 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisfusion: Parallel ASR Decoding via a Diffusion Transformer
Aug 09, 2025Fast Automatic Speech Recognition (ASR) is critical for latency-sensitive applications such as real-time captioning and meeting transcription. However, truly parallel ASR decoding remains challenging due to the sequential nature of autoregressive (AR) decoders and the context limitations of non-autoregressive (NAR) methods. While modern ASR encoders can process up to 30 seconds of audio at once, AR decoders still generate tokens sequentially, creating a latency bottleneck. We propose Whisfusion, the first framework to fuse a pre-trained Whisper encoder with a text diffusion decoder. This NAR architecture resolves the AR latency bottleneck by processing the entire acoustic context in parallel at every decoding step. A lightweight cross-attention adapter trained via parameter-efficient fine-tuning (PEFT) bridges the two modalities. We also introduce a batch-parallel, multi-step decoding strategy that improves accuracy by increasing the number of candidates with minimal impact on speed. Fine-tuned solely on LibriSpeech (960h), Whisfusion achieves a lower WER than Whisper-tiny (8.3% vs. 9.7%), and offers comparable latency on short audio. For longer utterances (>20s), it is up to 2.6x faster than the AR baseline, establishing a new, efficient operating point for long-form ASR. The implementation and training scripts are available at https://github.com/taeyoun811/Whisfusion.
MathSpeech: Leveraging Small LMs for Accurate Conversion in Mathematical Speech-to-Formula
Dec 20, 2024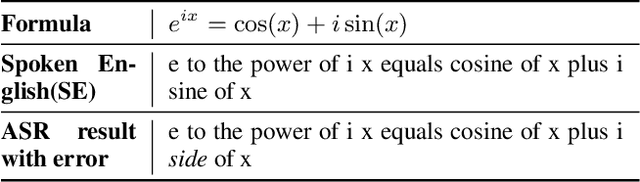
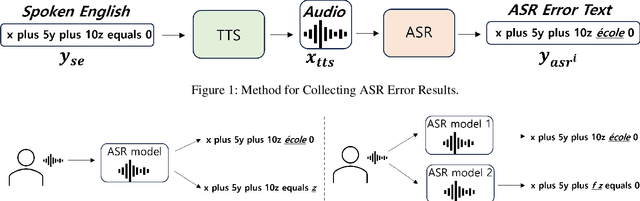
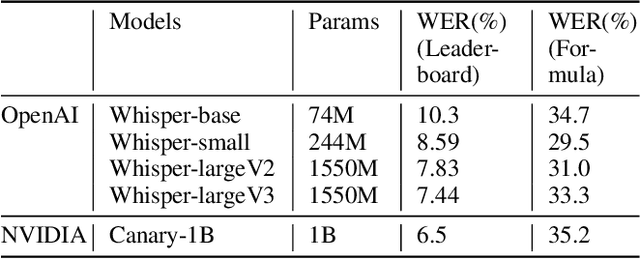

In various academic and professional settings, such as mathematics lectures or research presentations, it is often necessary to convey mathematical expressions orally. However, reading mathematical expressions aloud without accompanying visuals can significantly hinder comprehension, especially for those who are hearing-impaired or rely on subtitles due to language barriers. For instance, when a presenter reads Euler's Formula, current Automatic Speech Recognition (ASR) models often produce a verbose and error-prone textual description (e.g., e to the power of i x equals cosine of x plus i $\textit{side}$ of x), instead of the concise $\LaTeX{}$ format (i.e., $ e^{ix} = \cos(x) + i\sin(x) $), which hampers clear understanding and communication. To address this issue, we introduce MathSpeech, a novel pipeline that integrates ASR models with small Language Models (sLMs) to correct errors in mathematical expressions and accurately convert spoken expressions into structured $\LaTeX{}$ representations. Evaluated on a new dataset derived from lecture recordings, MathSpeech demonstrates $\LaTeX{}$ generation capabilities comparable to leading commercial Large Language Models (LLMs), while leveraging fine-tuned small language models of only 120M parameters. Specifically, in terms of CER, BLEU, and ROUGE scores for $\LaTeX{}$ translation, MathSpeech demonstrated significantly superior capabilities compared to GPT-4o. We observed a decrease in CER from 0.390 to 0.298, and higher ROUGE/BLEU scores compared to GPT-4o.
