 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeRL: A Scalable and Energy-efficient Framework for Deep Spiking Reinforcement Learning
Feb 21, 2025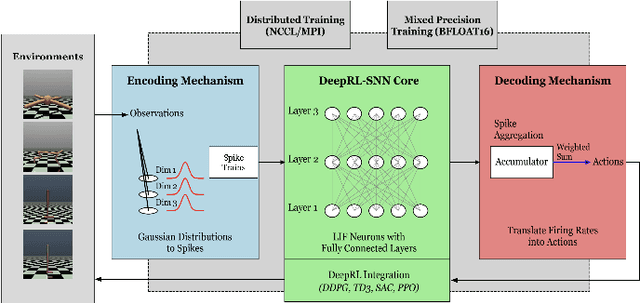
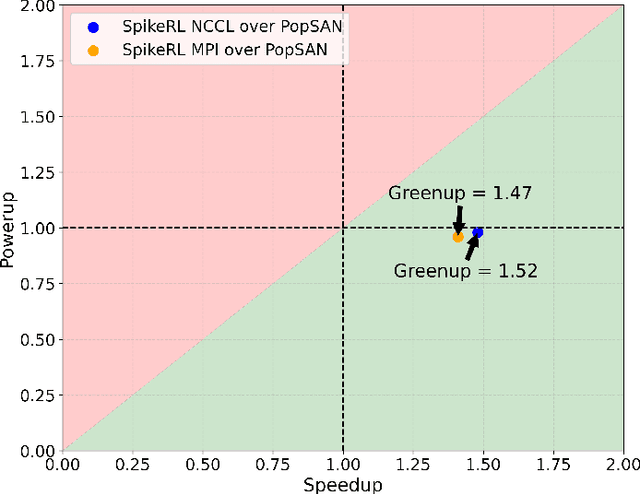
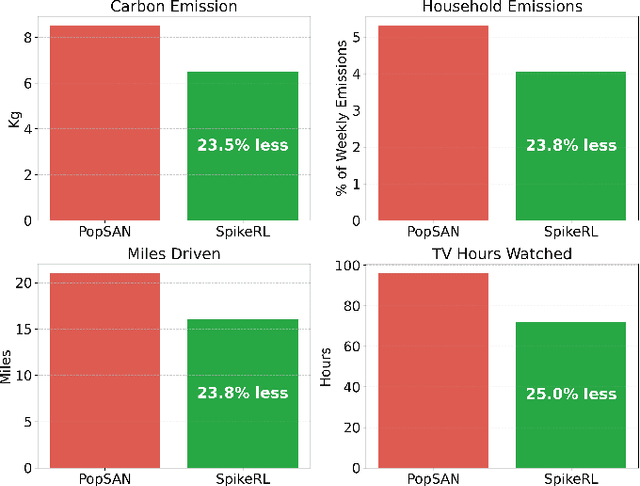
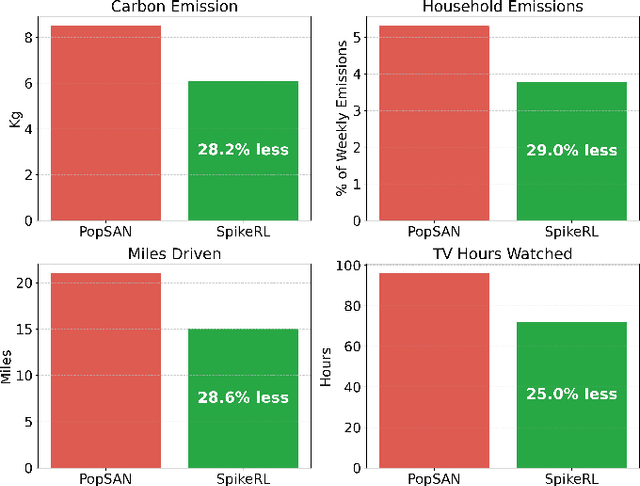
In this era of AI revolution, massive investments in large-scale data-driven AI systems demand high-performance computing, consuming tremendous energy and resources. This trend raises new challenges in optimizing sustainability without sacrificing scalability or performance. Among the energy-efficient alternatives of the traditional Von Neumann architecture, neuromorphic computing and its Spiking Neural Networks (SNNs) are a promising choice due to their inherent energy efficiency. However, in some real-world application scenarios such as complex continuous control tasks, SNNs often lack the performance optimizations that traditional artificial neural networks have. Researchers have addressed this by combining SNNs with Deep Reinforcement Learning (DeepRL), yet scalability remains unexplored. In this paper, we extend our previous work on SpikeRL, which is a scalable and energy efficient framework for DeepRL-based SNNs for continuous control. In our initial implementation of SpikeRL framework, we depended on the population encoding from the Population-coded Spiking Actor Network (PopSAN) method for our SNN model and implemented distributed training with Message Passing Interface (MPI) through mpi4py. Also, further optimizing our model training by using mixed-precision for parameter updates. In our new SpikeRL framework, we have implemented our own DeepRL-SNN component with population encoding, and distributed training with PyTorch Distributed package with NCCL backend while still optimizing with mixed precision training. Our new SpikeRL implementation is 4.26X faster and 2.25X more energy efficient than state-of-the-art DeepRL-SNN methods. Our proposed SpikeRL framework demonstrates a truly scalable and sustainable solution for complex continuous control tasks in real-world applications.
