 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Reconstruction as Supervision for Critical Thinking in LLMs
Mar 18, 2026To think critically about arguments, human learners are trained to identify, reconstruct, and evaluate arguments. Argument reconstruction is especially important because it makes an argument's underlying inferences explicit. However, it remains unclear whether LLMs can similarly enhance their critical thinking ability by learning to reconstruct arguments. To address this question, we introduce a holistic framework with three contributions. We (1) propose an engine that automatically reconstructs arbitrary arguments (GAAR), (2) synthesize a new high-quality argument reconstruction dataset (Arguinas) using the GAAR engine, and (3) investigate whether learning argument reconstruction benefits downstream critical thinking tasks. Our experimental results show that, across seven critical thinking tasks, models trained to learn argument reconstruction outperform models that do not, with the largest performance gains observed when training on the proposed Arguinas dataset. The source code and dataset will be publicly available.
Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models
May 22, 2025


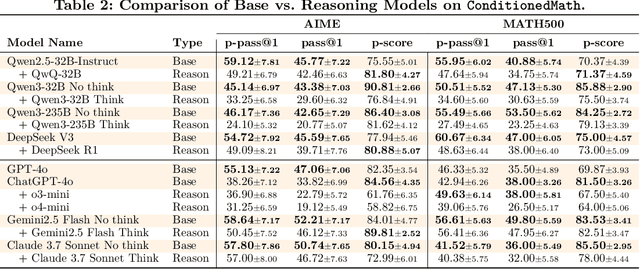
Large language models have demonstrated remarkable proficiency in long and complex reasoning tasks. However, they frequently exhibit a problematic reliance on familiar reasoning patterns, a phenomenon we term \textit{reasoning rigidity}. Despite explicit instructions from users, these models often override clearly stated conditions and default to habitual reasoning trajectories, leading to incorrect conclusions. This behavior presents significant challenges, particularly in domains such as mathematics and logic puzzle, where precise adherence to specified constraints is critical. To systematically investigate reasoning rigidity, a behavior largely unexplored in prior work, we introduce a expert-curated diagnostic set, \dataset{}. Our dataset includes specially modified variants of existing mathematical benchmarks, namely AIME and MATH500, as well as well-known puzzles deliberately redesigned to require deviation from familiar reasoning strategies. Using this dataset, we identify recurring contamination patterns that occur when models default to ingrained reasoning. Specifically, we categorize this contamination into three distinctive modes: (i) Interpretation Overload, (ii) Input Distrust, and (iii) Partial Instruction Attention, each causing models to ignore or distort provided instructions. We publicly release our diagnostic set to facilitate future research on mitigating reasoning rigidity in language models.
