 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level, Forming Free, Bulk Switching Trilayer RRAM for Neuromorphic Computing at the Edge
Oct 20, 2023Resistive memory-based reconfigurable systems constructed by CMOS-RRAM integration hold great promise for low energy and high throughput neuromorphic computing. However, most RRAM technologies relying on filamentary switching suffer from variations and noise leading to computational accuracy loss, increased energy consumption, and overhead by expensive program and verify schemes. Low ON-state resistance of filamentary RRAM devices further increases the energy consumption due to high-current read and write operations, and limits the array size and parallel multiply & accumulate operations. High-forming voltages needed for filamentary RRAM are not compatible with advanced CMOS technology nodes. To address all these challenges, we developed a forming-free and bulk switching RRAM technology based on a trilayer metal-oxide stack. We systematically engineered a trilayer metal-oxide RRAM stack and investigated the switching characteristics of RRAM devices with varying thicknesses and oxygen vacancy distributions across the trilayer to achieve reliable bulk switching without any filament formation. We demonstrated bulk switching operation at megaohm regime with high current nonlinearity and programmed up to 100 levels without compliance current. We developed a neuromorphic compute-in-memory platform based on trilayer bulk RRAM crossbars by combining energy-efficient switched-capacitor voltage sensing circuits with differential encoding of weights to experimentally demonstrate high-accuracy matrix-vector multiplication. We showcased the computational capability of bulk RRAM crossbars by implementing a spiking neural network model for an autonomous navigation/racing task. Our work addresses challenges posed by existing RRAM technologies and paves the way for neuromorphic computing at the edge under strict size, weight, and power constraints.
Ordinal Pooling
Sep 03, 2021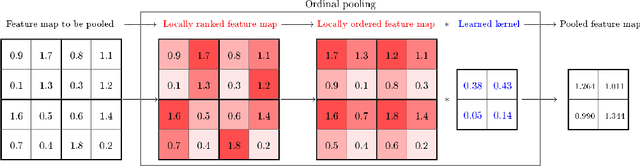

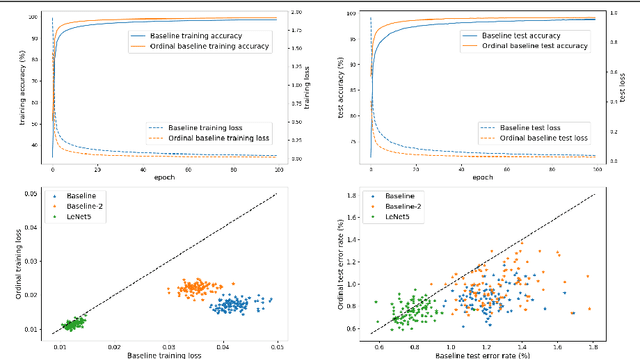

In the framework of convolutional neural networks, downsampling is often performed with an average-pooling, where all the activations are treated equally, or with a max-pooling operation that only retains an element with maximum activation while discarding the others. Both of these operations are restrictive and have previously been shown to be sub-optimal. To address this issue, a novel pooling scheme, named\emph{ ordinal pooling}, is introduced in this work. Ordinal pooling rearranges all the elements of a pooling region in a sequence and assigns a different weight to each element based upon its order in the sequence. These weights are used to compute the pooling operation as a weighted sum of the rearranged elements of the pooling region. They are learned via a standard gradient-based training, allowing to learn a behavior anywhere in the spectrum of average-pooling to max-pooling in a differentiable manner. Our experiments suggest that it is advantageous for the networks to perform different types of pooling operations within a pooling layer and that a hybrid behavior between average- and max-pooling is often beneficial. More importantly, they also demonstrate that ordinal pooling leads to consistent improvements in the accuracy over average- or max-pooling operations while speeding up the training and alleviating the issue of the choice of the pooling operations and activation functions to be used in the networks. In particular, ordinal pooling mainly helps on lightweight or quantized deep learning architectures, as typically considered e.g. for embedded applications.
* This is the authors' preprint version of a paper published at BMVC 2019. Please cite it as follows: A. Deli\`ege, M. Istasse, A. Kumar, C. De Vleeschouwer and M. Van Droogenbroeck, "Ordinal Pooling", in British Machine Vision Conference, 2019
Ordinal Pooling Networks: For Preserving Information over Shrinking Feature Maps
Apr 15, 2018

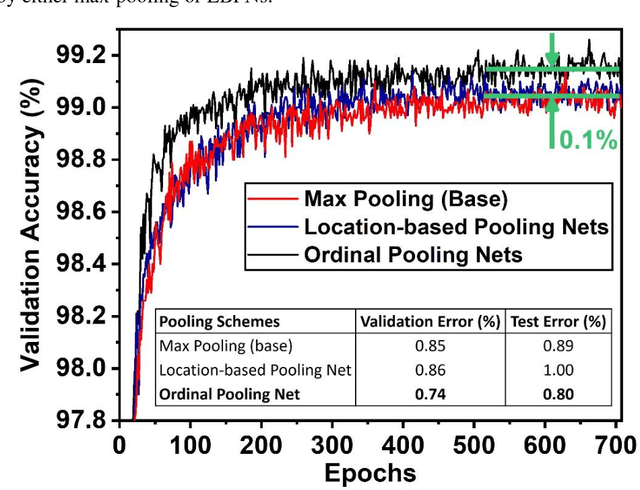

In the framework of convolutional neural networks that lie at the heart of deep learning, downsampling is often performed with a max-pooling operation that only retains the element with maximum activation, while completely discarding the information contained in other elements in a pooling region. To address this issue, a novel pooling scheme, Ordinal Pooling Network (OPN), is introduced in this work. OPN rearranges all the elements of a pooling region in a sequence and assigns different weights to these elements based upon their orders in the sequence, where the weights are learned via the gradient-based optimisation. The results of our small-scale experiments on image classification task demonstrate that this scheme leads to a consistent improvement in the accuracy over max-pooling operation. This improvement is expected to increase in deeper networks, where several layers of pooling become necessary.