 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiVAE: Hierarchical Latent Variables for Scalable Theory of Mind
Feb 18, 2026Theory of mind (ToM) enables AI systems to infer agents' hidden goals and mental states, but existing approaches focus mainly on small human understandable gridworld spaces. We introduce HiVAE, a hierarchical variational architecture that scales ToM reasoning to realistic spatiotemporal domains. Inspired by the belief-desire-intention structure of human cognition, our three-level VAE hierarchy achieves substantial performance improvements on a 3,185-node campus navigation task. However, we identify a critical limitation: while our hierarchical structure improves prediction, learned latent representations lack explicit grounding to actual mental states. We propose self-supervised alignment strategies and present this work to solicit community feedback on grounding approaches.
Automated Dysphagia Screening Using Noninvasive Neck Acoustic Sensing
Feb 02, 2026Pharyngeal health plays a vital role in essential human functions such as breathing, swallowing, and vocalization. Early detection of swallowing abnormalities, also known as dysphagia, is crucial for timely intervention. However, current diagnostic methods often rely on radiographic imaging or invasive procedures. In this study, we propose an automated framework for detecting dysphagia using portable and noninvasive acoustic sensing coupled with applied machine learning. By capturing subtle acoustic signals from the neck during swallowing tasks, we aim to identify patterns associated with abnormal physiological conditions. Our approach achieves promising test-time abnormality detection performance, with an AUC-ROC of 0.904 under 5 independent train-test splits. This work demonstrates the feasibility of using noninvasive acoustic sensing as a practical and scalable tool for pharyngeal health monitoring.
A Training Framework for Optimal and Stable Training of Polynomial Neural Networks
May 16, 2025



By replacing standard non-linearities with polynomial activations, Polynomial Neural Networks (PNNs) are pivotal for applications such as privacy-preserving inference via Homomorphic Encryption (HE). However, training PNNs effectively presents a significant challenge: low-degree polynomials can limit model expressivity, while higher-degree polynomials, crucial for capturing complex functions, often suffer from numerical instability and gradient explosion. We introduce a robust and versatile training framework featuring two synergistic innovations: 1) a novel Boundary Loss that exponentially penalizes activation inputs outside a predefined stable range, and 2) Selective Gradient Clipping that effectively tames gradient magnitudes while preserving essential Batch Normalization statistics. We demonstrate our framework's broad efficacy by training PNNs within deep architectures composed of HE-compatible layers (e.g., linear layers, average pooling, batch normalization, as used in ResNet variants) across diverse image, audio, and human activity recognition datasets. These models consistently achieve high accuracy with low-degree polynomial activations (such as degree 2) and, critically, exhibit stable training and strong performance with polynomial degrees up to 22, where standard methods typically fail or suffer severe degradation. Furthermore, the performance of these PNNs achieves a remarkable parity, closely approaching that of their original ReLU-based counterparts. Extensive ablation studies validate the contributions of our techniques and guide hyperparameter selection. We confirm the HE-compatibility of the trained models, advancing the practical deployment of accurate, stable, and secure deep learning inference.
Toward Foundation Model for Multivariate Wearable Sensing of Physiological Signals
Dec 12, 2024



Time-series foundation models have the ability to run inference, mainly forecasting, on any type of time series data, thanks to the informative representations comprising waveform features. Wearable sensing data, on the other hand, contain more variability in both patterns and frequency bands of interest and generally emphasize more on the ability to infer healthcare-related outcomes. The main challenge of crafting a foundation model for wearable sensing physiological signals is to learn generalizable representations that support efficient adaptation across heterogeneous sensing configurations and applications. In this work, we propose NormWear, a step toward such a foundation model, aiming to extract generalized and informative wearable sensing representations. NormWear has been pretrained on a large set of physiological signals, including PPG, ECG, EEG, GSR, and IMU, from various public resources. For a holistic assessment, we perform downstream evaluation on 11 public wearable sensing datasets, spanning 18 applications in the areas of mental health, body state inference, biomarker estimations, and disease risk evaluations. We demonstrate that NormWear achieves a better performance improvement over competitive baselines in general time series foundation modeling. In addition, leveraging a novel representation-alignment-match-based method, we align physiological signals embeddings with text embeddings. This alignment enables our proposed foundation model to perform zero-shot inference, allowing it to generalize to previously unseen wearable signal-based health applications. Finally, we perform nonlinear dynamic analysis on the waveform features extracted by the model at each intermediate layer. This analysis quantifies the model's internal processes, offering clear insights into its behavior and fostering greater trust in its inferences among end users.
Predicting Quality of Video Gaming Experience Using Global-Scale Telemetry Data and Federated Learning
Dec 12, 2024



