 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoSelfRecon: Purely Self-Supervised Explicit Generalizable 3D Reconstruction of Indoor Scenes from Monocular RGB Views
Apr 10, 2024Current monocular 3D scene reconstruction (3DR) works are either fully-supervised, or not generalizable, or implicit in 3D representation. We propose a novel framework - MonoSelfRecon that for the first time achieves explicit 3D mesh reconstruction for generalizable indoor scenes with monocular RGB views by purely self-supervision on voxel-SDF (signed distance function). MonoSelfRecon follows an Autoencoder-based architecture, decodes voxel-SDF and a generalizable Neural Radiance Field (NeRF), which is used to guide voxel-SDF in self-supervision. We propose novel self-supervised losses, which not only support pure self-supervision, but can be used together with supervised signals to further boost supervised training. Our experiments show that "MonoSelfRecon" trained in pure self-supervision outperforms current best self-supervised indoor depth estimation models and is comparable to 3DR models trained in fully supervision with depth annotations. MonoSelfRecon is not restricted by specific model design, which can be used to any models with voxel-SDF for purely self-supervised manner.
V2CE: Video to Continuous Events Simulator
Sep 16, 2023



Dynamic Vision Sensor (DVS)-based solutions have recently garnered significant interest across various computer vision tasks, offering notable benefits in terms of dynamic range, temporal resolution, and inference speed. However, as a relatively nascent vision sensor compared to Active Pixel Sensor (APS) devices such as RGB cameras, DVS suffers from a dearth of ample labeled datasets. Prior efforts to convert APS data into events often grapple with issues such as a considerable domain shift from real events, the absence of quantified validation, and layering problems within the time axis. In this paper, we present a novel method for video-to-events stream conversion from multiple perspectives, considering the specific characteristics of DVS. A series of carefully designed losses helps enhance the quality of generated event voxels significantly. We also propose a novel local dynamic-aware timestamp inference strategy to accurately recover event timestamps from event voxels in a continuous fashion and eliminate the temporal layering problem. Results from rigorous validation through quantified metrics at all stages of the pipeline establish our method unquestionably as the current state-of-the-art (SOTA).
YeLan: Event Camera-Based 3D Human Pose Estimation for Technology-Mediated Dancing in Challenging Environments with Comprehensive Motion-to-Event Simulator
Jan 17, 2023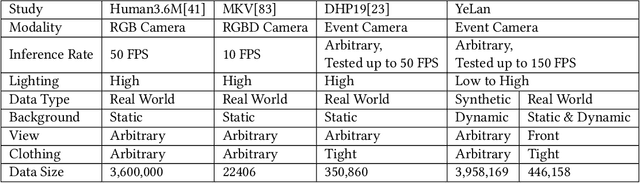



As a beloved sport worldwide, dancing is getting integrated into traditional and virtual reality-based gaming platforms nowadays. It opens up new opportunities in the technology-mediated dancing space. These platforms primarily rely on passive and continuous human pose estimation as an input capture mechanism. Existing solutions are mainly based on RGB or RGB-Depth cameras for dance games. The former suffers in low-lighting conditions due to the motion blur and low sensitivity, while the latter is too power-hungry, has a low frame rate, and has limited working distance. With ultra-low latency, energy efficiency, and wide dynamic range characteristics, the event camera is a promising solution to overcome these shortcomings. We propose YeLan, an event camera-based 3-dimensional human pose estimation(HPE) system that survives low-lighting and dynamic background contents. We collected the world's first event camera dance dataset and developed a fully customizable motion-to-event physics-aware simulator. YeLan outperforms the baseline models in these challenging conditions and demonstrated robustness against different types of clothing, background motion, viewing angle, occlusion, and lighting fluctuations.
