 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEEN: Sharpening Explanations for Graph Neural Networks using Explanations from Neighborhoods
Jun 16, 2021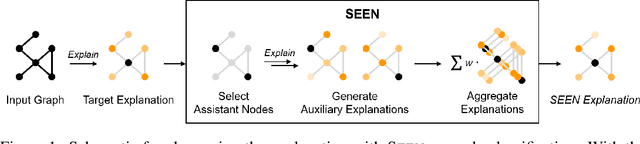



Explaining the foundations for predictions obtained from graph neural networks (GNNs) is critical for credible use of GNN models for real-world problems. Owing to the rapid growth of GNN applications, recent progress in explaining predictions from GNNs, such as sensitivity analysis, perturbation methods, and attribution methods, showed great opportunities and possibilities for explaining GNN predictions. In this study, we propose a method to improve the explanation quality of node classification tasks that can be applied in a post hoc manner through aggregation of auxiliary explanations from important neighboring nodes, named SEEN. Applying SEEN does not require modification of a graph and can be used with diverse explainability techniques due to its independent mechanism. Experiments on matching motif-participating nodes from a given graph show great improvement in explanation accuracy of up to 12.71% and demonstrate the correlation between the auxiliary explanations and the enhanced explanation accuracy through leveraging their contributions. SEEN provides a simple but effective method to enhance the explanation quality of GNN model outputs, and this method is applicable in combination with most explainability techniques.
LIFT-CAM: Towards Better Explanations for Class Activation Mapping
Feb 10, 2021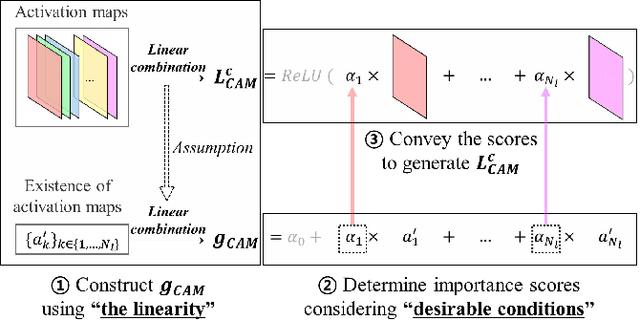

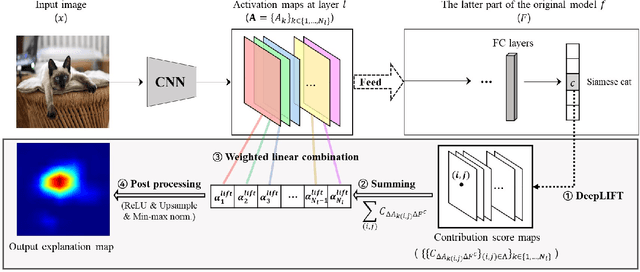
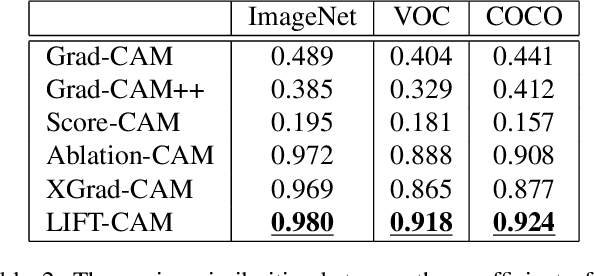
Increasing demands for understanding the internal behaviors of convolutional neural networks (CNNs) have led to remarkable improvements in explanation methods. Particularly, several class activation mapping (CAM) based methods, which generate visual explanation maps by a linear combination of activation maps from CNNs, have been proposed. However, the majority of the methods lack a theoretical basis in how to assign their weighted linear coefficients. In this paper, we revisit the intrinsic linearity of CAM w.r.t. the activation maps. Focusing on the linearity, we construct an explanation model as a linear function of binary variables which denote the existence of the corresponding activation maps. With this approach, the explanation model can be determined by the class of additive feature attribution methods which adopts SHAP values as a unified measure of feature importance. We then demonstrate the efficacy of the SHAP values as the weight coefficients for CAM. However, the exact SHAP values are incalculable. Hence, we introduce an efficient approximation method, referred to as LIFT-CAM. On the basis of DeepLIFT, our proposed method can estimate the true SHAP values quickly and accurately. Furthermore, it achieves better performances than the other previous CAM-based methods in qualitative and quantitative aspects.