Frames Per Second (FPS) significantly affects the gaming experience. Providing players with accurate FPS estimates prior to purchase benefits both players and game developers. However, we have a limited understanding of how to predict a game's FPS performance on a specific device. In this paper, we first conduct a comprehensive analysis of a wide range of factors that may affect game FPS on a global-scale dataset to identify the determinants of FPS. This includes player-side and game-side characteristics, as well as country-level socio-economic statistics. Furthermore, recognizing that accurate FPS predictions require extensive user data, which raises privacy concerns, we propose a federated learning-based model to ensure user privacy. Each player and game is assigned a unique learnable knowledge kernel that gradually extracts latent features for improved accuracy. We also introduce a novel training and prediction scheme that allows these kernels to be dynamically plug-and-play, effectively addressing cold start issues. To train this model with minimal bias, we collected a large telemetry dataset from 224 countries and regions, 100,000 users, and 835 games. Our model achieved a mean Wasserstein distance of 0.469 between predicted and ground truth FPS distributions, outperforming all baseline methods.
Labits: Layered Bidirectional Time Surfaces Representation for Event Camera-based Continuous Dense Trajectory Estimation
Dec 12, 2024



Event cameras provide a compelling alternative to traditional frame-based sensors, capturing dynamic scenes with high temporal resolution and low latency. Moving objects trigger events with precise timestamps along their trajectory, enabling smooth continuous-time estimation. However, few works have attempted to optimize the information loss during event representation construction, imposing a ceiling on this task. Fully exploiting event cameras requires representations that simultaneously preserve fine-grained temporal information, stable and characteristic 2D visual features, and temporally consistent information density, an unmet challenge in existing representations. We introduce Labits: Layered Bidirectional Time Surfaces, a simple yet elegant representation designed to retain all these features. Additionally, we propose a dedicated module for extracting active pixel local optical flow (APLOF), significantly boosting the performance. Our approach achieves an impressive 49% reduction in trajectory end-point error (TEPE) compared to the previous state-of-the-art on the MultiFlow dataset. The code will be released upon acceptance.
NeRF-enabled Analysis-Through-Synthesis for ISAR Imaging of Small Everyday Objects with Sparse and Noisy UWB Radar Data
Oct 14, 2024



Inverse Synthetic Aperture Radar (ISAR) imaging presents a formidable challenge when it comes to small everyday objects due to their limited Radar Cross-Section (RCS) and the inherent resolution constraints of radar systems. Existing ISAR reconstruction methods including backprojection (BP) often require complex setups and controlled environments, rendering them impractical for many real-world noisy scenarios. In this paper, we propose a novel Analysis-through-Synthesis (ATS) framework enabled by Neural Radiance Fields (NeRF) for high-resolution coherent ISAR imaging of small objects using sparse and noisy Ultra-Wideband (UWB) radar data with an inexpensive and portable setup. Our end-to-end framework integrates ultra-wideband radar wave propagation, reflection characteristics, and scene priors, enabling efficient 2D scene reconstruction without the need for costly anechoic chambers or complex measurement test beds. With qualitative and quantitative comparisons, we demonstrate that the proposed method outperforms traditional techniques and generates ISAR images of complex scenes with multiple targets and complex structures in Non-Line-of-Sight (NLOS) and noisy scenarios, particularly with limited number of views and sparse UWB radar scans. This work represents a significant step towards practical, cost-effective ISAR imaging of small everyday objects, with broad implications for robotics and mobile sensing applications.
Spike-based Neuromorphic Computing for Next-Generation Computer Vision
Oct 15, 2023



