 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAM : Hashed Embedding Acceleration using Processing-In-Memory
Feb 21, 2024
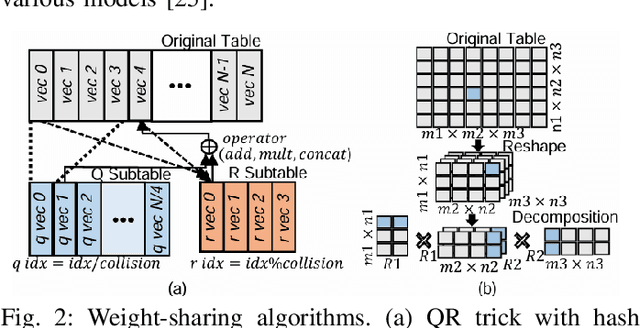


In today's data centers, personalized recommendation systems face challenges such as the need for large memory capacity and high bandwidth, especially when performing embedding operations. Previous approaches have relied on DIMM-based near-memory processing techniques or introduced 3D-stacked DRAM to address memory-bound issues and expand memory bandwidth. However, these solutions fall short when dealing with the expanding size of personalized recommendation systems. Recommendation models have grown to sizes exceeding tens of terabytes, making them challenging to run efficiently on traditional single-node inference servers. Although various algorithmic methods have been proposed to reduce embedding table capacity, they often result in increased memory access or inefficient utilization of memory resources. This paper introduces HEAM, a heterogeneous memory architecture that integrates 3D-stacked DRAM with DIMM to accelerate recommendation systems in which compositional embedding is utilized-a technique aimed at reducing the size of embedding tables. The architecture is organized into a three-tier memory hierarchy consisting of conventional DIMM, 3D-stacked DRAM with a base die-level Processing-In-Memory (PIM), and a bank group-level PIM incorporating a Look-Up-Table. This setup is specifically designed to accommodate the unique aspects of compositional embedding, such as temporal locality and embedding table capacity. This design effectively reduces bank access, improves access efficiency, and enhances overall throughput, resulting in a 6.3 times speedup and 58.9% energy savings compared to the baseline.
EGformer: Equirectangular Geometry-biased Transformer for 360 Depth Estimation
Apr 16, 2023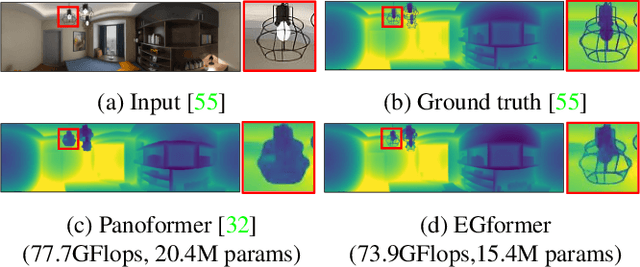



Estimating the depths of equirectangular (360) images (EIs) is challenging given the distorted 180 x 360 field-of-view, which is hard to be addressed via convolutional neural network (CNN). Although a transformer with global attention achieves significant improvements over CNN for EI depth estimation task, it is computationally inefficient, which raises the need for transformer with local attention. However, to apply local attention successfully for EIs, a specific strategy, which addresses distorted equirectangular geometry and limited receptive field simultaneously, is required. Prior works have only cared either of them, resulting in unsatisfactory depths occasionally. In this paper, we propose an equirectangular geometry-biased transformer termed EGformer, which enables local attention extraction in a global manner considering the equirectangular geometry. To achieve this, we actively utilize the equirectangular geometry as the bias for the local attention instead of struggling to reduce the distortion of EIs. As compared to the most recent transformer based EI depth estimation studies, the proposed approach yields the best depth outcomes overall with the lowest computational cost and the fewest parameters, demonstrating the effectiveness of the proposed methods.
Improving 360 Monocular Depth Estimation via Non-local Dense Prediction Transformer and Joint Supervised and Self-supervised Learning
Sep 23, 2021
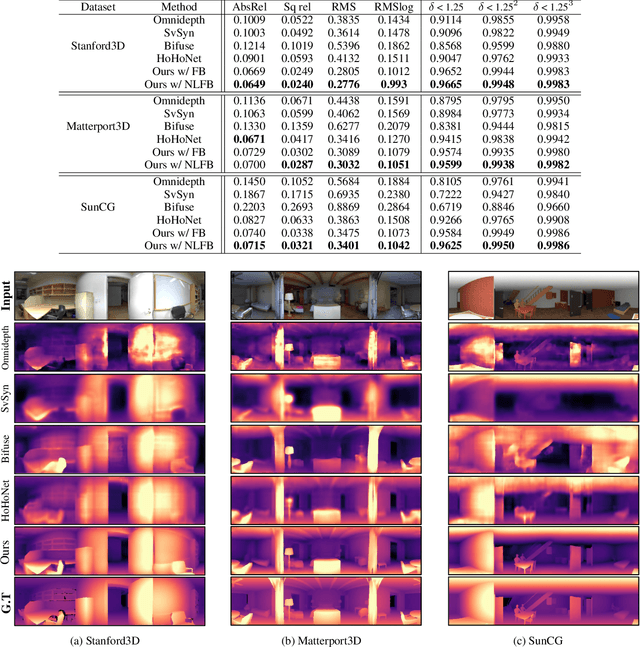
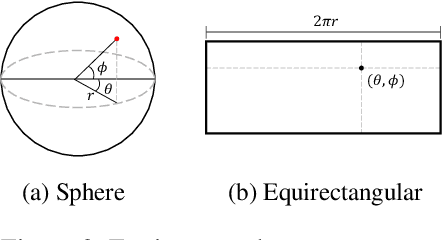

Due to difficulties in acquiring ground truth depth of equirectangular (360) images, the quality and quantity of equirectangular depth data today is insufficient to represent the various scenes in the world. Therefore, 360 depth estimation studies, which relied solely on supervised learning, are destined to produce unsatisfactory results. Although self-supervised learning methods focusing on equirectangular images (EIs) are introduced, they often have incorrect or non-unique solutions, causing unstable performance. In this paper, we propose 360 monocular depth estimation methods which improve on the areas that limited previous studies. First, we introduce a self-supervised 360 depth learning method that only utilizes gravity-aligned videos, which has the potential to eliminate the needs for depth data during the training procedure. Second, we propose a joint learning scheme realized by combining supervised and self-supervised learning. The weakness of each learning is compensated, thus leading to more accurate depth estimation. Third, we propose a non-local fusion block, which retains global information encoded by vision transformer when reconstructing the depths. With the proposed methods, we successfully apply the transformer to 360 depth estimations, to the best of our knowledge, which has not been tried before. On several benchmarks, our approach achieves significant improvements over previous works and establishes a state of the art.