 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Vocoder Algorithm : Modified Spectral Inversion for Efficient Neural Speech Synthesis
Paper and Code
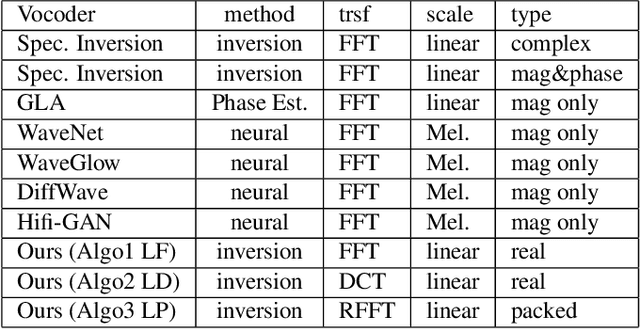
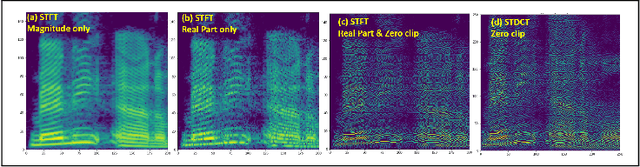
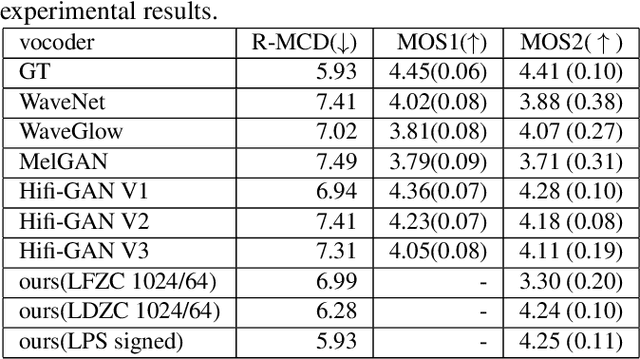
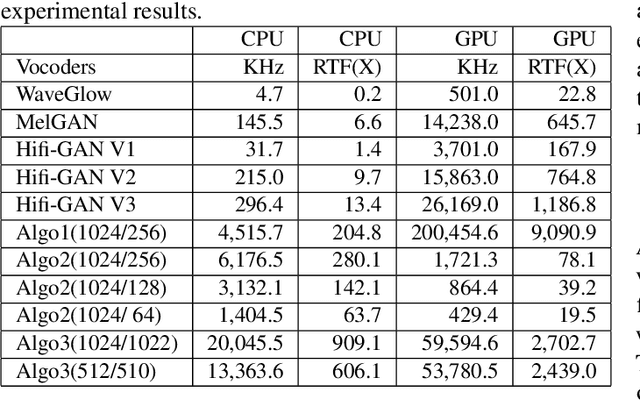
In this work, we propose a new mathematical vocoder algorithm(modified spectral inversion) that generates a waveform from acoustic features without phase estimation. The main benefit of using our proposed method is that it excludes the training stage of the neural vocoder from the end-to-end speech synthesis model. Our implementation can synthesize high fidelity speech at approximately 20 Mhz on CPU and 59.6MHz on GPU. This is 909 and 2,702 times faster compared to real-time. Since the proposed methodology is not a data-driven method, it is applicable to unseen voices and multiple languages without any additional work. The proposed method is expected to adapt for researching on neural network models capable of synthesizing speech at the studio recording level.