 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHINKSAFE: Self-Generated Safety Alignment for Reasoning Models
Jan 30, 2026Large reasoning models (LRMs) achieve remarkable performance by leveraging reinforcement learning (RL) on reasoning tasks to generate long chain-of-thought (CoT) reasoning. However, this over-optimization often prioritizes compliance, making models vulnerable to harmful prompts. To mitigate this safety degradation, recent approaches rely on external teacher distillation, yet this introduces a distributional discrepancy that degrades native reasoning. We propose ThinkSafe, a self-generated alignment framework that restores safety alignment without external teachers. Our key insight is that while compliance suppresses safety mechanisms, models often retain latent knowledge to identify harm. ThinkSafe unlocks this via lightweight refusal steering, guiding the model to generate in-distribution safety reasoning traces. Fine-tuning on these self-generated responses effectively realigns the model while minimizing distribution shift. Experiments on DeepSeek-R1-Distill and Qwen3 show ThinkSafe significantly improves safety while preserving reasoning proficiency. Notably, it achieves superior safety and comparable reasoning to GRPO, with significantly reduced computational cost. Code, models, and datasets are available at https://github.com/seanie12/ThinkSafe.git.
Every Expert Matters: Towards Effective Knowledge Distillation for Mixture-of-Experts Language Models
Feb 18, 2025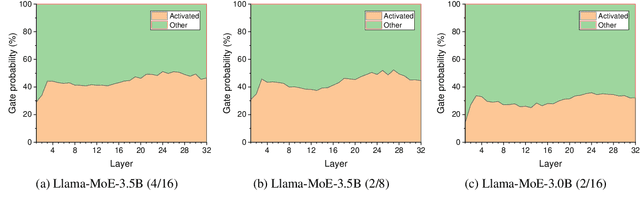
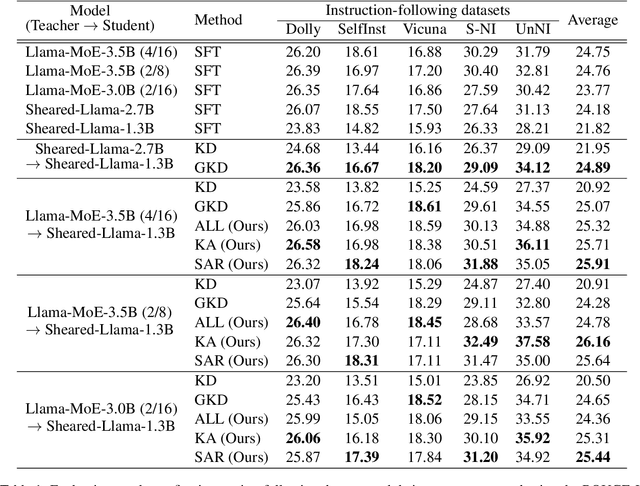
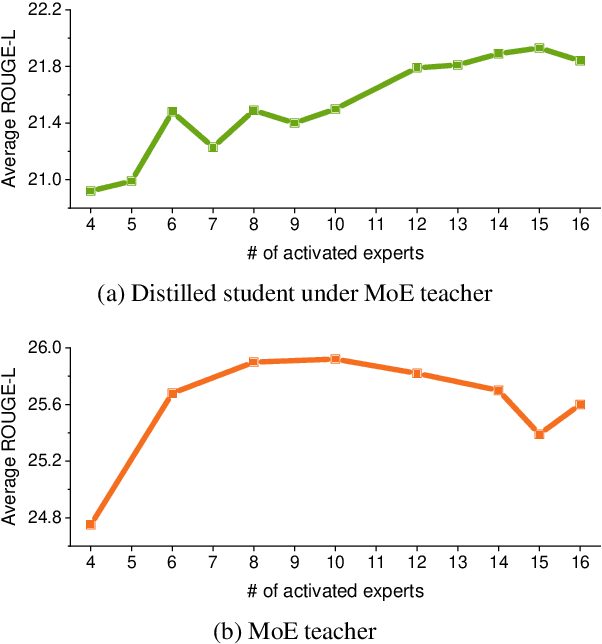
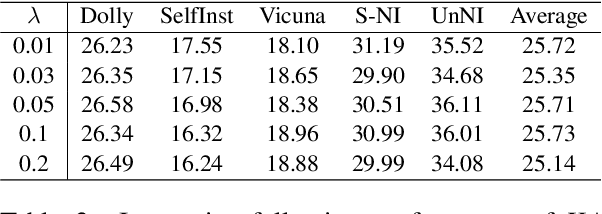
With the emergence of Mixture-of-Experts (MoE), the efficient scaling of model size has accelerated the development of large language models in recent years. However, their high memory requirements prevent their use in resource-constrained environments. While knowledge distillation (KD) has been a proven method for model compression, its application to MoE teacher models remains underexplored. Through our investigation, we discover that non-activated experts in MoE models possess valuable knowledge that benefits student models. We further demonstrate that existing KD methods are not optimal for compressing MoE models, as they fail to leverage this knowledge effectively. To address this, we propose two intuitive MoE-specific KD methods for the first time: Knowledge Augmentation (KA) and Student-Aware Router (SAR), both designed to effectively extract knowledge from all experts. Specifically, KA augments knowledge by sampling experts multiple times, while SAR uses all experts and adjusts the expert weights through router training to provide optimal knowledge. Extensive experiments show that our methods outperform conventional KD methods, demonstrating their effectiveness for MoE teacher models.