AI-Guided Codesign Framework for Novel Material and Device Design applied to MTJ-based True Random Number Generators
Nov 01, 2024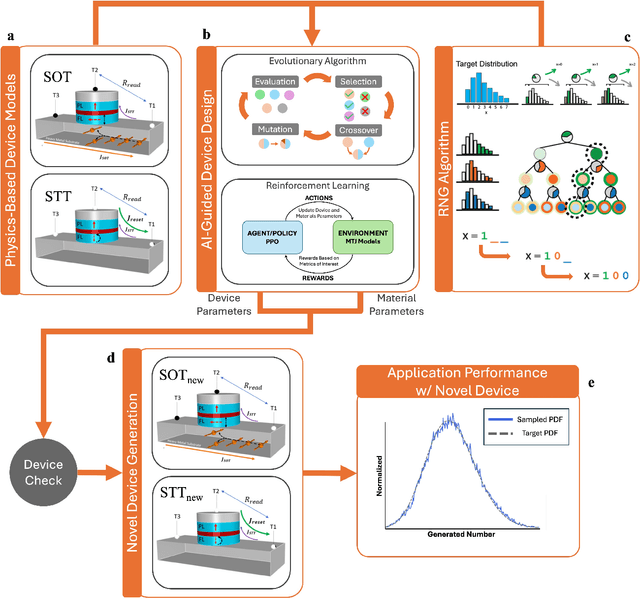
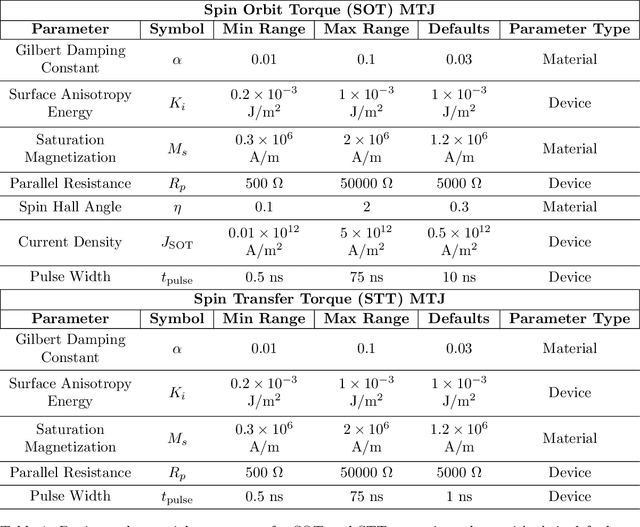
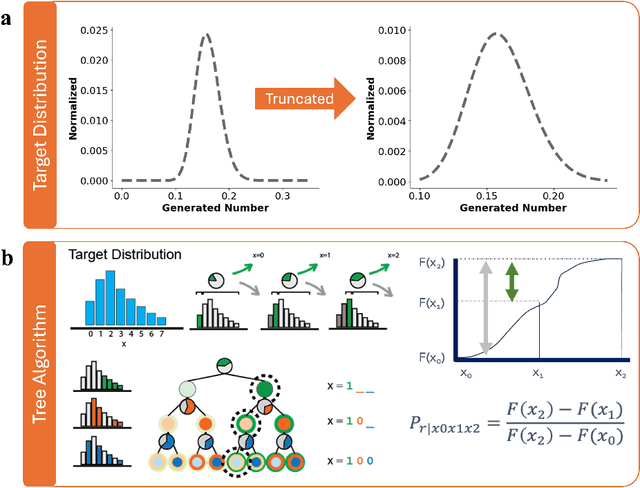
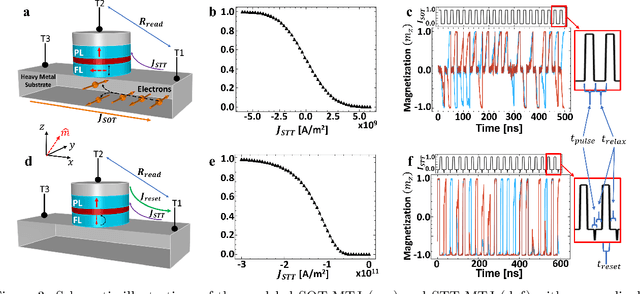
Novel devices and novel computing paradigms are key for energy efficient, performant future computing systems. However, designing devices for new applications is often time consuming and tedious. Here, we investigate the design and optimization of spin orbit torque and spin transfer torque magnetic tunnel junction models as the probabilistic devices for true random number generation. We leverage reinforcement learning and evolutionary optimization to vary key device and material properties of the various device models for stochastic operation. Our AI guided codesign methods generated different candidate devices capable of generating stochastic samples for a desired probability distribution, while also minimizing energy usage for the devices.
Speed-based Filtration and DBSCAN of Event-based Camera Data with Neuromorphic Computing
Jan 26, 2024Spiking neural networks are powerful computational elements that pair well with event-based cameras (EBCs). In this work, we present two spiking neural network architectures that process events from EBCs: one that isolates and filters out events based on their speeds, and another that clusters events based on the DBSCAN algorithm.
Multi-level, Forming Free, Bulk Switching Trilayer RRAM for Neuromorphic Computing at the Edge
Oct 20, 2023Resistive memory-based reconfigurable systems constructed by CMOS-RRAM integration hold great promise for low energy and high throughput neuromorphic computing. However, most RRAM technologies relying on filamentary switching suffer from variations and noise leading to computational accuracy loss, increased energy consumption, and overhead by expensive program and verify schemes. Low ON-state resistance of filamentary RRAM devices further increases the energy consumption due to high-current read and write operations, and limits the array size and parallel multiply & accumulate operations. High-forming voltages needed for filamentary RRAM are not compatible with advanced CMOS technology nodes. To address