 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Unsupervised Interpolation Without Any Intermediate Frame for 4D Medical Images
Apr 01, 2024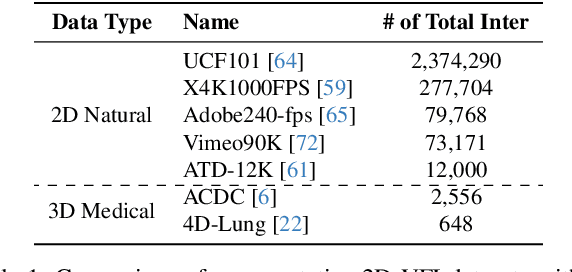
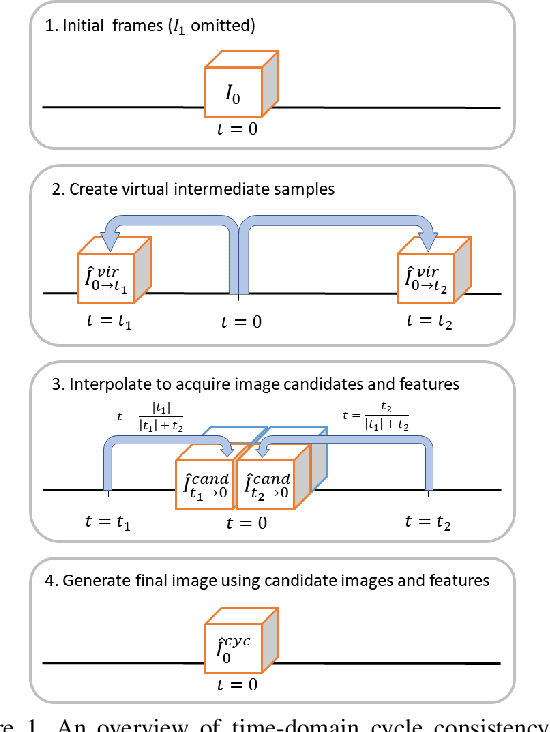


4D medical images, which represent 3D images with temporal information, are crucial in clinical practice for capturing dynamic changes and monitoring long-term disease progression. However, acquiring 4D medical images poses challenges due to factors such as radiation exposure and imaging duration, necessitating a balance between achieving high temporal resolution and minimizing adverse effects. Given these circumstances, not only is data acquisition challenging, but increasing the frame rate for each dataset also proves difficult. To address this challenge, this paper proposes a simple yet effective Unsupervised Volumetric Interpolation framework, UVI-Net. This framework facilitates temporal interpolation without the need for any intermediate frames, distinguishing it from the majority of other existing unsupervised methods. Experiments on benchmark datasets demonstrate significant improvements across diverse evaluation metrics compared to unsupervised and supervised baselines. Remarkably, our approach achieves this superior performance even when trained with a dataset as small as one, highlighting its exceptional robustness and efficiency in scenarios with sparse supervision. This positions UVI-Net as a compelling alternative for 4D medical imaging, particularly in settings where data availability is limited. The source code is available at https://github.com/jungeun122333/UVI-Net.
ProxyDet: Synthesizing Proxy Novel Classes via Classwise Mixup for Open-Vocabulary Object Detection
Dec 19, 2023Open-vocabulary object detection (OVOD) aims to recognize novel objects whose categories are not included in the training set. In order to classify these unseen classes during training, many OVOD frameworks leverage the zero-shot capability of largely pretrained vision and language models, such as CLIP. To further improve generalization on the unseen novel classes, several approaches proposed to additionally train with pseudo region labeling on the external data sources that contain a substantial number of novel category labels beyond the existing training data. Albeit its simplicity, these pseudo-labeling methods still exhibit limited improvement with regard to the truly unseen novel classes that were not pseudo-labeled. In this paper, we present a novel, yet simple technique that helps generalization on the overall distribution of novel classes. Inspired by our observation that numerous novel classes reside within the convex hull constructed by the base (seen) classes in the CLIP embedding space, we propose to synthesize proxy-novel classes approximating novel classes via linear mixup between a pair of base classes. By training our detector with these synthetic proxy-novel classes, we effectively explore the embedding space of novel classes. The experimental results on various OVOD benchmarks such as LVIS and COCO demonstrate superior performance on novel classes compared to the other state-of-the-art methods. Code is available at https://github.com/clovaai/ProxyDet.
