 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfLUNet: Multiple sclerosis lesion instance segmentation in presence of confluent lesions
May 28, 2025Accurate lesion-level segmentation on MRI is critical for multiple sclerosis (MS) diagnosis, prognosis, and disease monitoring. However, current evaluation practices largely rely on semantic segmentation post-processed with connected components (CC), which cannot separate confluent lesions (aggregates of confluent lesion units, CLUs) due to reliance on spatial connectivity. To address this misalignment with clinical needs, we introduce formal definitions of CLUs and associated CLU-aware detection metrics, and include them in an exhaustive instance segmentation evaluation framework. Within this framework, we systematically evaluate CC and post-processing-based Automated Confluent Splitting (ACLS), the only existing methods for lesion instance segmentation in MS. Our analysis reveals that CC consistently underestimates CLU counts, while ACLS tends to oversplit lesions, leading to overestimated lesion counts and reduced precision. To overcome these limitations, we propose ConfLUNet, the first end-to-end instance segmentation framework for MS lesions. ConfLUNet jointly optimizes lesion detection and delineation from a single FLAIR image. Trained on 50 patients, ConfLUNet significantly outperforms CC and ACLS on the held-out test set (n=13) in instance segmentation (Panoptic Quality: 42.0% vs. 37.5%/36.8%; p = 0.017/0.005) and lesion detection (F1: 67.3% vs. 61.6%/59.9%; p = 0.028/0.013). For CLU detection, ConfLUNet achieves the highest F1[CLU] (81.5%), improving recall over CC (+12.5%, p = 0.015) and precision over ACLS (+31.2%, p = 0.003). By combining rigorous definitions, new CLU-aware metrics, a reproducible evaluation framework, and the first dedicated end-to-end model, this work lays the foundation for lesion instance segmentation in MS.
DeepSportradar-v1: Computer Vision Dataset for Sports Understanding with High Quality Annotations
Aug 17, 2022


With the recent development of Deep Learning applied to Computer Vision, sport video understanding has gained a lot of attention, providing much richer information for both sport consumers and leagues. This paper introduces DeepSportradar-v1, a suite of computer vision tasks, datasets and benchmarks for automated sport understanding. The main purpose of this framework is to close the gap between academic research and real world settings. To this end, the datasets provide high-resolution raw images, camera parameters and high quality annotations. DeepSportradar currently supports four challenging tasks related to basketball: ball 3D localization, camera calibration, player instance segmentation and player re-identification. For each of the four tasks, a detailed description of the dataset, objective, performance metrics, and the proposed baseline method are provided. To encourage further research on advanced methods for sport understanding, a competition is organized as part of the MMSports workshop from the ACM Multimedia 2022 conference, where participants have to develop state-of-the-art methods to solve the above tasks. The four datasets, development kits and baselines are publicly available.
