 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan NLP Models Correctly Reason Over Contexts that Break the Common Assumptions?
May 20, 2023Pre-training on large corpora of text enables the language models to acquire a vast amount of factual and commonsense knowledge which allows them to achieve remarkable performance on a variety of language understanding tasks. They typically acquire this knowledge by learning from the pre-training text and capturing certain patterns from it. However, real-world settings often present scenarios that do not abide by these patterns i.e. scenarios that break the common assumptions. Can state-of-the-art NLP models correctly reason over the contexts of such scenarios? Addressing the above question, in this paper, we investigate the ability of models to correctly reason over contexts that break the common assumptions. To this end, we first systematically create evaluation data in which each data instance consists of (a) a common assumption, (b) a context that follows the assumption, (c) a context that breaks the assumption, and (d) questions based on the contexts. Then, through evaluations on multiple models including GPT-3 and Flan T5, we show that while doing fairly well on contexts that follow the common assumptions, the models struggle to correctly reason over contexts that break those assumptions. Specifically, the performance gap is as high as 20% absolute points. Furthermore, we thoroughly analyze these results revealing several interesting findings. We believe our work and findings will encourage and facilitate further research in developing more robust models that can also reliably reason over contexts that break the common assumptions. Data is available at \url{https://github.com/nrjvarshney/break_the_common_assumptions}.
Segment-based Methods for Facial Attribute Detection from Partial Faces
Jan 10, 2018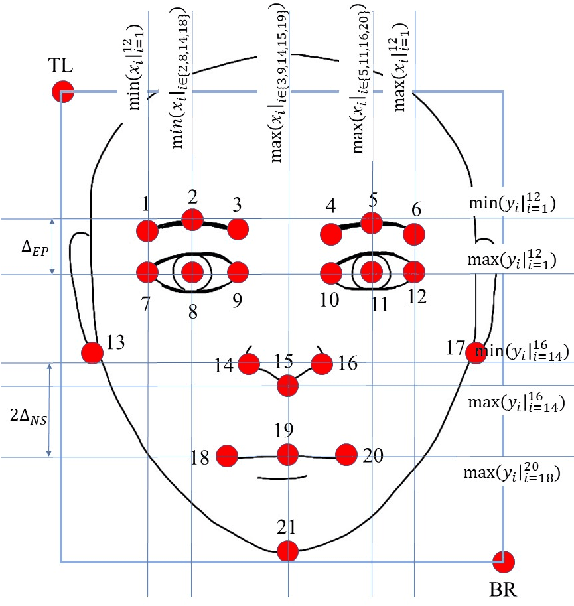

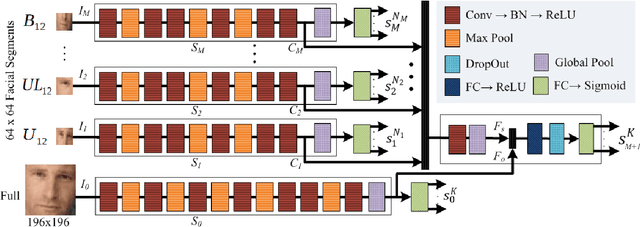
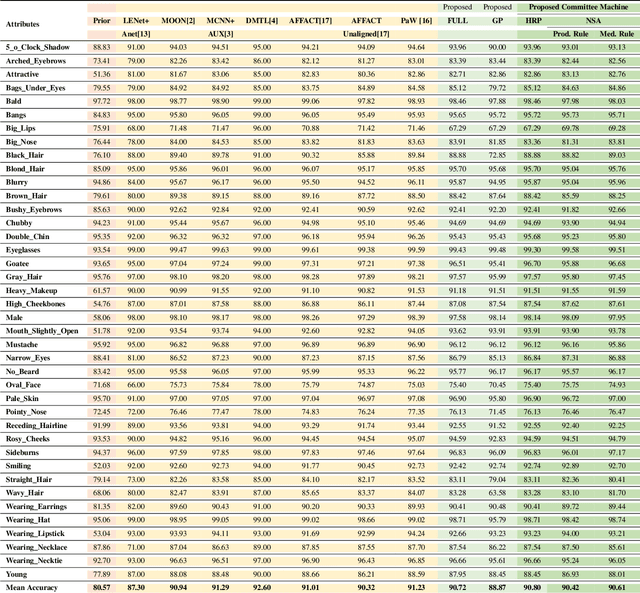
State-of-the-art methods of attribute detection from faces almost always assume the presence of a full, unoccluded face. Hence, their performance degrades for partially visible and occluded faces. In this paper, we introduce SPLITFACE, a deep convolutional neural network-based method that is explicitly designed to perform attribute detection in partially occluded faces. Taking several facial segments and the full face as input, the proposed method takes a data driven approach to determine which attributes are localized in which facial segments. The unique architecture of the network allows each attribute to be predicted by multiple segments, which permits the implementation of committee machine techniques for combining local and global decisions to boost performance. With access to segment-based predictions, SPLITFACE can predict well those attributes which are localized in the visible parts of the face, without having to rely on the presence of the whole face. We use the CelebA and LFWA facial attribute datasets for standard evaluations. We also modify both datasets, to occlude the faces, so that we can evaluate the performance of attribute detection algorithms on partial faces. Our evaluation shows that SPLITFACE significantly outperforms other recent methods especially for partial faces.
