 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisfusion: Parallel ASR Decoding via a Diffusion Transformer
Aug 09, 2025Fast Automatic Speech Recognition (ASR) is critical for latency-sensitive applications such as real-time captioning and meeting transcription. However, truly parallel ASR decoding remains challenging due to the sequential nature of autoregressive (AR) decoders and the context limitations of non-autoregressive (NAR) methods. While modern ASR encoders can process up to 30 seconds of audio at once, AR decoders still generate tokens sequentially, creating a latency bottleneck. We propose Whisfusion, the first framework to fuse a pre-trained Whisper encoder with a text diffusion decoder. This NAR architecture resolves the AR latency bottleneck by processing the entire acoustic context in parallel at every decoding step. A lightweight cross-attention adapter trained via parameter-efficient fine-tuning (PEFT) bridges the two modalities. We also introduce a batch-parallel, multi-step decoding strategy that improves accuracy by increasing the number of candidates with minimal impact on speed. Fine-tuned solely on LibriSpeech (960h), Whisfusion achieves a lower WER than Whisper-tiny (8.3% vs. 9.7%), and offers comparable latency on short audio. For longer utterances (>20s), it is up to 2.6x faster than the AR baseline, establishing a new, efficient operating point for long-form ASR. The implementation and training scripts are available at https://github.com/taeyoun811/Whisfusion.
MathReader : Text-to-Speech for Mathematical Documents
Jan 13, 2025



TTS (Text-to-Speech) document reader from Microsoft, Adobe, Apple, and OpenAI have been serviced worldwide. They provide relatively good TTS results for general plain text, but sometimes skip contents or provide unsatisfactory results for mathematical expressions. This is because most modern academic papers are written in LaTeX, and when LaTeX formulas are compiled, they are rendered as distinctive text forms within the document. However, traditional TTS document readers output only the text as it is recognized, without considering the mathematical meaning of the formulas. To address this issue, we propose MathReader, which effectively integrates OCR, a fine-tuned T5 model, and TTS. MathReader demonstrated a lower Word Error Rate (WER) than existing TTS document readers, such as Microsoft Edge and Adobe Acrobat, when processing documents containing mathematical formulas. MathReader reduced the WER from 0.510 to 0.281 compared to Microsoft Edge, and from 0.617 to 0.281 compared to Adobe Acrobat. This will significantly contribute to alleviating the inconvenience faced by users who want to listen to documents, especially those who are visually impaired. The code is available at https://github.com/hyeonsieun/MathReader.
MathSpeech: Leveraging Small LMs for Accurate Conversion in Mathematical Speech-to-Formula
Dec 20, 2024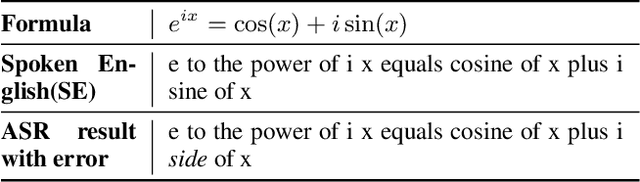
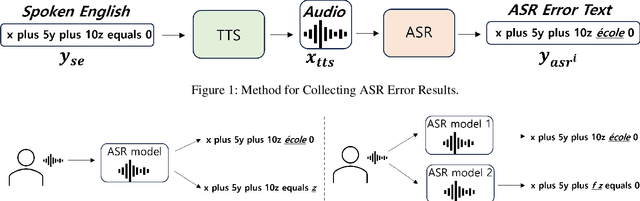
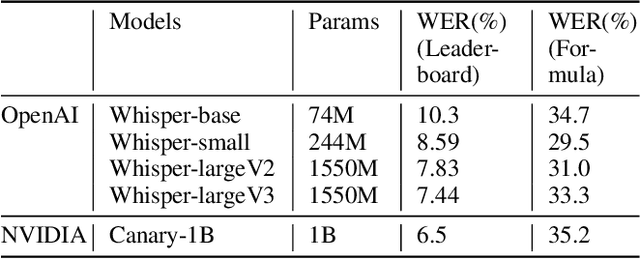

In various academic and professional settings, such as mathematics lectures or research presentations, it is often necessary to convey mathematical expressions orally. However, reading mathematical expressions aloud without accompanying visuals can significantly hinder comprehension, especially for those who are hearing-impaired or rely on subtitles due to language barriers. For instance, when a presenter reads Euler's Formula, current Automatic Speech Recognition (ASR) models often produce a verbose and error-prone textual description (e.g., e to the power of i x equals cosine of x plus i $\textit{side}$ of x), instead of the concise $\LaTeX{}$ format (i.e., $ e^{ix} = \cos(x) + i\sin(x) $), which hampers clear understanding and communication. To address this issue, we introduce MathSpeech, a novel pipeline that integrates ASR models with small Language Models (sLMs) to correct errors in mathematical expressions and accurately convert spoken expressions into structured $\LaTeX{}$ representations. Evaluated on a new dataset derived from lecture recordings, MathSpeech demonstrates $\LaTeX{}$ generation capabilities comparable to leading commercial Large Language Models (LLMs), while leveraging fine-tuned small language models of only 120M parameters. Specifically, in terms of CER, BLEU, and ROUGE scores for $\LaTeX{}$ translation, MathSpeech demonstrated significantly superior capabilities compared to GPT-4o. We observed a decrease in CER from 0.390 to 0.298, and higher ROUGE/BLEU scores compared to GPT-4o.
MathBridge: A Large Corpus Dataset for Translating Spoken Mathematical Expressions into $LaTeX$ Formulas for Improved Readability
Aug 15, 2024