Closer Look at Efficient Inference Methods: A Survey of Speculative Decoding
Nov 20, 2024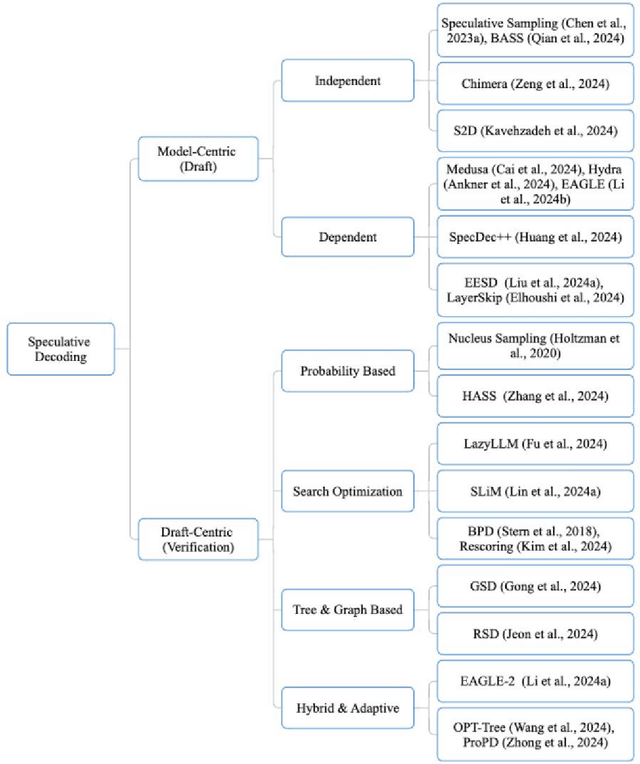
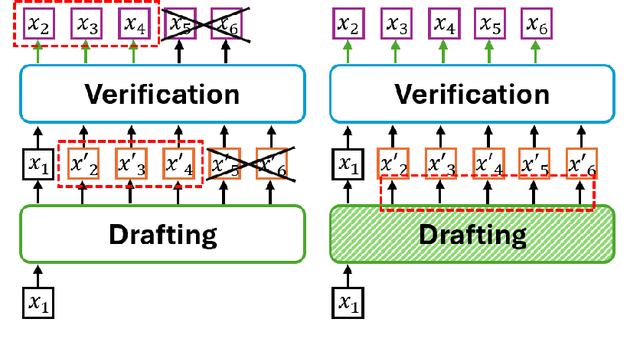
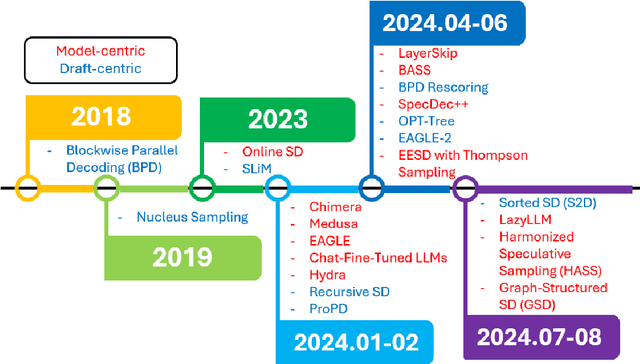
Efficient inference in large language models (LLMs) has become a critical focus as their scale and complexity grow. Traditional autoregressive decoding, while effective, suffers from computational inefficiencies due to its sequential token generation process. Speculative decoding addresses this bottleneck by introducing a two-stage framework: drafting and verification. A smaller, efficient model generates a preliminary draft, which is then refined by a larger, more sophisticated model. This paper provides a comprehensive survey of speculative decoding methods, categorizing them into draft-centric and model-centric approaches. We discuss key ideas associated with each method, highlighting their potential for scaling LLM inference. This survey aims to guide future research in optimizing speculative decoding and its integration into real-world LLM applications.
Divide and Translate: Compositional First-Order Logic Translation and Verification for Complex Logical Reasoning
Oct 10, 2024

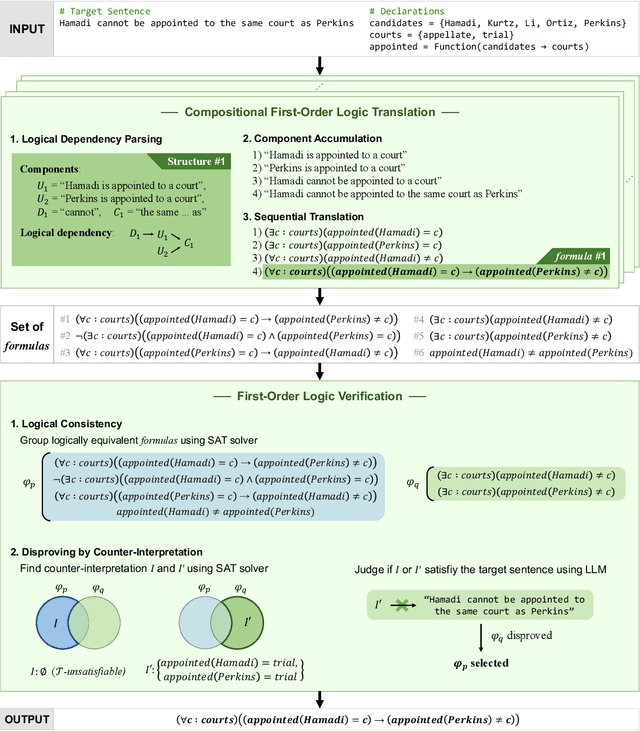
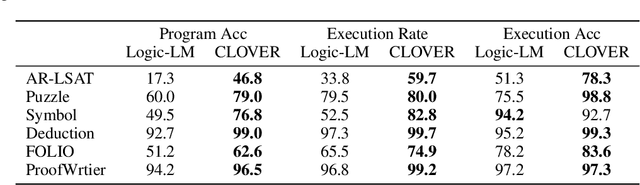
Complex logical reasoning tasks require a long sequence of reasoning, which a large language model (LLM) with chain-of-thought prompting still falls short. To alleviate this issue, neurosymbolic approaches incorporate a symbolic solver. Specifically, an LLM only translates a natural language problem into a satisfiability (SAT) problem that consists of first-order logic formulas, and a sound symbolic solver returns a mathematically correct solution. However, we discover that LLMs have difficulties to capture complex logical semantics hidden in the natural language during translation. To resolve this limitation, we propose a Compositional First-Order Logic Translation. An LLM first parses a natural language sentence into newly defined logical dependency structures that consist of an atomic subsentence and its dependents, then sequentially translate the parsed subsentences. Since multiple logical dependency structures and sequential translations are possible for a single sentence, we also introduce two Verification algorithms to ensure more reliable results. We utilize an SAT solver to rigorously compare semantics of generated first-order logic formulas and select the most probable one. We evaluate the proposed method, dubbed CLOVER, on seven logical reasoning benchmarks and show that it outperforms the previous neurosymbolic approaches and achieves new state-of-the-art results.