MathBridge: A Large Corpus Dataset for Translating Spoken Mathematical Expressions into $LaTeX$ Formulas for Improved Readability
Aug 15, 2024



Understanding sentences that contain mathematical expressions in text form poses significant challenges. To address this, the importance of converting these expressions into a compiled formula is highlighted. For instance, the expression ``x equals minus b plus or minus the square root of b squared minus four a c, all over two a'' from automatic speech recognition (ASR) is more readily comprehensible when displayed as a compiled formula $x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$. To develop a text-to-formula conversion system, we can break down the process into text-to-LaTeX and LaTeX-to-formula conversions, with the latter managed by various existing LaTeX engines. However, the former approach has been notably hindered by the severe scarcity of text-to-LaTeX paired data, which presents a significant challenge in this field. In this context, we introduce MathBridge, the first extensive dataset for translating mathematical spoken expressions into LaTeX, to establish a robust baseline for future research on text-to-LaTeX translation. MathBridge comprises approximately 23 million LaTeX formulas paired with the corresponding spoken English expressions. Through comprehensive evaluations, including fine-tuning and testing with data, we discovered that MathBridge significantly enhances the capabilities of pretrained language models for text-to-LaTeX translation. Specifically, for the T5-large model, the sacreBLEU score increased from 4.77 to 46.8, demonstrating substantial enhancement. Our findings indicate the need for a new metric, specifically for text-to-LaTeX conversion evaluations.
MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models
May 29, 2024Mixture-of-Experts (MoE) large language models (LLM) have memory requirements that often exceed the GPU memory capacity, requiring costly parameter movement from secondary memories to the GPU for expert computation. In this work, we present Mixture of Near-Data Experts (MoNDE), a near-data computing solution that efficiently enables MoE LLM inference. MoNDE reduces the volume of MoE parameter movement by transferring only the $\textit{hot}$ experts to the GPU, while computing the remaining $\textit{cold}$ experts inside the host memory device. By replacing the transfers of massive expert parameters with the ones of small activations, MoNDE enables far more communication-efficient MoE inference, thereby resulting in substantial speedups over the existing parameter offloading frameworks for both encoder and decoder operations.
HEAM : Hashed Embedding Acceleration using Processing-In-Memory
Feb 21, 2024In today's data centers, personalized recommendation systems face challenges such as the need for large memory capacity and high bandwidth, especially when performing embedding operations. Previous approaches have relied on DIMM-based near-memory processing techniques or introduced 3D-stacked DRAM to address memory-bound issues and expand memory bandwidth. However, these solutions fall short when dealing with the expanding size of personalized recommendation systems. Recommendation models have grown to sizes exceeding tens of terabytes, making them challenging to run efficiently on traditional single-node inference servers. Although various algorithmic methods have been proposed to reduce embedding table capacity, they often result in increased memory access or inefficient utilization of memory resources. This paper introduces HEAM, a heterogeneous memory architecture that integrates 3D-stacked DRAM with DIMM to accelerate recommendation systems in which compositional embedding is utilized-a technique aimed at reducing the size of embedding tables. The architecture is organized into a three-tier memory hierarchy consisting of conventional DIMM, 3D-stacked DRAM with a base die-level Processing-In-Memory (PIM), and a bank group-level PIM incorporating a Look-Up-Table. This setup is specifically designed to accommodate the unique aspects of compositional embedding, such as temporal locality and embedding table capacity. This design effectively reduces bank access, improves access efficiency, and enhances overall throughput, resulting in a 6.3 times speedup and 58.9% energy savings compared to the baseline.
EGformer: Equirectangular Geometry-biased Transformer for 360 Depth Estimation
Apr 16, 2023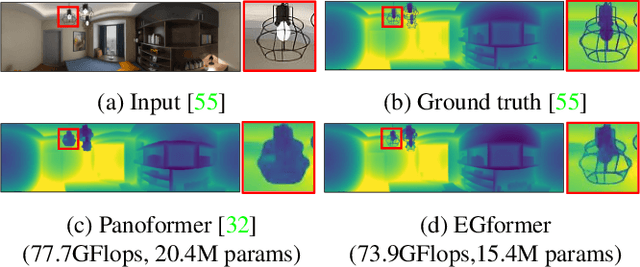



Estimating the depths of equirectangular (360) images (EIs) is challenging given the distorted 180 x 360 field-of-view, which is hard to be addressed via convolutional neural network (CNN). Although a transformer with global attention achieves significant improvements over CNN for EI depth estimation task, it is computationally inefficient, which raises the need for transformer with local attention. However, to apply local attention successfully for EIs, a specific strategy, which addresses distorted equirectangular geometry and limited receptive field simultaneously, is required. Prior works have only cared either of them, resulting in unsatisfactory depths occasionally. In this paper, we propose an equirectangular geometry-biased transformer termed EGformer, which enables local attention extraction in a global manner considering the equirectangular geometry. To achieve this, we actively utilize the equirectangular geometry as the bias for the local attention instead of struggling to reduce the distortion of EIs. As compared to the most recent transformer based EI depth estimation studies, the proposed approach yields the best depth outcomes overall with the lowest computational cost and the fewest parameters, demonstrating the effectiveness of the proposed methods.