UPSET and ANGRI : Breaking High Performance Image Classifiers
Jul 04, 2017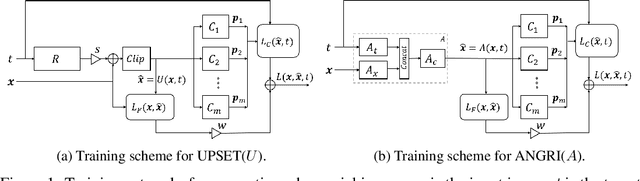
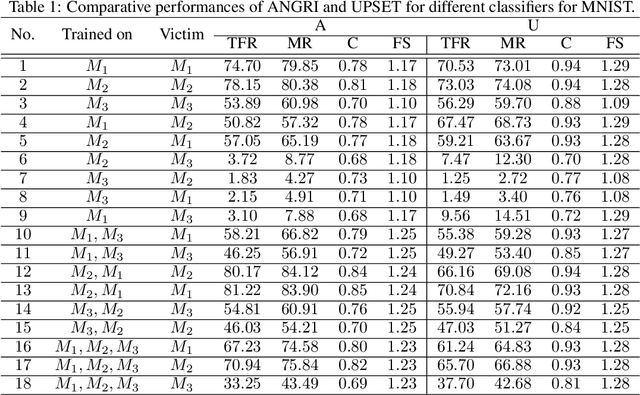

In this paper, targeted fooling of high performance image classifiers is achieved by developing two novel attack methods. The first method generates universal perturbations for target classes and the second generates image specific perturbations. Extensive experiments are conducted on MNIST and CIFAR10 datasets to provide insights about the proposed algorithms and show their effectiveness.
Partial Face Detection in the Mobile Domain
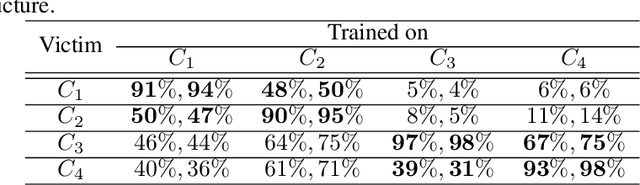
Apr 07, 2017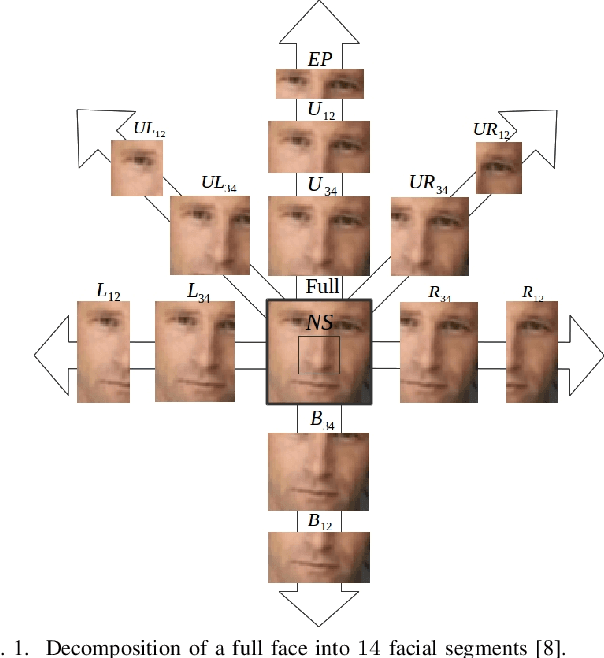
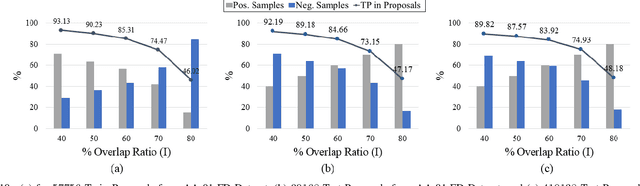
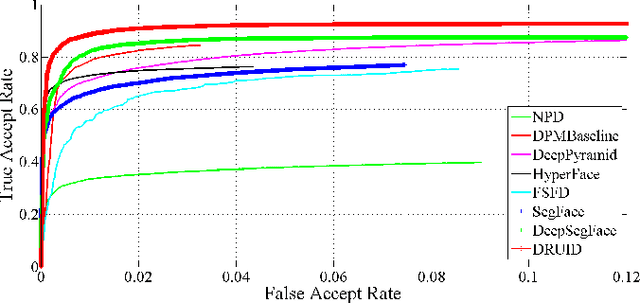
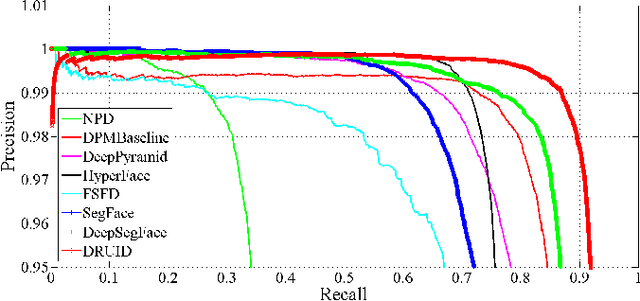
Generic face detection algorithms do not perform well in the mobile domain due to significant presence of occluded and partially visible faces. One promising technique to handle the challenge of partial faces is to design face detectors based on facial segments. In this paper two different approaches of facial segment-based face detection are discussed, namely, proposal-based detection and detection by end-to-end regression. Methods that follow the first approach rely on generating face proposals that contain facial segment information. The three detectors following this approach, namely Facial Segment-based Face Detector (FSFD), SegFace and DeepSegFace, discussed in this paper, perform binary classification on each proposal based on features learned from facial segments. The process of proposal generation, however, needs to be handled separately, which can be very time consuming, and is not truly necessary given the nature of the active authentication problem. Hence a novel algorithm, Deep Regression-based User Image Detector (DRUID) is proposed, which shifts from the classification to the regression paradigm, thus