DIREG3D: DIrectly REGress 3D Hands from Multiple Cameras
Jan 26, 2022In this paper, we present DIREG3D, a holistic framework for 3D Hand Tracking. The proposed framework is capable of utilizing camera intrinsic parameters, 3D geometry, intermediate 2D cues, and visual information to regress parameters for accurately representing a Hand Mesh model. Our experiments show that information like the size of the 2D hand, its distance from the optical center, and radial distortion is useful for deriving highly reliable 3D poses in camera space from just monocular information. Furthermore, we extend these results to a multi-view camera setup by fusing features from different viewpoints.
Continuous Authentication of Smartphones Based on Application Usage
Jul 18, 2018
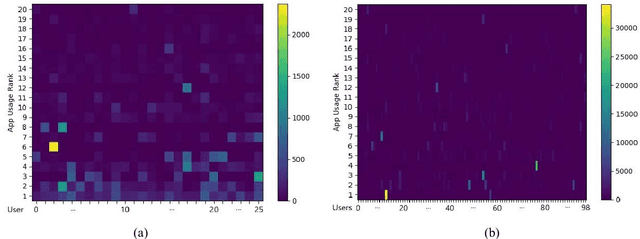
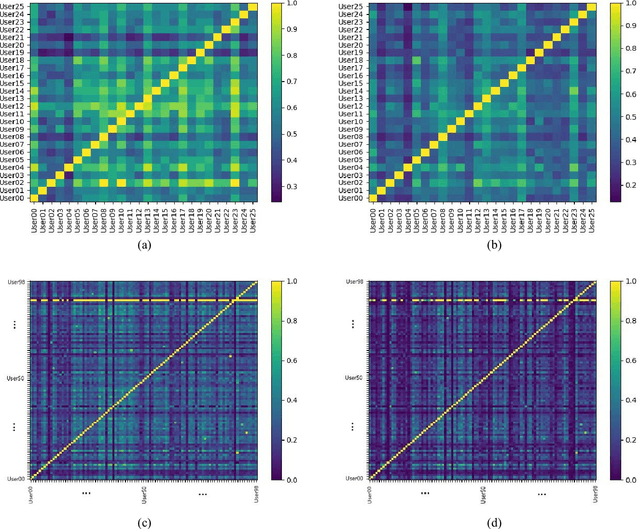
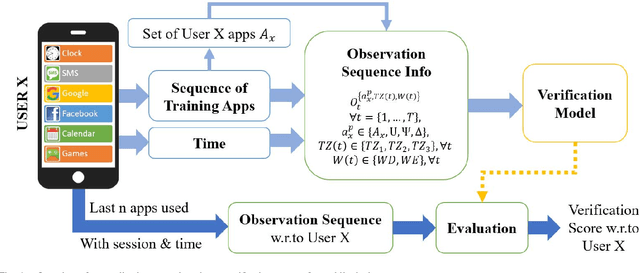
An empirical investigation of active/continuous authentication for smartphones is presented in this paper by exploiting users' unique application usage data, i.e., distinct patterns of use, modeled by a Markovian process. Variations of Hidden Markov Models (HMMs) are evaluated for continuous user verification, and challenges due to the sparsity of session-wise data, an explosion of states, and handling unforeseen events in the test data are tackled. Unlike traditional approaches, the proposed formulation does not depend on the top N-apps, rather uses the complete app-usage information to achieve low latency. Through experimentation, empirical assessment of the impact of unforeseen events, i.e., unknown applications and unforeseen observations, on user verification is done via a modified edit-distance algorithm for simple sequence matching. It is found that for enhanced verification performance, unforeseen events should be incorporated in the models by adopting smoothing techniques with HMMs. For validation, extensive experiments on two distinct datasets are performed. The marginal smoothing technique is the most effective for user verification in terms of equal error rate (EER) and with a sampling rate of 1/30s^{-1} and 30 minutes of historical data, and the method is capable of detecting an intrusion within ~2.5 minutes of application use.
