Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPSET and ANGRI : Breaking High Performance Image Classifiers
Paper and Code
Jul 04, 2017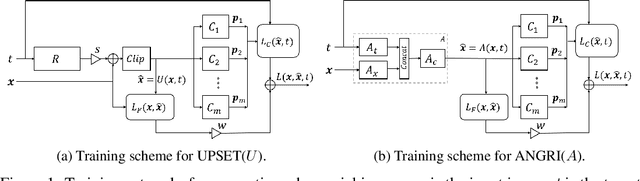
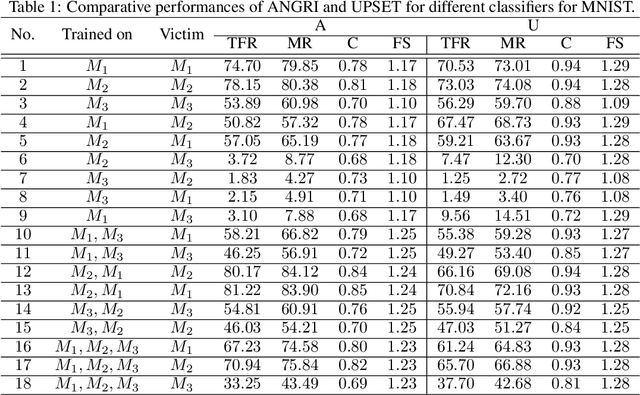

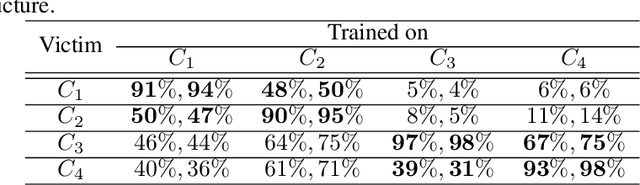
In this paper, targeted fooling of high performance image classifiers is achieved by developing two novel attack methods. The first method generates universal perturbations for target classes and the second generates image specific perturbations. Extensive experiments are conducted on MNIST and CIFAR10 datasets to provide insights about the proposed algorithms and show their effectiveness.
View paper on