 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 360 Monocular Depth Estimation via Non-local Dense Prediction Transformer and Joint Supervised and Self-supervised Learning
Paper and Code
Sep 23, 2021
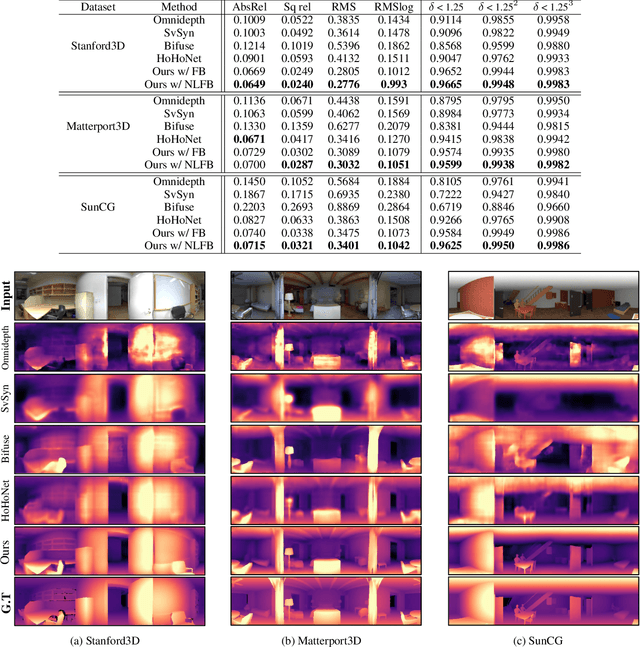

Due to difficulties in acquiring ground truth depth of equirectangular (360) images, the quality and quantity of equirectangular depth data today is insufficient to represent the various scenes in the world. Therefore, 360 depth estimation studies, which relied solely on supervised learning, are destined to produce unsatisfactory results. Although self-supervised learning methods focusing on equirectangular images (EIs) are introduced, they often have incorrect or non-unique solutions, causing unstable performance. In this paper, we propose 360 monocular depth estimation methods which improve on the areas that limited previous studies. First, we introduce a self-supervised 360 depth learning method that only utilizes gravity-aligned videos, which has the potential to eliminate the needs for depth data during the training procedure. Second, we propose a joint learning scheme realized by combining supervised and self-supervised learning. The weakness of each learning is compensated, thus leading to more accurate depth estimation. Third, we propose a non-local fusion block, which retains global information encoded by vision transformer when reconstructing the depths. With the proposed methods, we successfully apply the transformer to 360 depth estimations, to the best of our knowledge, which has not been tried before. On several benchmarks, our approach achieves significant improvements over previous works and establishes a state of the art.