 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZIM: Zero-Shot Image Matting for Anything
Nov 01, 2024



The recent segmentation foundation model, Segment Anything Model (SAM), exhibits strong zero-shot segmentation capabilities, but it falls short in generating fine-grained precise masks. To address this limitation, we propose a novel zero-shot image matting model, called ZIM, with two key contributions: First, we develop a label converter that transforms segmentation labels into detailed matte labels, constructing the new SA1B-Matte dataset without costly manual annotations. Training SAM with this dataset enables it to generate precise matte masks while maintaining its zero-shot capability. Second, we design the zero-shot matting model equipped with a hierarchical pixel decoder to enhance mask representation, along with a prompt-aware masked attention mechanism to improve performance by enabling the model to focus on regions specified by visual prompts. We evaluate ZIM using the newly introduced MicroMat-3K test set, which contains high-quality micro-level matte labels. Experimental results show that ZIM outperforms existing methods in fine-grained mask generation and zero-shot generalization. Furthermore, we demonstrate the versatility of ZIM in various downstream tasks requiring precise masks, such as image inpainting and 3D NeRF. Our contributions provide a robust foundation for advancing zero-shot matting and its downstream applications across a wide range of computer vision tasks. The code is available at \url{https://github.com/naver-ai/ZIM}.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
ProxyDet: Synthesizing Proxy Novel Classes via Classwise Mixup for Open-Vocabulary Object Detection
Dec 19, 2023Open-vocabulary object detection (OVOD) aims to recognize novel objects whose categories are not included in the training set. In order to classify these unseen classes during training, many OVOD frameworks leverage the zero-shot capability of largely pretrained vision and language models, such as CLIP. To further improve generalization on the unseen novel classes, several approaches proposed to additionally train with pseudo region labeling on the external data sources that contain a substantial number of novel category labels beyond the existing training data. Albeit its simplicity, these pseudo-labeling methods still exhibit limited improvement with regard to the truly unseen novel classes that were not pseudo-labeled. In this paper, we present a novel, yet simple technique that helps generalization on the overall distribution of novel classes. Inspired by our observation that numerous novel classes reside within the convex hull constructed by the base (seen) classes in the CLIP embedding space, we propose to synthesize proxy-novel classes approximating novel classes via linear mixup between a pair of base classes. By training our detector with these synthetic proxy-novel classes, we effectively explore the embedding space of novel classes. The experimental results on various OVOD benchmarks such as LVIS and COCO demonstrate superior performance on novel classes compared to the other state-of-the-art methods. Code is available at https://github.com/clovaai/ProxyDet.
LIFT-CAM: Towards Better Explanations for Class Activation Mapping
Feb 10, 2021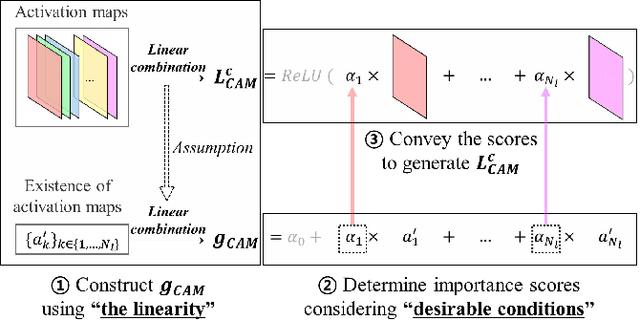

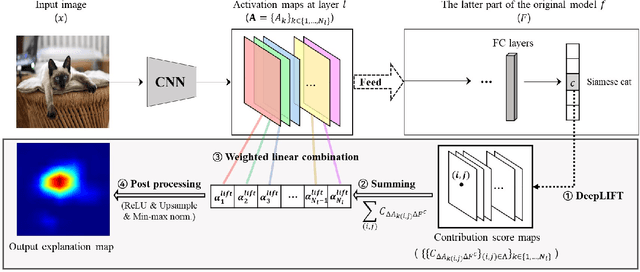
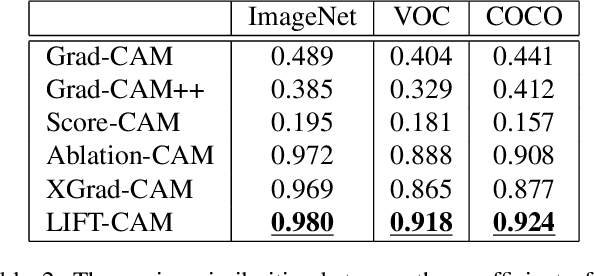
Increasing demands for understanding the internal behaviors of convolutional neural networks (CNNs) have led to remarkable improvements in explanation methods. Particularly, several class activation mapping (CAM) based methods, which generate visual explanation maps by a linear combination of activation maps from CNNs, have been proposed. However, the majority of the methods lack a theoretical basis in how to assign their weighted linear coefficients. In this paper, we revisit the intrinsic linearity of CAM w.r.t. the activation maps. Focusing on the linearity, we construct an explanation model as a linear function of binary variables which denote the existence of the corresponding activation maps. With this approach, the explanation model can be determined by the class of additive feature attribution methods which adopts SHAP values as a unified measure of feature importance. We then demonstrate the efficacy of the SHAP values as the weight coefficients for CAM. However, the exact SHAP values are incalculable. Hence, we introduce an efficient approximation method, referred to as LIFT-CAM. On the basis of DeepLIFT, our proposed method can estimate the true SHAP values quickly and accurately. Furthermore, it achieves better performances than the other previous CAM-based methods in qualitative and quantitative aspects.