 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZIM: Zero-Shot Image Matting for Anything
Nov 01, 2024



The recent segmentation foundation model, Segment Anything Model (SAM), exhibits strong zero-shot segmentation capabilities, but it falls short in generating fine-grained precise masks. To address this limitation, we propose a novel zero-shot image matting model, called ZIM, with two key contributions: First, we develop a label converter that transforms segmentation labels into detailed matte labels, constructing the new SA1B-Matte dataset without costly manual annotations. Training SAM with this dataset enables it to generate precise matte masks while maintaining its zero-shot capability. Second, we design the zero-shot matting model equipped with a hierarchical pixel decoder to enhance mask representation, along with a prompt-aware masked attention mechanism to improve performance by enabling the model to focus on regions specified by visual prompts. We evaluate ZIM using the newly introduced MicroMat-3K test set, which contains high-quality micro-level matte labels. Experimental results show that ZIM outperforms existing methods in fine-grained mask generation and zero-shot generalization. Furthermore, we demonstrate the versatility of ZIM in various downstream tasks requiring precise masks, such as image inpainting and 3D NeRF. Our contributions provide a robust foundation for advancing zero-shot matting and its downstream applications across a wide range of computer vision tasks. The code is available at \url{https://github.com/naver-ai/ZIM}.
EGformer: Equirectangular Geometry-biased Transformer for 360 Depth Estimation
Apr 16, 2023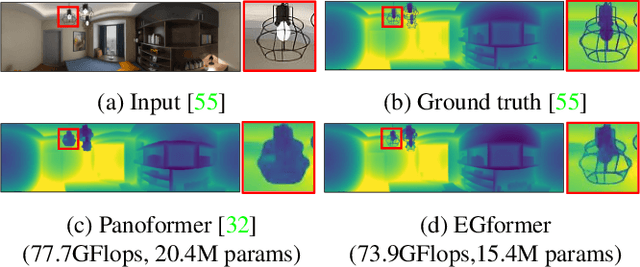



Estimating the depths of equirectangular (360) images (EIs) is challenging given the distorted 180 x 360 field-of-view, which is hard to be addressed via convolutional neural network (CNN). Although a transformer with global attention achieves significant improvements over CNN for EI depth estimation task, it is computationally inefficient, which raises the need for transformer with local attention. However, to apply local attention successfully for EIs, a specific strategy, which addresses distorted equirectangular geometry and limited receptive field simultaneously, is required. Prior works have only cared either of them, resulting in unsatisfactory depths occasionally. In this paper, we propose an equirectangular geometry-biased transformer termed EGformer, which enables local attention extraction in a global manner considering the equirectangular geometry. To achieve this, we actively utilize the equirectangular geometry as the bias for the local attention instead of struggling to reduce the distortion of EIs. As compared to the most recent transformer based EI depth estimation studies, the proposed approach yields the best depth outcomes overall with the lowest computational cost and the fewest parameters, demonstrating the effectiveness of the proposed methods.