obviating the need for proposal generation. DRUID has an unique network architecture with customized loss functions, is trained using a relatively small amount of data by utilizing a novel data augmentation scheme and is fast since it outputs the bounding boxes of a face and its segments in a single pass. Being robust to occlusion by design, the facial segment-based face detection methods, especially DRUID show superior performance over other state-of-the-art face detectors in terms of precision-recall and ROC curve on two mobile face datasets.
Pooling Facial Segments to Face: The Shallow and Deep Ends
Jan 29, 2017
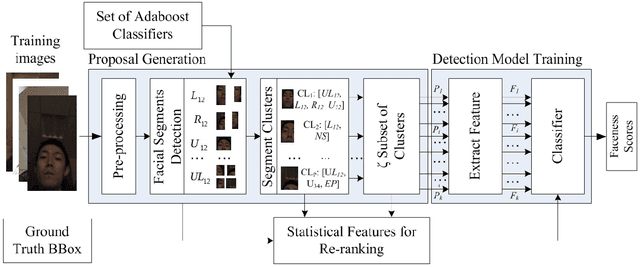
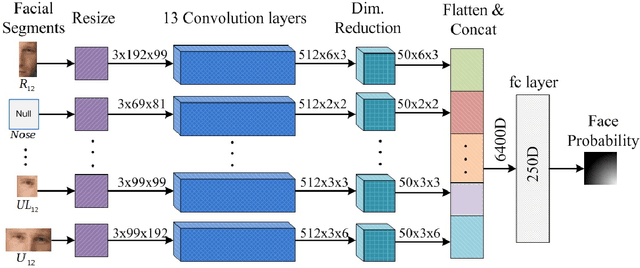

Generic face detection algorithms do not perform very well in the mobile domain due to significant presence of occluded and partially visible faces. One promising technique to handle the challenge of partial faces is to design face detectors based on facial segments. In this paper two such face detectors namely, SegFace and DeepSegFace, are proposed that detect the presence of a face given arbitrary combinations of certain face segments. Both methods use proposals from facial segments as input that are found using weak boosted classifiers. SegFace is a shallow and fast algorithm using traditional features, tailored for situations where real time constraints must be satisfied. On the other hand, DeepSegFace is a more powerful algorithm based on a deep convolutional neutral network (DCNN) architecture. DeepSegFace offers certain advantages over other DCNN-based face detectors as it requires relatively little amount of data to train by utilizing a novel data augmentation scheme and is very robust to occlusion by design. Extensive experiments show the superiority of the proposed methods, specially DeepSegFace, over other state-of-the-art face detectors in terms of precision-recall and ROC curve on two mobile face datasets.
