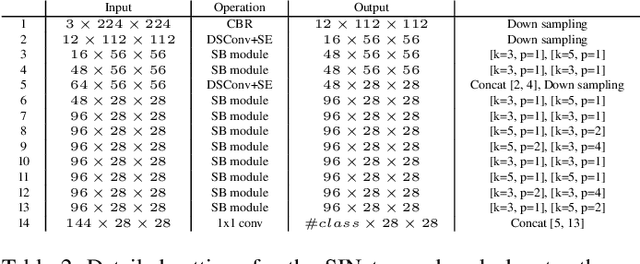
Designing a lightweight and robust portrait segmentation algorithm is an important task for a wide range of face applications. However, the problem has been considered as a subset of the object segmentation problem and less handled in the semantic segmentation field. Obviously, portrait segmentation has its unique requirements. First, because the portrait segmentation is performed in the middle of a whole process of many real-world applications, it requires extremely lightweight models. Second, there has not been any public datasets in this domain that contain a sufficient number of images with unbiased statistics. To solve the first problem, we introduce the new extremely lightweight portrait segmentation model SINet, containing an information blocking decoder and spatial squeeze modules. The information blocking decoder uses confidence estimates to recover local spatial information without spoiling global consistency. The spatial squeeze module uses multiple receptive fields to cope with various sizes of consistency in the image. To tackle the second problem, we propose a simple method to create additional portrait segmentation data which can improve accuracy on the EG1800 dataset. In our qualitative and quantitative analysis on the EG1800 dataset, we show that our method outperforms various existing lightweight segmentation models. Our method reduces the number of parameters from 2.1M to 86.9K (around 95.9% reduction), while maintaining the accuracy under an 1% margin from the state-of-the-art portrait segmentation method. We also show our model is successfully executed on a real mobile device with 100.6 FPS. In addition, we demonstrate that our method can be used for general semantic segmentation on the Cityscapes dataset. The code and dataset are available in https://github.com/HYOJINPARK/ExtPortraitSeg .
Neural Approximation of an Auto-Regressive Process through Confidence Guided Sampling
Oct 15, 2019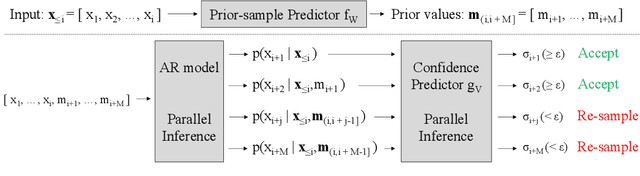

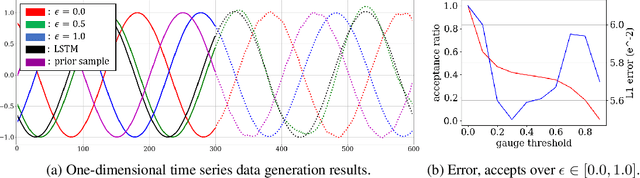
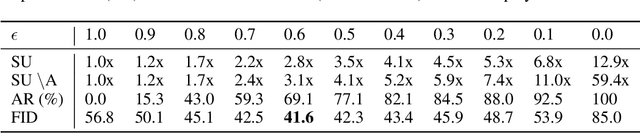
We propose a generic confidence-based approximation that can be plugged in and simplify the auto-regressive generation process with a proved convergence. We first assume that the priors of future samples can be generated in an independently and identically distributed (i.i.d.) manner using an efficient predictor. Given the past samples and future priors, the mother AR model can post-process the priors while the accompanied confidence predictor decides whether the current sample needs a resampling or not. Thanks to the i.i.d. assumption, the post-processing can update each sample in a parallel way, which remarkably accelerates the mother model. Our experiments on different data domains including sequences and images show that the proposed method can successfully capture the complex structures of the data and generate the meaningful future samples with lower computational cost while preserving the sequential relationship of the data.