Neuromorphic Computing promises orders of magnitude improvement in energy efficiency compared to traditional von Neumann computing paradigm. The goal is to develop an adaptive, fault-tolerant, low-footprint, fast, low-energy intelligent system by learning and emulating brain functionality which can be realized through innovation in different abstraction layers including material, device, circuit, architecture and algorithm. As the energy consumption in complex vision tasks keep increasing exponentially due to larger data set and resource-constrained edge devices become increasingly ubiquitous, spike-based neuromorphic computing approaches can be viable alternative to deep convolutional neural network that is dominating the vision field today. In this book chapter, we introduce neuromorphic computing, outline a few representative examples from different layers of the design stack (devices, circuits and algorithms) and conclude with a few exciting applications and future research directions that seem promising for computer vision in the near future.
"Reading Between the Heat": Co-Teaching Body Thermal Signatures for Non-intrusive Stress Detection
Oct 15, 2023



Stress impacts our physical and mental health as well as our social life. A passive and contactless indoor stress monitoring system can unlock numerous important applications such as workplace productivity assessment, smart homes, and personalized mental health monitoring. While the thermal signatures from a user's body captured by a thermal camera can provide important information about the "fight-flight" response of the sympathetic and parasympathetic nervous system, relying solely on thermal imaging for training a stress prediction model often lead to overfitting and consequently a suboptimal performance. This paper addresses this challenge by introducing ThermaStrain, a novel co-teaching framework that achieves high-stress prediction performance by transferring knowledge from the wearable modality to the contactless thermal modality. During training, ThermaStrain incorporates a wearable electrodermal activity (EDA) sensor to generate stress-indicative representations from thermal videos, emulating stress-indicative representations from a wearable EDA sensor. During testing, only thermal sensing is used, and stress-indicative patterns from thermal data and emulated EDA representations are extracted to improve stress assessment. The study collected a comprehensive dataset with thermal video and EDA data under various stress conditions and distances. ThermaStrain achieves an F1 score of 0.8293 in binary stress classification, outperforming the thermal-only baseline approach by over 9%. Extensive evaluations highlight ThermaStrain's effectiveness in recognizing stress-indicative attributes, its adaptability across distances and stress scenarios, real-time executability on edge platforms, its applicability to multi-individual sensing, ability to function on limited visibility and unfamiliar conditions, and the advantages of its co-teaching approach.
Crowdotic: A Privacy-Preserving Hospital Waiting Room Crowd Density Estimation with Non-speech Audio
Sep 20, 2023


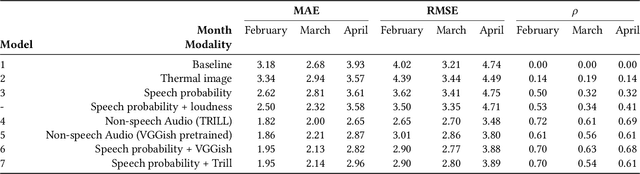
Privacy-preserving crowd density analysis finds application across a wide range of scenarios, substantially enhancing smart building operation and management while upholding privacy expectations in various spaces. We propose a non-speech audio-based approach for crowd analytics, leveraging a transformer-based model. Our results demonstrate that non-speech audio alone can be used to conduct such analysis with remarkable accuracy. To the best of our knowledge, this is the first time when non-speech audio signals are proposed for predicting occupancy. As far as we know, there has been no other similar approach of its kind prior to this. To accomplish this, we deployed our sensor-based platform in the waiting room of a large hospital with IRB approval over a period of several months to capture non-speech audio and thermal images for the training and evaluation of our models. The proposed non-speech-based approach outperformed the thermal camera-based model and all other baselines. In addition to demonstrating superior performance without utilizing speech audio, we conduct further analysis using differential privacy techniques to provide additional privacy guarantees. Overall, our work demonstrates the viability of employing non-speech audio data for accurate occupancy estimation, while also ensuring the exclusion of speech-related content and providing robust privacy protections through differential privacy guarantees.