all these challenges, we developed a forming-free and bulk switching RRAM technology based on a trilayer metal-oxide stack. We systematically engineered a trilayer metal-oxide RRAM stack and investigated the switching characteristics of RRAM devices with varying thicknesses and oxygen vacancy distributions across the trilayer to achieve reliable bulk switching without any filament formation. We demonstrated bulk switching operation at megaohm regime with high current nonlinearity and programmed up to 100 levels without compliance current. We developed a neuromorphic compute-in-memory platform based on trilayer bulk RRAM crossbars by combining energy-efficient switched-capacitor voltage sensing circuits with differential encoding of weights to experimentally demonstrate high-accuracy matrix-vector multiplication. We showcased the computational capability of bulk RRAM crossbars by implementing a spiking neural network model for an autonomous navigation/racing task. Our work addresses challenges posed by existing RRAM technologies and paves the way for neuromorphic computing at the edge under strict size, weight, and power constraints.
Spike-based Neuromorphic Computing for Next-Generation Computer Vision
Oct 15, 2023



Neuromorphic Computing promises orders of magnitude improvement in energy efficiency compared to traditional von Neumann computing paradigm. The goal is to develop an adaptive, fault-tolerant, low-footprint, fast, low-energy intelligent system by learning and emulating brain functionality which can be realized through innovation in different abstraction layers including material, device, circuit, architecture and algorithm. As the energy consumption in complex vision tasks keep increasing exponentially due to larger data set and resource-constrained edge devices become increasingly ubiquitous, spike-based neuromorphic computing approaches can be viable alternative to deep convolutional neural network that is dominating the vision field today. In this book chapter, we introduce neuromorphic computing, outline a few representative examples from different layers of the design stack (devices, circuits and algorithms) and conclude with a few exciting applications and future research directions that seem promising for computer vision in the near future.