Improving 360 Monocular Depth Estimation via Non-local Dense Prediction Transformer and Joint Supervised and Self-supervised Learning
Sep 23, 2021
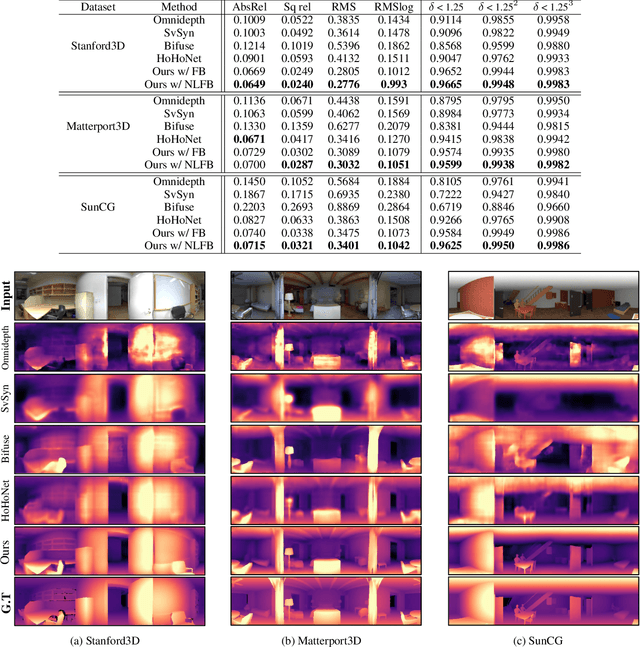
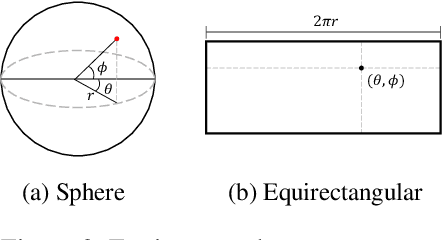

Due to difficulties in acquiring ground truth depth of equirectangular (360) images, the quality and quantity of equirectangular depth data today is insufficient to represent the various scenes in the world. Therefore, 360 depth estimation studies, which relied solely on supervised learning, are destined to produce unsatisfactory results. Although self-supervised learning methods focusing on equirectangular images (EIs) are introduced, they often have incorrect or non-unique solutions, causing unstable performance. In this paper, we propose 360 monocular depth estimation methods which improve on the areas that limited previous studies. First, we introduce a self-supervised 360 depth learning method that only utilizes gravity-aligned videos, which has the potential to eliminate the needs for depth data during the training procedure. Second, we propose a joint learning scheme realized by combining supervised and self-supervised learning. The weakness of each learning is compensated, thus leading to more accurate depth estimation. Third, we propose a non-local fusion block, which retains global information encoded by vision transformer when reconstructing the depths. With the proposed methods, we successfully apply the transformer to 360 depth estimations, to the best of our knowledge, which has not been tried before. On several benchmarks, our approach achieves significant improvements over previous works and establishes a state of the art.
Active Learning for Deep Object Detection via Probabilistic Modeling
Mar 30, 2021



Active learning aims to reduce labeling costs by selecting only the most informative samples on a dataset. Few existing works have addressed active learning for object detection. Most of these methods are based on multiple models or are straightforward extensions of classification methods, hence estimate an image's informativeness using only the classification head. In this paper, we propose a novel deep active learning approach for object detection. Our approach relies on mixture density networks that estimate a probabilistic distribution for each localization and classification head's output. We explicitly estimate the aleatoric and epistemic uncertainty in a single forward pass of a single model. Our method uses a scoring function that aggregates these two types of uncertainties for both heads to obtain every image's informativeness score. We demonstrate the efficacy of our approach in PASCAL VOC and MS-COCO datasets. Our approach outperforms single-model based methods and performs on par with multi-model based methods at a fraction of the computing cost.
GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent
Feb 15, 2021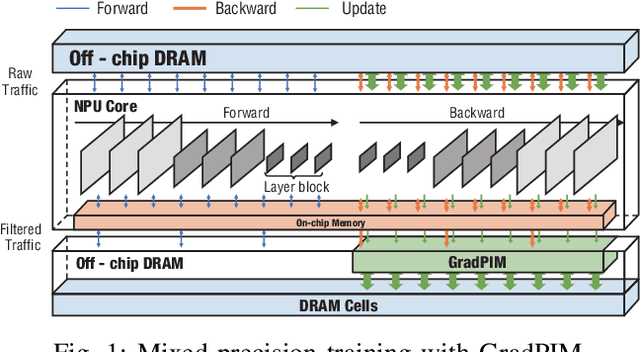
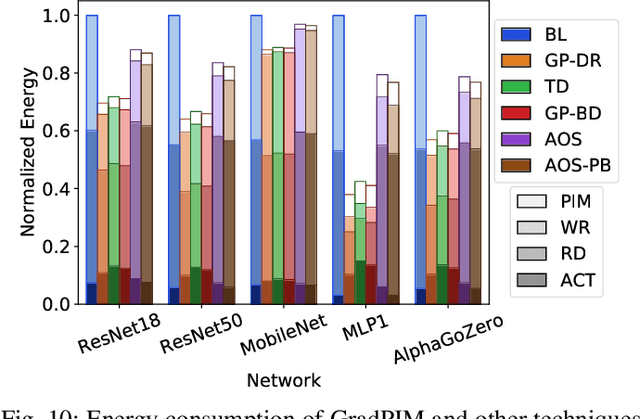
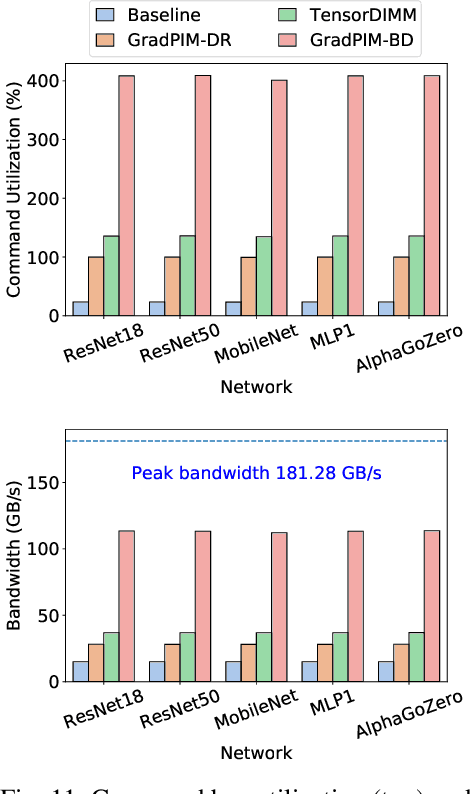
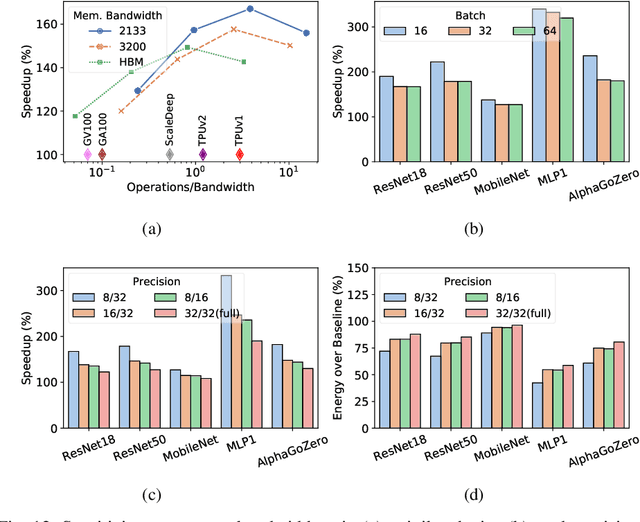
In this paper, we present GradPIM, a processing-in-memory architecture which accelerates parameter updates of deep neural networks training. As one of processing-in-memory techniques that could be realized in the near future, we propose an incremental, simple architectural design that does not invade the existing memory protocol. Extending DDR4 SDRAM to utilize bank-group parallelism makes our operation designs in processing-in-memory (PIM) module efficient in terms of hardware cost and performance. Our experimental results show that the proposed architecture can improve the performance of DNN training and greatly reduce memory bandwidth requirement while posing only a minimal amount of overhead to the protocol and DRAM area.