Divide and Translate: Compositional First-Order Logic Translation and Verification for Complex Logical Reasoning
Oct 10, 2024

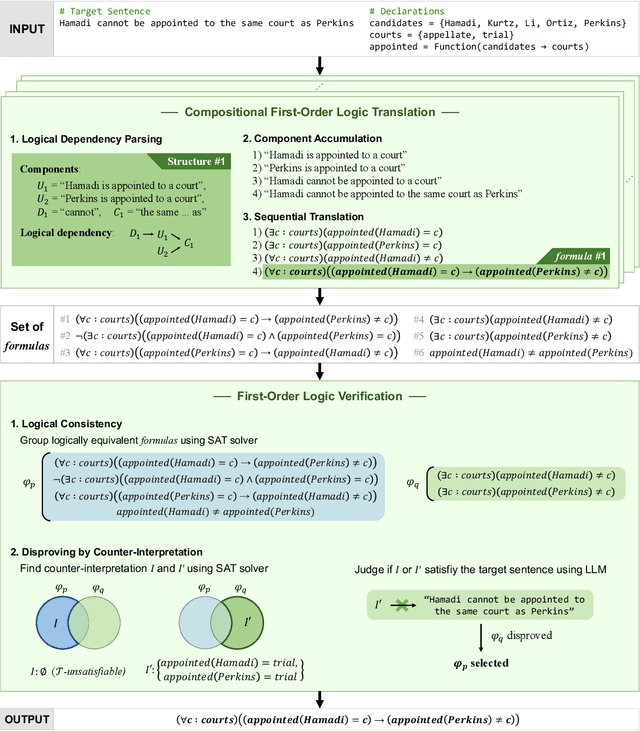
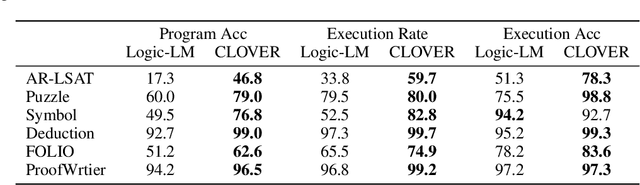
Complex logical reasoning tasks require a long sequence of reasoning, which a large language model (LLM) with chain-of-thought prompting still falls short. To alleviate this issue, neurosymbolic approaches incorporate a symbolic solver. Specifically, an LLM only translates a natural language problem into a satisfiability (SAT) problem that consists of first-order logic formulas, and a sound symbolic solver returns a mathematically correct solution. However, we discover that LLMs have difficulties to capture complex logical semantics hidden in the natural language during translation. To resolve this limitation, we propose a Compositional First-Order Logic Translation. An LLM first parses a natural language sentence into newly defined logical dependency structures that consist of an atomic subsentence and its dependents, then sequentially translate the parsed subsentences. Since multiple logical dependency structures and sequential translations are possible for a single sentence, we also introduce two Verification algorithms to ensure more reliable results. We utilize an SAT solver to rigorously compare semantics of generated first-order logic formulas and select the most probable one. We evaluate the proposed method, dubbed CLOVER, on seven logical reasoning benchmarks and show that it outperforms the previous neurosymbolic approaches and achieves new state-of-the-art results.