DeepSportLab: a Unified Framework for Ball Detection, Player Instance Segmentation and Pose Estimation in Team Sports Scenes
Dec 01, 2021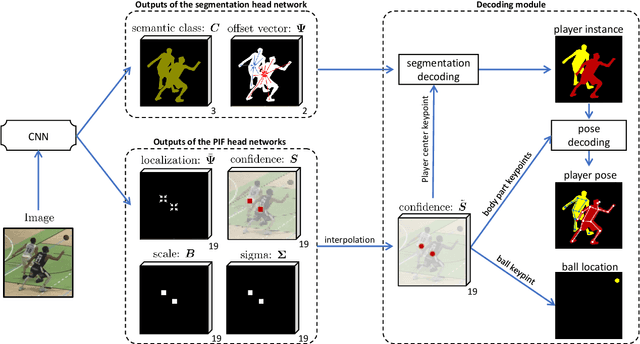
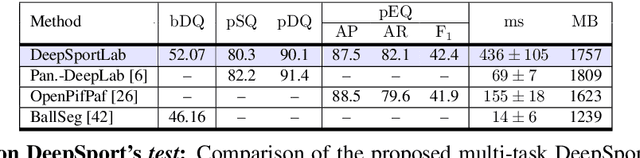
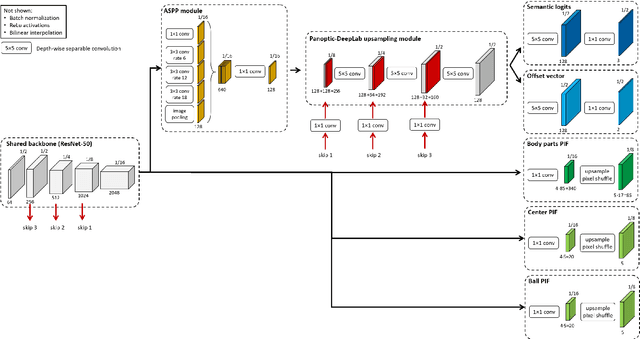
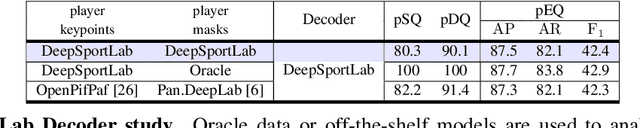
This paper presents a unified framework to (i) locate the ball, (ii) predict the pose, and (iii) segment the instance mask of players in team sports scenes. Those problems are of high interest in automated sports analytics, production, and broadcast. A common practice is to individually solve each problem by exploiting universal state-of-the-art models, \eg, Panoptic-DeepLab for player segmentation. In addition to the increased complexity resulting from the multiplication of single-task models, the use of the off-the-shelf models also impedes the performance due to the complexity and specificity of the team sports scenes, such as strong occlusion and motion blur. To circumvent those limitations, our paper proposes to train a single model that simultaneously predicts the ball and the player mask and pose by combining the part intensity fields and the spatial embeddings principles. Part intensity fields provide the ball and player location, as well as player joints location. Spatial embeddings are then exploited to associate player instance pixels to their respective player center, but also to group player joints into skeletons. We demonstrate the effectiveness of the proposed model on the DeepSport basketball dataset, achieving comparable performance to the SoA models addressing each individual task separately.
Ordinal Pooling
Sep 03, 2021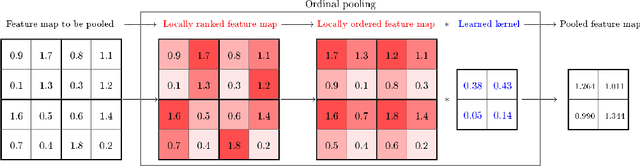

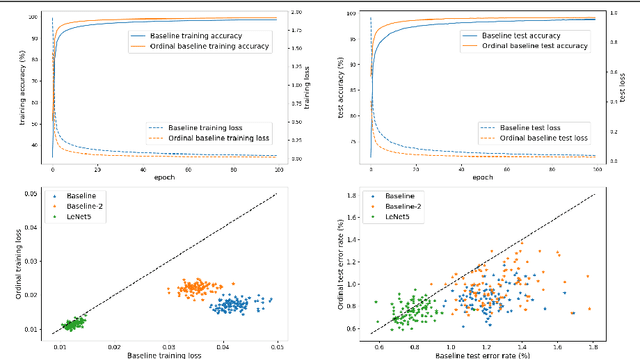

In the framework of convolutional neural networks, downsampling is often performed with an average-pooling, where all the activations are treated equally, or with a max-pooling operation that only retains an element with maximum activation while discarding the others. Both of these operations are restrictive and have previously been shown to be sub-optimal. To address this issue, a novel pooling scheme, named\emph{ ordinal pooling}, is introduced in this work. Ordinal pooling rearranges all the elements of a pooling region in a sequence and assigns a different weight to each element based upon its order in the sequence. These weights are used to compute the pooling operation as a weighted sum of the rearranged elements of the pooling region. They are learned via a standard gradient-based training, allowing to learn a behavior anywhere in the spectrum of average-pooling to max-pooling in a differentiable manner. Our experiments suggest that it is advantageous for the networks to perform different types of pooling operations within a pooling layer and that a hybrid behavior between average- and max-pooling is often beneficial. More importantly, they also demonstrate that ordinal pooling leads to consistent improvements in the accuracy over average- or max-pooling operations while speeding up the training and alleviating the issue of the choice of the pooling operations and activation functions to be used in the networks. In particular, ordinal pooling mainly helps on lightweight or quantized deep learning architectures, as typically considered e.g. for embedded applications.