Segment-based Methods for Facial Attribute Detection from Partial Faces
Jan 10, 2018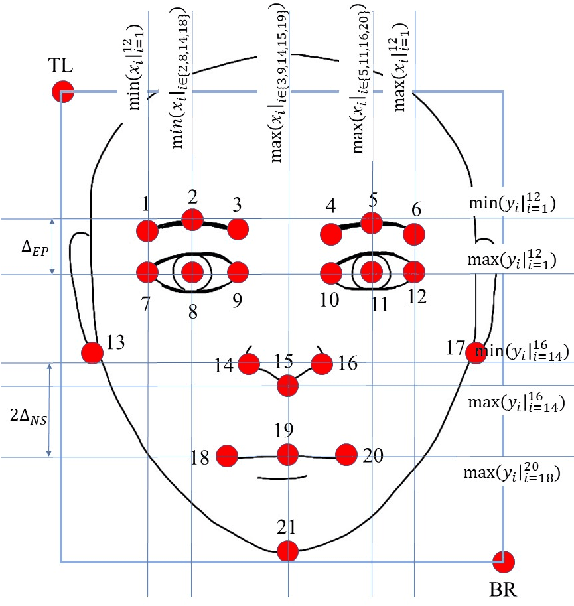

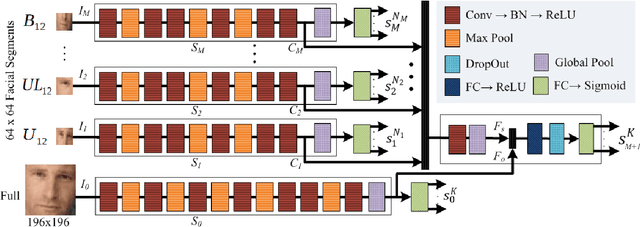
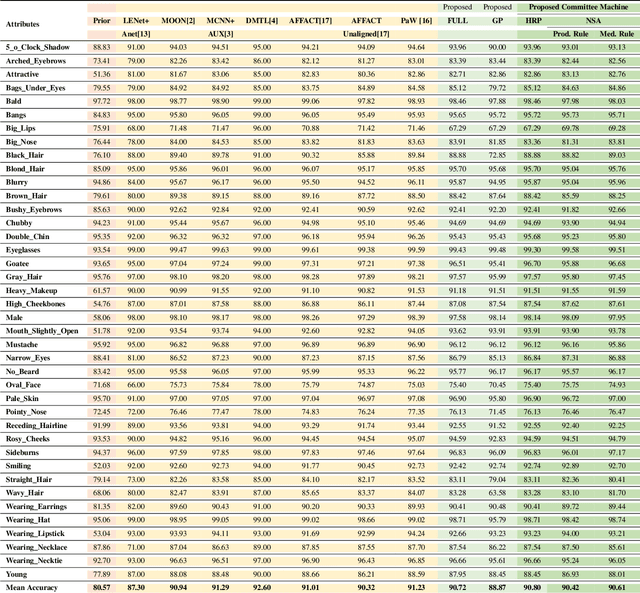
State-of-the-art methods of attribute detection from faces almost always assume the presence of a full, unoccluded face. Hence, their performance degrades for partially visible and occluded faces. In this paper, we introduce SPLITFACE, a deep convolutional neural network-based method that is explicitly designed to perform attribute detection in partially occluded faces. Taking several facial segments and the full face as input, the proposed method takes a data driven approach to determine which attributes are localized in which facial segments. The unique architecture of the network allows each attribute to be predicted by multiple segments, which permits the implementation of committee machine techniques for combining local and global decisions to boost performance. With access to segment-based predictions, SPLITFACE can predict well those attributes which are localized in the visible parts of the face, without having to rely on the presence of the whole face. We use the CelebA and LFWA facial attribute datasets for standard evaluations. We also modify both datasets, to occlude the faces, so that we can evaluate the performance of attribute detection algorithms on partial faces. Our evaluation shows that SPLITFACE significantly outperforms other recent methods especially for partial faces.