GeNAS: Neural Architecture Search with Better Generalization
May 18, 2023Neural Architecture Search (NAS) aims to automatically excavate the optimal network architecture with superior test performance. Recent neural architecture search (NAS) approaches rely on validation loss or accuracy to find the superior network for the target data. In this paper, we investigate a new neural architecture search measure for excavating architectures with better generalization. We demonstrate that the flatness of the loss surface can be a promising proxy for predicting the generalization capability of neural network architectures. We evaluate our proposed method on various search spaces, showing similar or even better performance compared to the state-of-the-art NAS methods. Notably, the resultant architecture found by flatness measure generalizes robustly to various shifts in data distribution (e.g. ImageNet-V2,-A,-O), as well as various tasks such as object detection and semantic segmentation. Code is available at https://github.com/clovaai/GeNAS.
Distilling Linguistic Context for Language Model Compression
Sep 17, 2021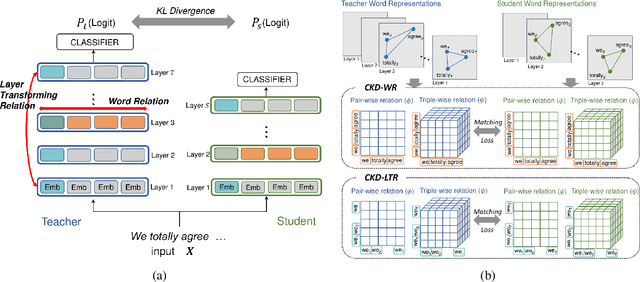


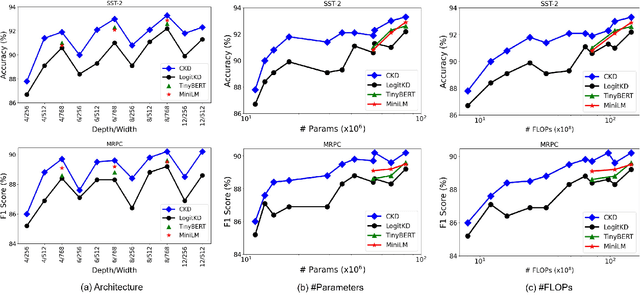
A computationally expensive and memory intensive neural network lies behind the recent success of language representation learning. Knowledge distillation, a major technique for deploying such a vast language model in resource-scarce environments, transfers the knowledge on individual word representations learned without restrictions. In this paper, inspired by the recent observations that language representations are relatively positioned and have more semantic knowledge as a whole, we present a new knowledge distillation objective for language representation learning that transfers the contextual knowledge via two types of relationships across representations: Word Relation and Layer Transforming Relation. Unlike other recent distillation techniques for the language models, our contextual distillation does not have any restrictions on architectural changes between teacher and student. We validate the effectiveness of our method on challenging benchmarks of language understanding tasks, not only in architectures of various sizes, but also in combination with DynaBERT, the recently proposed adaptive size pruning method.