PromptKD: Distilling Student-Friendly Knowledge for Generative Language Models via Prompt Tuning
Feb 20, 2024


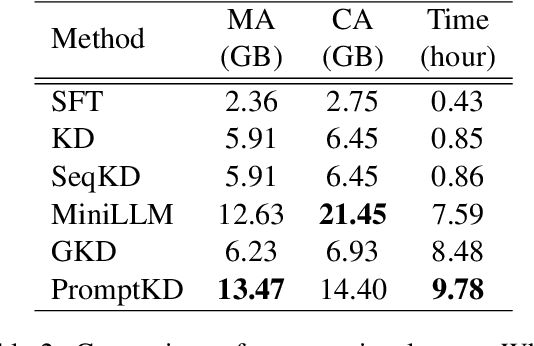
Recent advancements in large language models (LLMs) have raised concerns about inference costs, increasing the need for research into model compression. While knowledge distillation (KD) is a prominent method for this, research on KD for generative language models like LLMs is relatively sparse, and the approach of distilling student-friendly knowledge, which has shown promising performance in KD for classification models, remains unexplored in generative language models. To explore this approach, we propose PromptKD, a simple yet effective method that utilizes prompt tuning - for the first time in KD - to enable generative language models to transfer student-friendly knowledge. Unlike previous works in classification that require fine-tuning the entire teacher model for extracting student-friendly knowledge, PromptKD achieves similar effects by adding a small number of prompt tokens and tuning only the prompt with student guidance. Extensive experiments on instruction-following datasets using the GPT-2 model family show that PromptKD achieves state-of-the-art performance while adding only 0.0007% of the teacher's parameters as prompts. Further analysis suggests that distilling student-friendly knowledge alleviates exposure bias effectively throughout the entire training process, leading to performance enhancements.
Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Dec 06, 2022Inspired by the impressive performance of recent face image editing methods, several studies have been naturally proposed to extend these methods to the face video editing task. One of the main challenges here is temporal consistency among edited frames, which is still unresolved. To this end, we propose a novel face video editing framework based on diffusion autoencoders that can successfully extract the decomposed features - for the first time as a face video editing model - of identity and motion from a given video. This modeling allows us to edit the video by simply manipulating the temporally invariant feature to the desired direction for the consistency. Another unique strength of our model is that, since our model is based on diffusion models, it can satisfy both reconstruction and edit capabilities at the same time, and is robust to corner cases in wild face videos (e.g. occluded faces) unlike the existing GAN-based methods.
Distilling Linguistic Context for Language Model Compression
Sep 17, 2021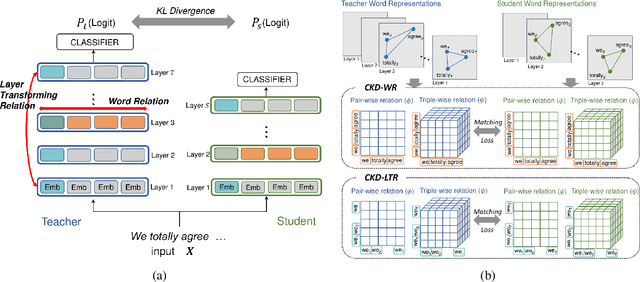


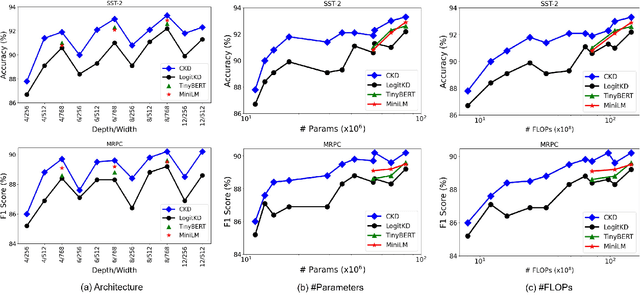
A computationally expensive and memory intensive neural network lies behind the recent success of language representation learning. Knowledge distillation, a major technique for deploying such a vast language model in resource-scarce environments, transfers the knowledge on individual word representations learned without restrictions. In this paper, inspired by the recent observations that language representations are relatively positioned and have more semantic knowledge as a whole, we present a new knowledge distillation objective for language representation learning that transfers the contextual knowledge via two types of relationships across representations: Word Relation and Layer Transforming Relation. Unlike other recent distillation techniques for the language models, our contextual distillation does not have any restrictions on architectural changes between teacher and student. We validate the effectiveness of our method on challenging benchmarks of language understanding tasks, not only in architectures of various sizes, but also in combination with DynaBERT, the recently proposed adaptive size pruning method.