 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Blueprints: Generating Isomorphic Mathematics Problems with Large Language Models
Nov 11, 2025Personalized mathematics education is growing rapidly, creating a strong demand for large sets of similar practice problems. Yet existing studies on mathematics problem generation have focused on data augmentation for training neural language models rather than on direct educational deployment. To bridge this gap, we define a new task, Isomorphic Math Problem Generation (IMPG), designed to produce structurally consistent variants of source problems. Subsequently, we explored LLM-based frameworks for automatic IMPG through successive refinements, and established Computational Blueprints for Isomorphic Twins (CBIT). With meta-level generation and template-based selective variation, CBIT achieves high mathematical correctness and structural consistency while reducing the cost of generation. Empirical results across refinements demonstrate that CBIT is superior on generation accuracy and cost-effectiveness at scale. Most importantly, CBIT-generated problems exhibited an error rate 17.8% lower than expert-authored items, with deployment to 6,732 learners on a commercial education platform yielding 186,870 interactions.
Multi-level, Forming Free, Bulk Switching Trilayer RRAM for Neuromorphic Computing at the Edge
Oct 20, 2023Resistive memory-based reconfigurable systems constructed by CMOS-RRAM integration hold great promise for low energy and high throughput neuromorphic computing. However, most RRAM technologies relying on filamentary switching suffer from variations and noise leading to computational accuracy loss, increased energy consumption, and overhead by expensive program and verify schemes. Low ON-state resistance of filamentary RRAM devices further increases the energy consumption due to high-current read and write operations, and limits the array size and parallel multiply & accumulate operations. High-forming voltages needed for filamentary RRAM are not compatible with advanced CMOS technology nodes. To address all these challenges, we developed a forming-free and bulk switching RRAM technology based on a trilayer metal-oxide stack. We systematically engineered a trilayer metal-oxide RRAM stack and investigated the switching characteristics of RRAM devices with varying thicknesses and oxygen vacancy distributions across the trilayer to achieve reliable bulk switching without any filament formation. We demonstrated bulk switching operation at megaohm regime with high current nonlinearity and programmed up to 100 levels without compliance current. We developed a neuromorphic compute-in-memory platform based on trilayer bulk RRAM crossbars by combining energy-efficient switched-capacitor voltage sensing circuits with differential encoding of weights to experimentally demonstrate high-accuracy matrix-vector multiplication. We showcased the computational capability of bulk RRAM crossbars by implementing a spiking neural network model for an autonomous navigation/racing task. Our work addresses challenges posed by existing RRAM technologies and paves the way for neuromorphic computing at the edge under strict size, weight, and power constraints.
Mathematical Vocoder Algorithm : Modified Spectral Inversion for Efficient Neural Speech Synthesis
Jun 16, 2021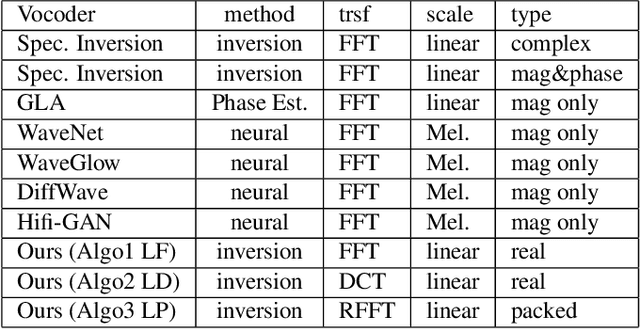
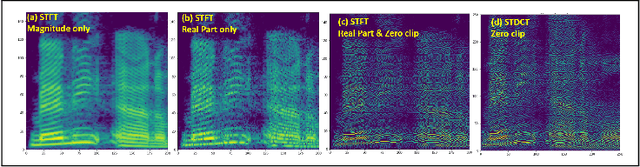
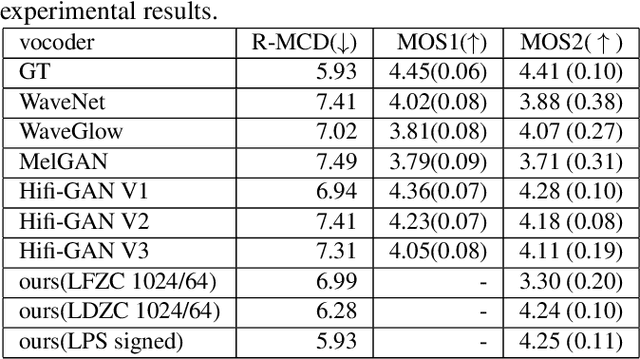
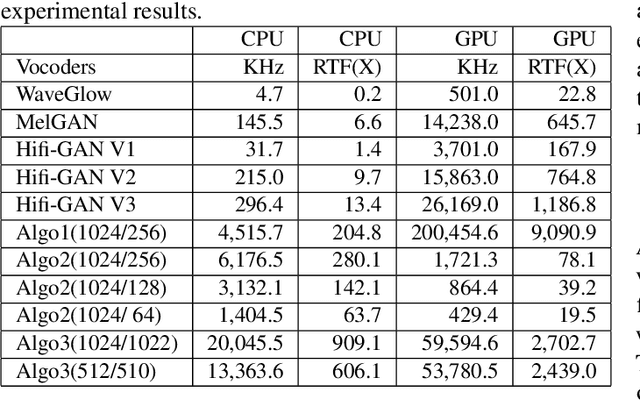
In this work, we propose a new mathematical vocoder algorithm(modified spectral inversion) that generates a waveform from acoustic features without phase estimation. The main benefit of using our proposed method is that it excludes the training stage of the neural vocoder from the end-to-end speech synthesis model. Our implementation can synthesize high fidelity speech at approximately 20 Mhz on CPU and 59.6MHz on GPU. This is 909 and 2,702 times faster compared to real-time. Since the proposed methodology is not a data-driven method, it is applicable to unseen voices and multiple languages without any additional work. The proposed method is expected to adapt for researching on neural network models capable of synthesizing speech at the studio recording level.