 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating the creation of instance segmentation training sets through bounding box annotation
May 23, 2022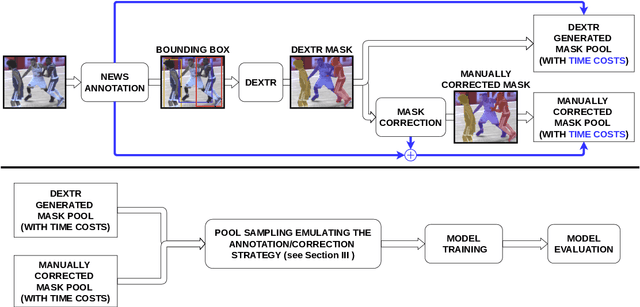
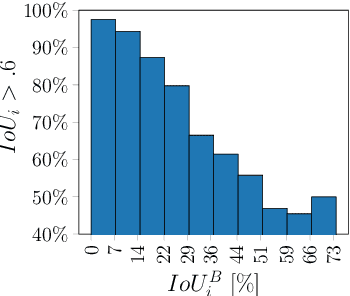
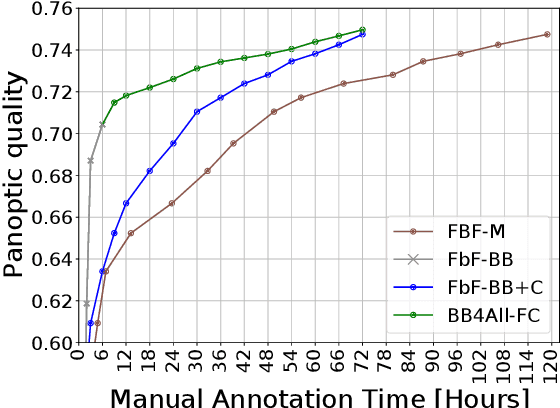
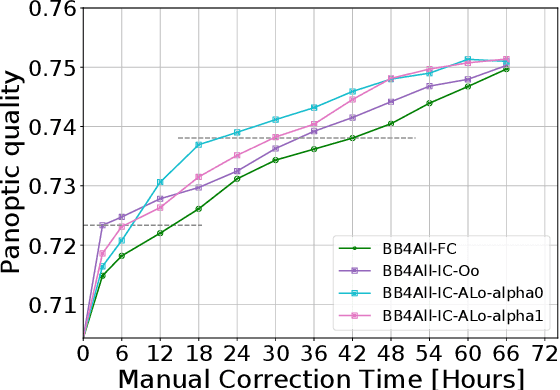
Collecting image annotations remains a significant burden when deploying CNN in a specific applicative context. This is especially the case when the annotation consists in binary masks covering object instances. Our work proposes to delineate instances in three steps, based on a semi-automatic approach: (1) the extreme points of an object (left-most, right-most, top, bottom pixels) are manually defined, thereby providing the object bounding-box, (2) a universal automatic segmentation tool like Deep Extreme Cut is used to turn the bounded object into a segmentation mask that matches the extreme points; and (3) the predicted mask is manually corrected. Various strategies are then investigated to balance the human manual annotation resources between bounding-box definition and mask correction, including when the correction of instance masks is prioritized based on their overlap with other instance bounding-boxes, or the outcome of an instance segmentation model trained on a partially annotated dataset. Our experimental study considers a teamsport player segmentation task, and measures how the accuracy of the Panoptic-Deeplab instance segmentation model depends on the human annotation resources allocation strategy. It reveals that the sole definition of extreme points results in a model accuracy that would require up to 10 times more resources if the masks were defined through fully manual delineation of instances. When targeting higher accuracies, prioritizing the mask correction among the training set instances is also shown to save up to 80\% of correction annotation resources compared to a systematic frame by frame correction of instances, for a same trained instance segmentation model accuracy.
DeepSportLab: a Unified Framework for Ball Detection, Player Instance Segmentation and Pose Estimation in Team Sports Scenes
Dec 01, 2021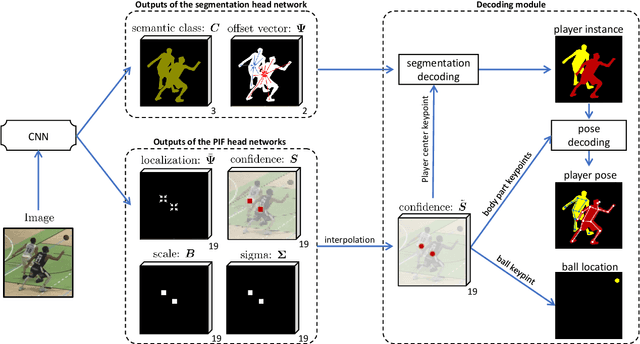
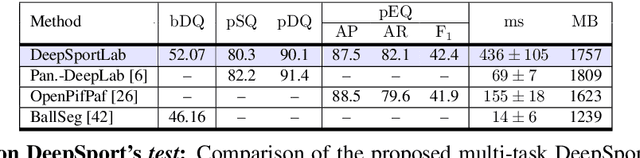
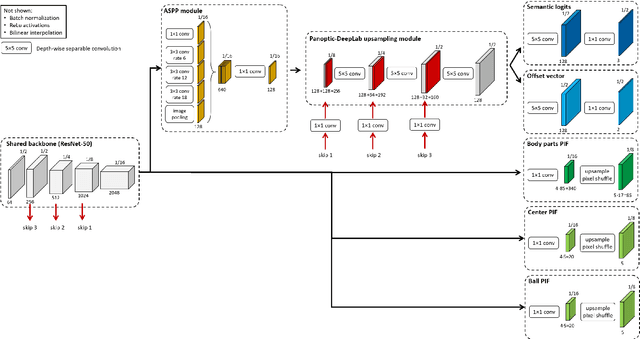
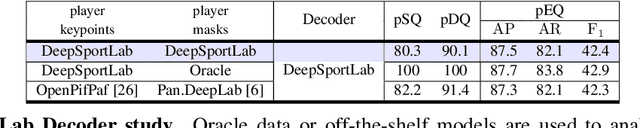
This paper presents a unified framework to (i) locate the ball, (ii) predict the pose, and (iii) segment the instance mask of players in team sports scenes. Those problems are of high interest in automated sports analytics, production, and broadcast. A common practice is to individually solve each problem by exploiting universal state-of-the-art models, \eg, Panoptic-DeepLab for player segmentation. In addition to the increased complexity resulting from the multiplication of single-task models, the use of the off-the-shelf models also impedes the performance due to the complexity and specificity of the team sports scenes, such as strong occlusion and motion blur. To circumvent those limitations, our paper proposes to train a single model that simultaneously predicts the ball and the player mask and pose by combining the part intensity fields and the spatial embeddings principles. Part intensity fields provide the ball and player location, as well as player joints location. Spatial embeddings are then exploited to associate player instance pixels to their respective player center, but also to group player joints into skeletons. We demonstrate the effectiveness of the proposed model on the DeepSport basketball dataset, achieving comparable performance to the SoA models addressing each individual task separately.