Attribution Preservation in Network Compression for Reliable Network Interpretation
Oct 28, 2020
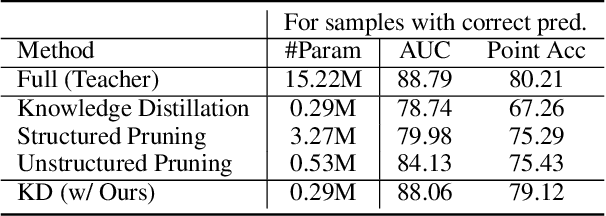


Neural networks embedded in safety-sensitive applications such as self-driving cars and wearable health monitors rely on two important techniques: input attribution for hindsight analysis and network compression to reduce its size for edge-computing. In this paper, we show that these seemingly unrelated techniques conflict with each other as network compression deforms the produced attributions, which could lead to dire consequences for mission-critical applications. This phenomenon arises due to the fact that conventional network compression methods only preserve the predictions of the network while ignoring the quality of the attributions. To combat the attribution inconsistency problem, we present a framework that can preserve the attributions while compressing a network. By employing the Weighted Collapsed Attribution Matching regularizer, we match the attribution maps of the network being compressed to its pre-compression former self. We demonstrate the effectiveness of our algorithm both quantitatively and qualitatively on diverse compression methods.
MHSAN: Multi-Head Self-Attention Network for Visual Semantic Embedding
Jan 11, 2020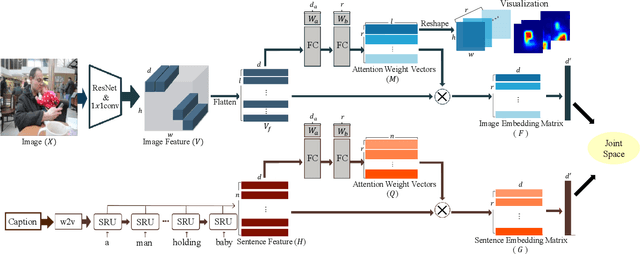
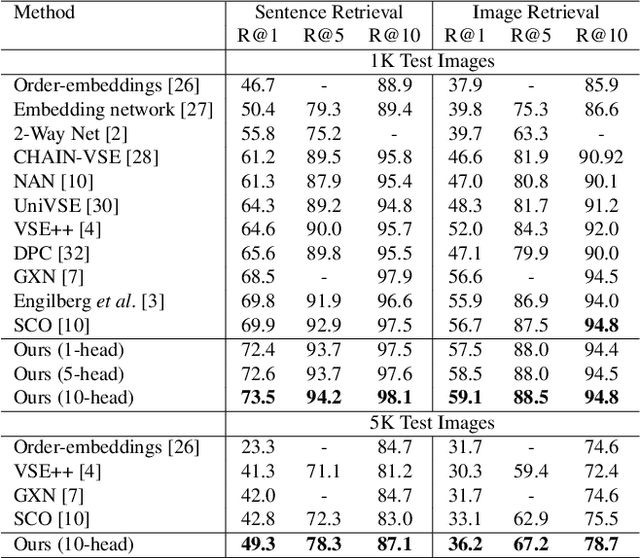
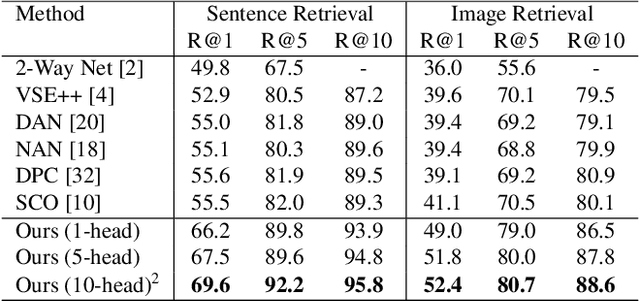

Visual-semantic embedding enables various tasks such as image-text retrieval, image captioning, and visual question answering. The key to successful visual-semantic embedding is to express visual and textual data properly by accounting for their intricate relationship. While previous studies have achieved much advance by encoding the visual and textual data into a joint space where similar concepts are closely located, they often represent data by a single vector ignoring the presence of multiple important components in an image or text. Thus, in addition to the joint embedding space, we propose a novel multi-head self-attention network to capture various components of visual and textual data by attending to important parts in data. Our approach achieves the new state-of-the-art results in image-text retrieval tasks on MS-COCO and Flicker30K datasets. Through the visualization of the attention maps that capture distinct semantic components at multiple positions in the image and the text, we demonstrate that our method achieves an effective and interpretable visual-semantic joint space.