Understanding sentences that contain mathematical expressions in text form poses significant challenges. To address this, the importance of converting these expressions into a compiled formula is highlighted. For instance, the expression ``x equals minus b plus or minus the square root of b squared minus four a c, all over two a'' from automatic speech recognition (ASR) is more readily comprehensible when displayed as a compiled formula $x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$. To develop a text-to-formula conversion system, we can break down the process into text-to-LaTeX and LaTeX-to-formula conversions, with the latter managed by various existing LaTeX engines. However, the former approach has been notably hindered by the severe scarcity of text-to-LaTeX paired data, which presents a significant challenge in this field. In this context, we introduce MathBridge, the first extensive dataset for translating mathematical spoken expressions into LaTeX, to establish a robust baseline for future research on text-to-LaTeX translation. MathBridge comprises approximately 23 million LaTeX formulas paired with the corresponding spoken English expressions. Through comprehensive evaluations, including fine-tuning and testing with data, we discovered that MathBridge significantly enhances the capabilities of pretrained language models for text-to-LaTeX translation. Specifically, for the T5-large model, the sacreBLEU score increased from 4.77 to 46.8, demonstrating substantial enhancement. Our findings indicate the need for a new metric, specifically for text-to-LaTeX conversion evaluations.
Mathematical Vocoder Algorithm : Modified Spectral Inversion for Efficient Neural Speech Synthesis
Jun 16, 2021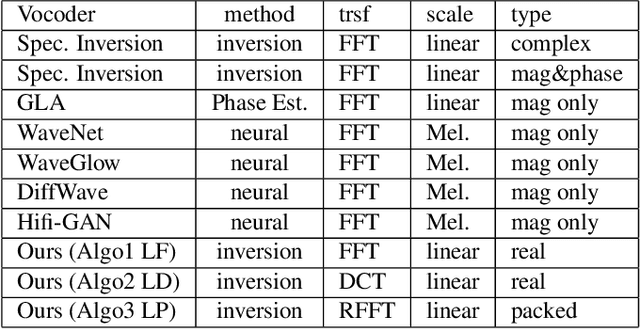
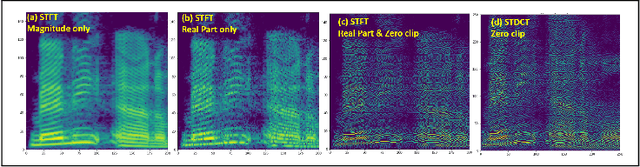
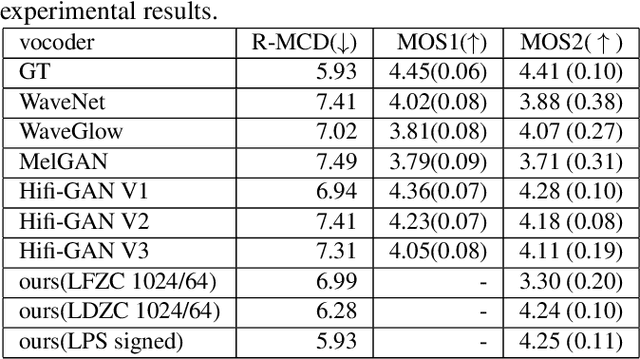
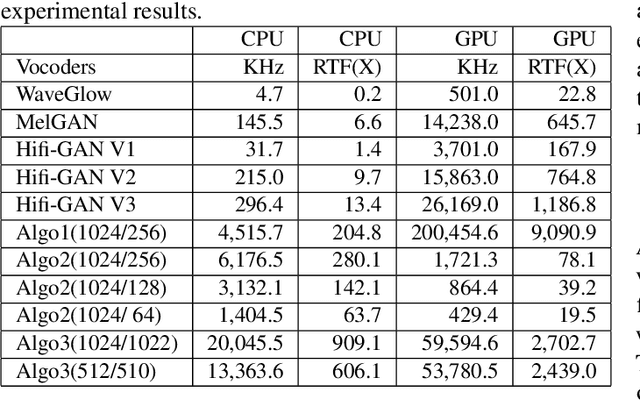
In this work, we propose a new mathematical vocoder algorithm(modified spectral inversion) that generates a waveform from acoustic features without phase estimation. The main benefit of using our proposed method is that it excludes the training stage of the neural vocoder from the end-to-end speech synthesis model. Our implementation can synthesize high fidelity speech at approximately 20 Mhz on CPU and 59.6MHz on GPU. This is 909 and 2,702 times faster compared to real-time. Since the proposed methodology is not a data-driven method, it is applicable to unseen voices and multiple languages without any additional work. The proposed method is expected to adapt for researching on neural network models capable of synthesizing speech at the studio recording level.