SimPSI: A Simple Strategy to Preserve Spectral Information in Time Series Data Augmentation
Dec 10, 2023

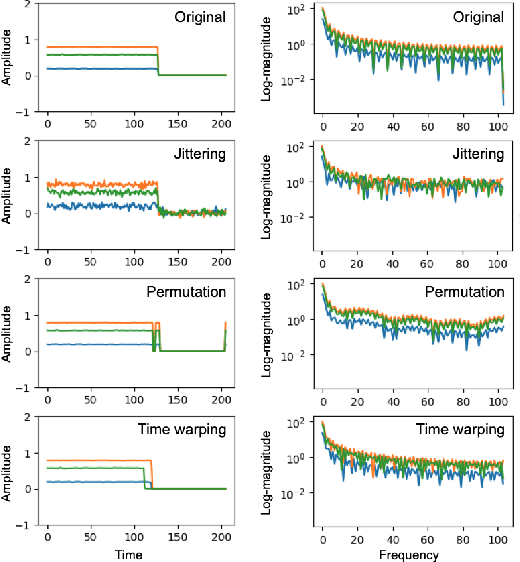

Data augmentation is a crucial component in training neural networks to overcome the limitation imposed by data size, and several techniques have been studied for time series. Although these techniques are effective in certain tasks, they have yet to be generalized to time series benchmarks. We find that current data augmentation techniques ruin the core information contained within the frequency domain. To address this issue, we propose a simple strategy to preserve spectral information (SimPSI) in time series data augmentation. SimPSI preserves the spectral information by mixing the original and augmented input spectrum weighted by a preservation map, which indicates the importance score of each frequency. Specifically, our experimental contributions are to build three distinct preservation maps: magnitude spectrum, saliency map, and spectrum-preservative map. We apply SimPSI to various time series data augmentations and evaluate its effectiveness across a wide range of time series benchmarks. Our experimental results support that SimPSI considerably enhances the performance of time series data augmentations by preserving core spectral information. The source code used in the paper is available at https://github.com/Hyun-Ryu/simpsi.
EMC2-Net: Joint Equalization and Modulation Classification based on Constellation Network
Mar 20, 2023Modulation classification (MC) is the first step performed at the receiver side unless the modulation type is explicitly indicated by the transmitter. Machine learning techniques have been widely used for MC recently. In this paper, we propose a novel MC technique dubbed as Joint Equalization and Modulation Classification based on Constellation Network (EMC2-Net). Unlike prior works that considered the constellation points as an image, the proposed EMC2-Net directly uses a set of 2D constellation points to perform MC. In order to obtain clear and concrete constellation despite multipath fading channels, the proposed EMC2-Net consists of equalizer and classifier having separate and explainable roles via novel three-phase training and noise-curriculum pretraining. Numerical results with linear modulation types under different channel models show that the proposed EMC2-Net achieves the performance of state-of-the-art MC techniques with significantly less complexity.