UPSET and ANGRI : Breaking High Performance Image Classifiers
Jul 04, 2017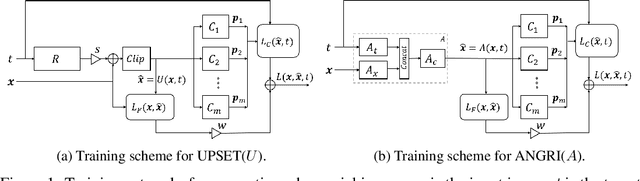
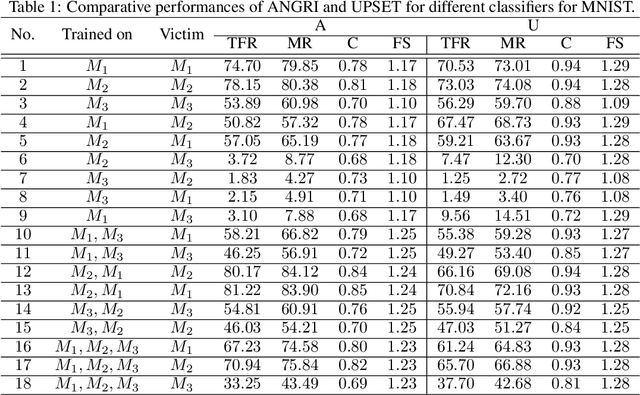

In this paper, targeted fooling of high performance image classifiers is achieved by developing two novel attack methods. The first method generates universal perturbations for target classes and the second generates image specific perturbations. Extensive experiments are conducted on MNIST and CIFAR10 datasets to provide insights about the proposed algorithms and show their effectiveness.
Partial Face Detection in the Mobile Domain
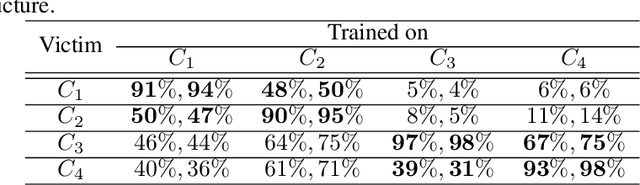
Apr 07, 2017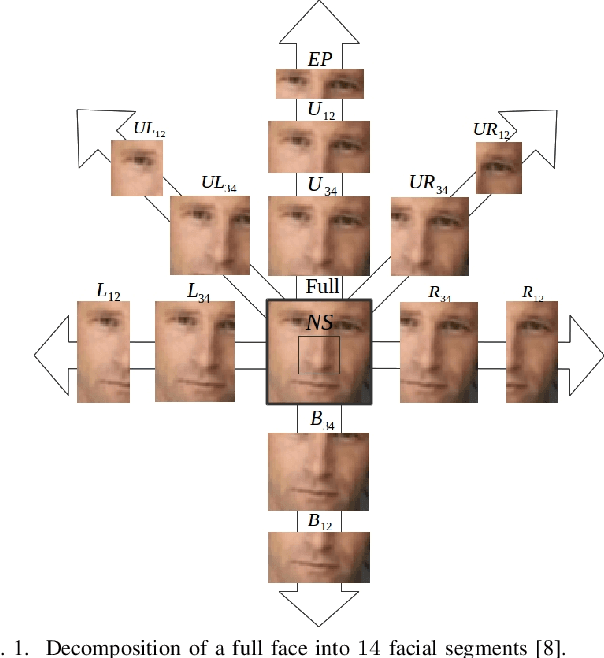
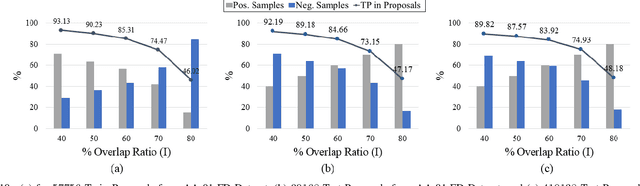
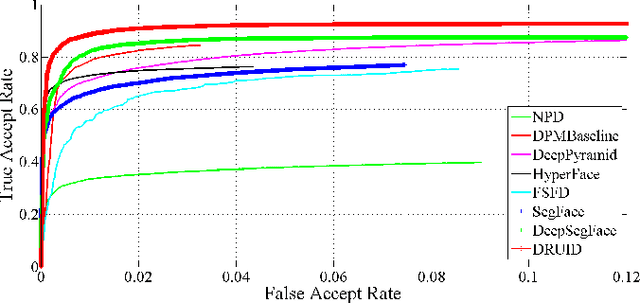
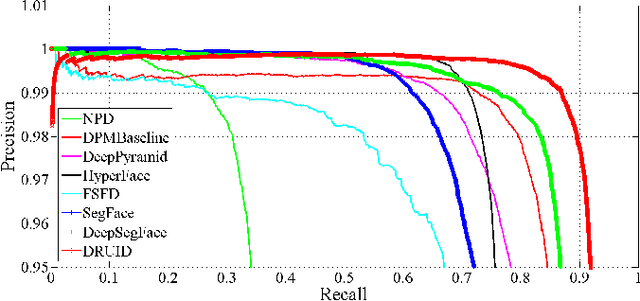
Generic face detection algorithms do not perform well in the mobile domain due to significant presence of occluded and partially visible faces. One promising technique to handle the challenge of partial faces is to design face detectors based on facial segments. In this paper two different approaches of facial segment-based face detection are discussed, namely, proposal-based detection and detection by end-to-end regression. Methods that follow the first approach rely on generating face proposals that contain facial segment information. The three detectors following this approach, namely Facial Segment-based Face Detector (FSFD), SegFace and DeepSegFace, discussed in this paper, perform binary classification on each proposal based on features learned from facial segments. The process of proposal generation, however, needs to be handled separately, which can be very time consuming, and is not truly necessary given the nature of the active authentication problem. Hence a novel algorithm, Deep Regression-based User Image Detector (DRUID) is proposed, which shifts from the classification to the regression paradigm, thus