Functional Specification of the RAVENS Neuroprocessor
Jul 27, 2023RAVENS is a neuroprocessor that has been developed by the TENNLab research group at the University of Tennessee. Its main focus has been as a vehicle for chip design with memristive elements; however it has also been the vehicle for all-digital CMOS development, plus it has implementations on FPGA's, microcontrollers and software simulation. The software simulation is supported by the TENNLab neuromorphic software framework so that researchers may develop RAVENS solutions for a variety of neuromorphic computing applications. This document provides a functional specification of RAVENS that should apply to all implementations of the RAVENS neuroprocessor.
On-Sensor Data Filtering using Neuromorphic Computing for High Energy Physics Experiments
Jul 20, 2023



This work describes the investigation of neuromorphic computing-based spiking neural network (SNN) models used to filter data from sensor electronics in high energy physics experiments conducted at the High Luminosity Large Hadron Collider. We present our approach for developing a compact neuromorphic model that filters out the sensor data based on the particle's transverse momentum with the goal of reducing the amount of data being sent to the downstream electronics. The incoming charge waveforms are converted to streams of binary-valued events, which are then processed by the SNN. We present our insights on the various system design choices - from data encoding to optimal hyperparameters of the training algorithm - for an accurate and compact SNN optimized for hardware deployment. Our results show that an SNN trained with an evolutionary algorithm and an optimized set of hyperparameters obtains a signal efficiency of about 91% with nearly half as many parameters as a deep neural network.
Disclosure of a Neuromorphic Starter Kit
Nov 08, 2022This paper presents a Neuromorphic Starter Kit, which has been designed to help a variety of research groups perform research, exploration and real-world demonstrations of brain-based, neuromorphic processors and hardware environments. A prototype kit has been built and tested. We explain the motivation behind the kit, its design and composition, and a prototype physical demonstration.
The Case for RISP: A Reduced Instruction Spiking Processor
Jun 28, 2022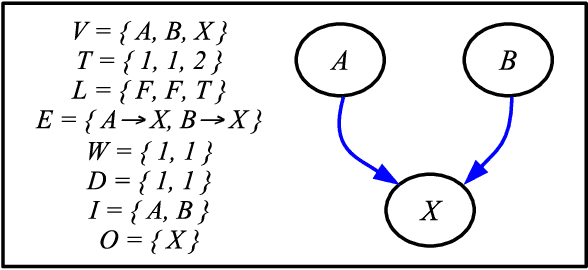
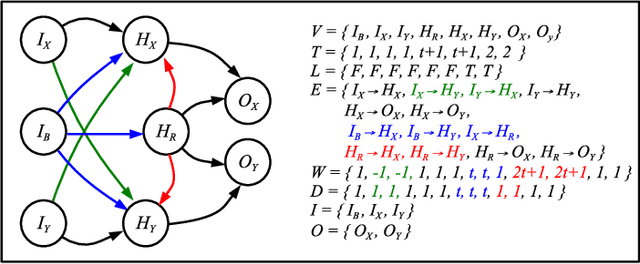
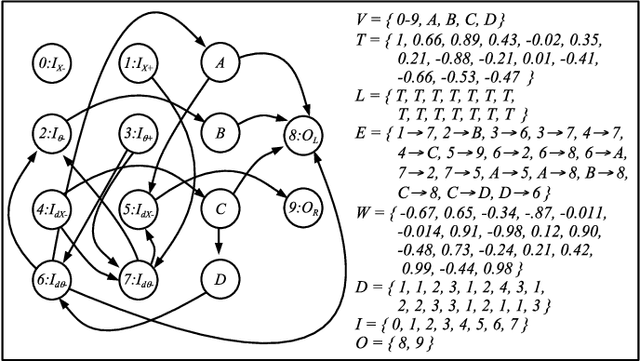
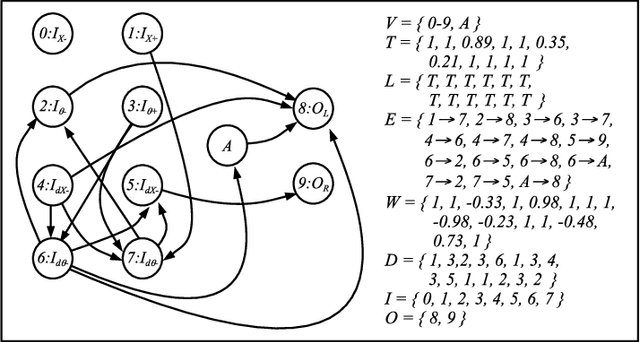
In this paper, we introduce RISP, a reduced instruction spiking processor. While most spiking neuroprocessors are based on the brain, or notions from the brain, we present the case for a spiking processor that simplifies rather than complicates. As such, it features discrete integration cycles, configurable leak, and little else. We present the computing model of RISP and highlight the benefits of its simplicity. We demonstrate how it aids in developing hand built neural networks for simple computational tasks, detail how it may be employed to simplify neural networks built with more complicated machine learning techniques, and demonstrate how it performs similarly to other spiking neurprocessors.