* This is the authors' preprint version of a paper published at BMVC 2019. Please cite it as follows: A. Deli\`ege, M. Istasse, A. Kumar, C. De Vleeschouwer and M. Van Droogenbroeck, "Ordinal Pooling", in British Machine Vision Conference, 2019
Associative Embedding for Game-Agnostic Team Discrimination
Jul 01, 2019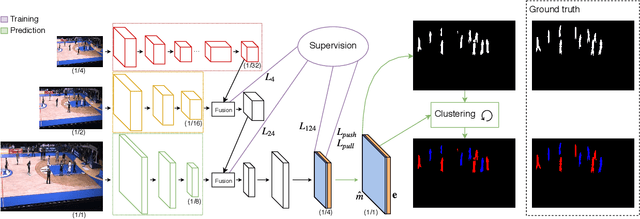
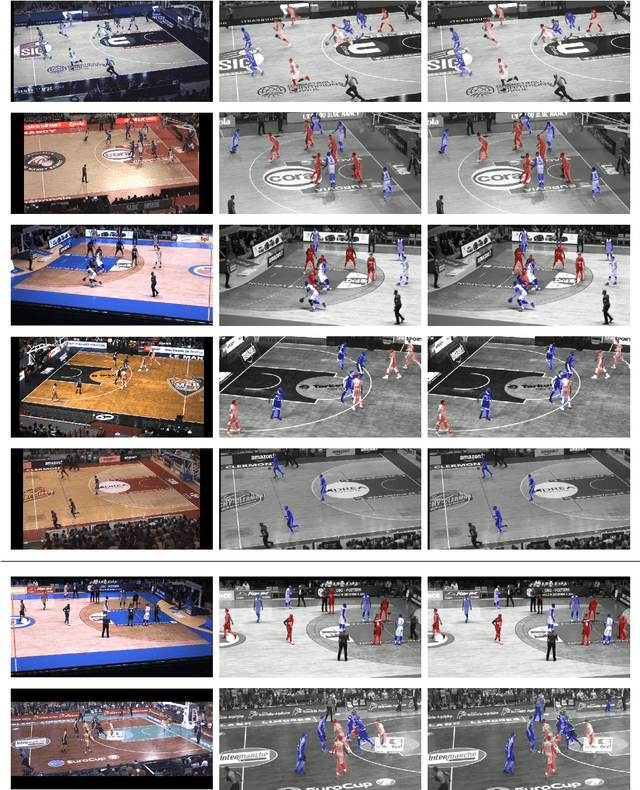
Assigning team labels to players in a sport game is not a trivial task when no prior is known about the visual appearance of each team. Our work builds on a Convolutional Neural Network (CNN) to learn a descriptor, namely a pixel-wise embedding vector, that is similar for pixels depicting players from the same team, and dissimilar when pixels correspond to distinct teams. The advantage of this idea is that no per-game learning is needed, allowing efficient team discrimination as soon as the game starts. In principle, the approach follows the associative embedding framework introduced in arXiv:1611.05424 to differentiate instances of objects. Our work is however different in that it derives the embeddings from a lightweight segmentation network and, more fundamentally, because it considers the assignment of the same embedding to unconnected pixels, as required by pixels of distinct players from the same team. Excellent results, both in terms of team labelling accuracy and generalization to new games/arenas, have been achieved on panoramic views of a large variety of basketball games involving players interactions and occlusions. This makes our method a good candidate to integrate team separation in many CNN-based sport analytics pipelines.
* Published in CVPR 2019 workshop Computer Vision in Sports, under the name "Associative Embedding for Team Discrimination" (http://openaccess.thecvf.com/content_CVPRW_2019/html/CVSports/Istasse_Associative_Embedding_for_Team_Discrimination_CVPRW_2019_paper.html)