obviating the need for proposal generation. DRUID has an unique network architecture with customized loss functions, is trained using a relatively small amount of data by utilizing a novel data augmentation scheme and is fast since it outputs the bounding boxes of a face and its segments in a single pass. Being robust to occlusion by design, the facial segment-based face detection methods, especially DRUID show superior performance over other state-of-the-art face detectors in terms of precision-recall and ROC curve on two mobile face datasets.
Pooling Facial Segments to Face: The Shallow and Deep Ends
Jan 29, 2017
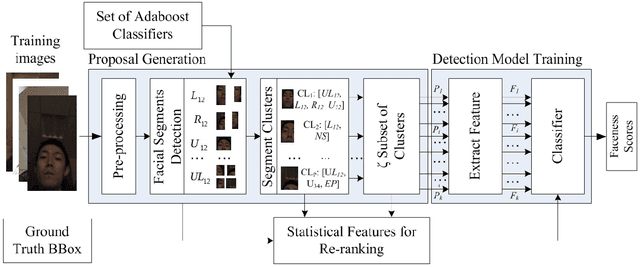
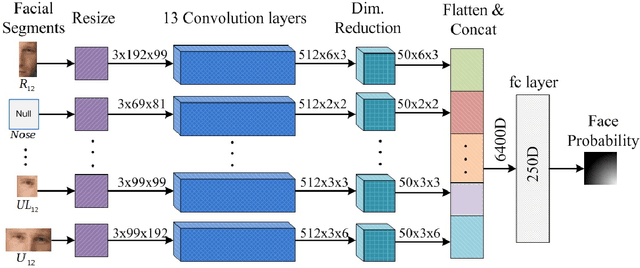

Generic face detection algorithms do not perform very well in the mobile domain due to significant presence of occluded and partially visible faces. One promising technique to handle the challenge of partial faces is to design face detectors based on facial segments. In this paper two such face detectors namely, SegFace and DeepSegFace, are proposed that detect the presence of a face given arbitrary combinations of certain face segments. Both methods use proposals from facial segments as input that are found using weak boosted classifiers. SegFace is a shallow and fast algorithm using traditional features, tailored for situations where real time constraints must be satisfied. On the other hand, DeepSegFace is a more powerful algorithm based on a deep convolutional neutral network (DCNN) architecture. DeepSegFace offers certain advantages over other DCNN-based face detectors as it requires relatively little amount of data to train by utilizing a novel data augmentation scheme and is very robust to occlusion by design. Extensive experiments show the superiority of the proposed methods, specially DeepSegFace, over other state-of-the-art face detectors in terms of precision-recall and ROC curve on two mobile face datasets.