An Oracle and Observations for the OpenAI Gym / ALE Freeway Environment
Sep 02, 2021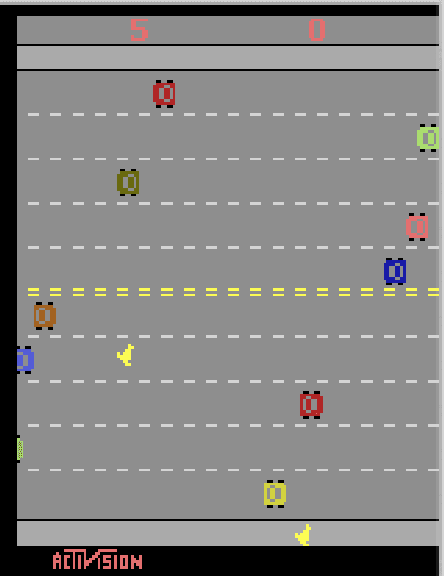
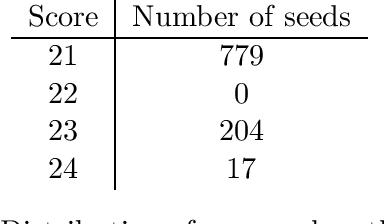
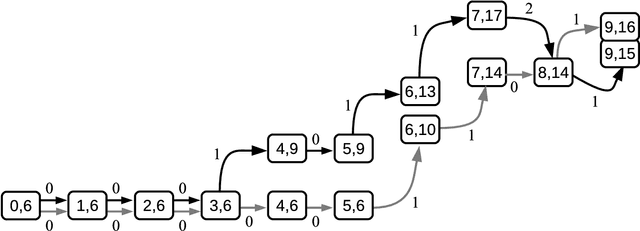
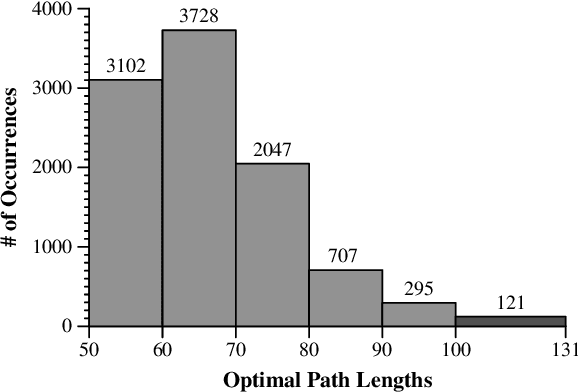
The OpenAI Gym project contains hundreds of control problems whose goal is to provide a testbed for reinforcement learning algorithms. One such problem is Freeway-ram-v0, where the observations presented to the agent are 128 bytes of RAM. While the goals of the project are for non-expert AI agents to solve the control problems with general training, in this work, we seek to learn more about the problem, so that we can better evaluate solutions. In particular, we develop on oracle to play the game, so that we may have baselines for success. We present details of the oracle, plus optimal game-playing situations that can be used for training and testing AI agents.