Layer-specific Optimization for Mixed Data Flow with Mixed Precision in FPGA Design for CNN-based Object Detectors
Sep 03, 2020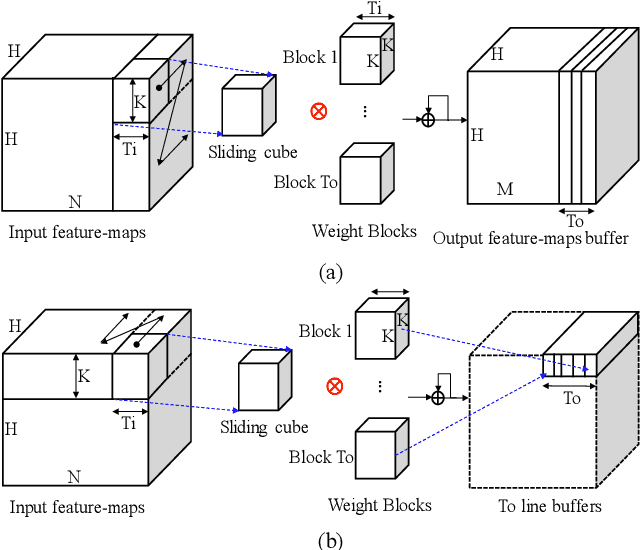
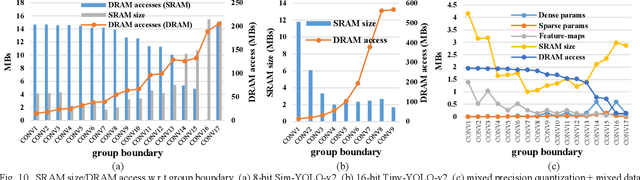
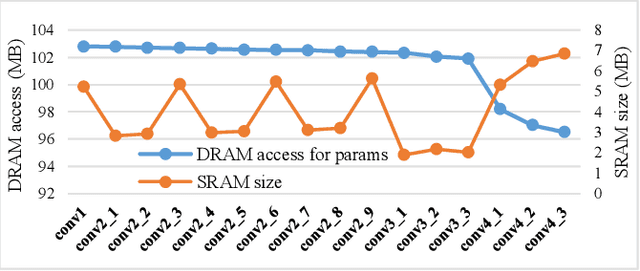
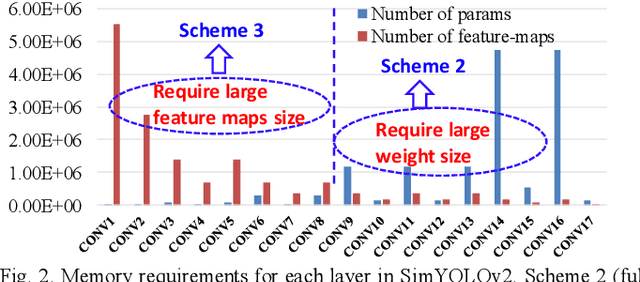
Convolutional neural networks (CNNs) require both intensive computation and frequent memory access, which lead to a low processing speed and large power dissipation. Although the characteristics of the different layers in a CNN are frequently quite different, previous hardware designs have employed common optimization schemes for them. This paper proposes a layer-specific design that employs different organizations that are optimized for the different layers. The proposed design employs two layer-specific optimizations: layer-specific mixed data flow and layer-specific mixed precision. The mixed data flow aims to minimize the off-chip access while demanding a minimal on-chip memory (BRAM) resource of an FPGA device. The mixed precision quantization is to achieve both a lossless accuracy and an aggressive model compression, thereby further reducing the off-chip access. A Bayesian optimization approach is used to select the best sparsity for each layer, achieving the best trade-off between the accuracy and compression. This mixing scheme allows the entire network model to be stored in BRAMs of the FPGA to aggressively reduce the off-chip access, and thereby achieves a significant performance enhancement. The model size is reduced by 22.66-28.93 times compared to that in a full-precision network with a negligible degradation of accuracy on VOC, COCO, and ImageNet datasets. Furthermore, the combination of mixed dataflow and mixed precision significantly outperforms the previous works in terms of both throughput, off-chip access, and on-chip memory requirement.