* 8 pages, 7 figures, 3 tables, accepted for publication in FG2017
PATH: Person Authentication using Trace Histories
Oct 25, 2016
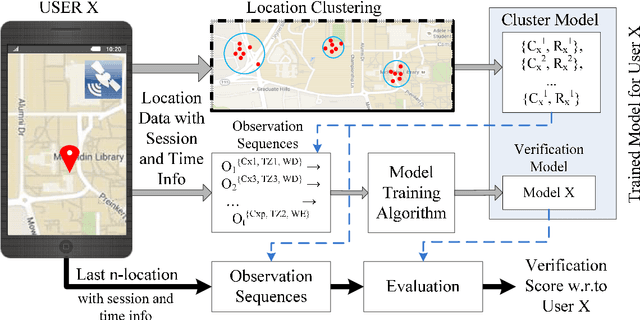
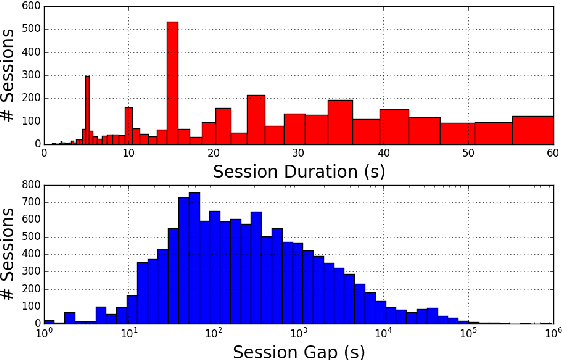
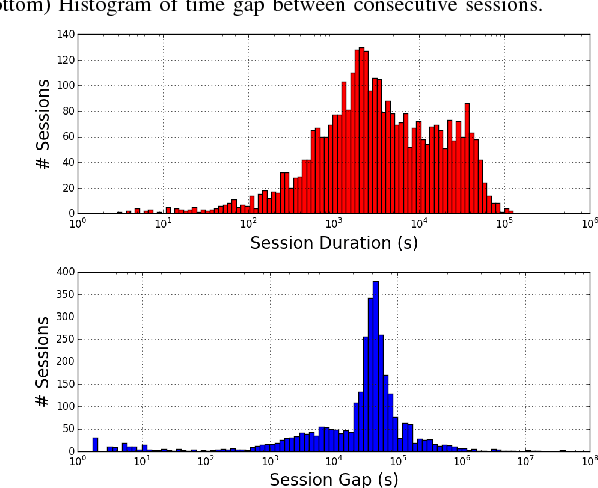
In this paper, a solution to the problem of Active Authentication using trace histories is addressed. Specifically, the task is to perform user verification on mobile devices using historical location traces of the user as a function of time. Considering the movement of a human as a Markovian motion, a modified Hidden Markov Model (HMM)-based solution is proposed. The proposed method, namely the Marginally Smoothed HMM (MSHMM), utilizes the marginal probabilities of location and timing information of the observations to smooth-out the emission probabilities while training. Hence, it can efficiently handle unforeseen observations during the test phase. The verification performance of this method is compared to a sequence matching (SM) method , a Markov Chain-based method (MC) and an HMM with basic Laplace Smoothing (HMM-lap). Experimental results using the location information of the UMD Active Authentication Dataset-02 (UMDAA02) and the GeoLife dataset are presented. The proposed MSHMM method outperforms the compared methods in terms of equal error rate (EER). Additionally, the effects of different parameters on the proposed method are discussed.