* 8 pages, 7 figures, 3 tables, accepted for publication in FG2017
Active User Authentication for Smartphones: A Challenge Data Set and Benchmark Results
Oct 25, 2016



In this paper, automated user verification techniques for smartphones are investigated. A unique non-commercial dataset, the University of Maryland Active Authentication Dataset 02 (UMDAA-02) for multi-modal user authentication research is introduced. This paper focuses on three sensors - front camera, touch sensor and location service while providing a general description for other modalities. Benchmark results for face detection, face verification, touch-based user identification and location-based next-place prediction are presented, which indicate that more robust methods fine-tuned to the mobile platform are needed to achieve satisfactory verification accuracy. The dataset will be made available to the research community for promoting additional research.
Deep Feature-based Face Detection on Mobile Devices
Feb 16, 2016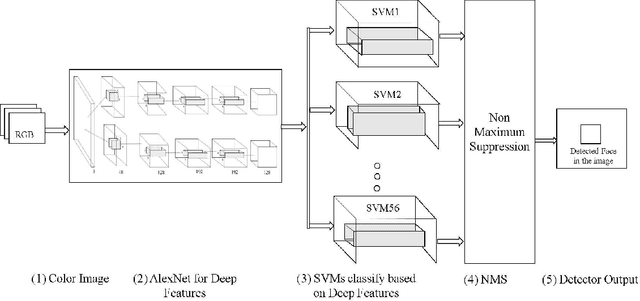
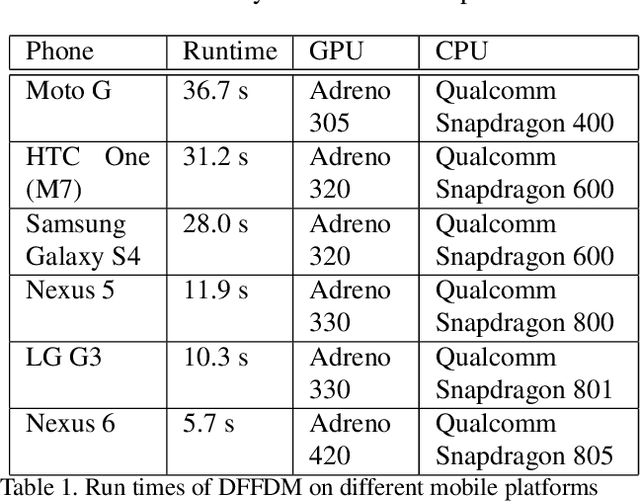
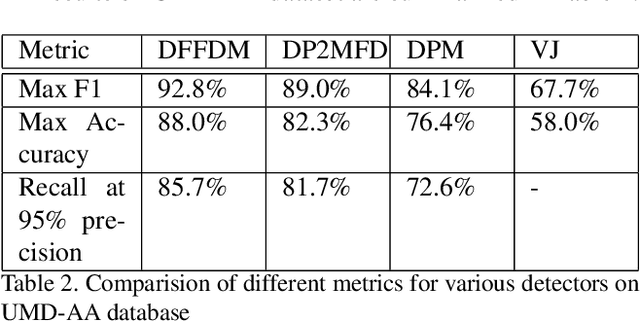
We propose a deep feature-based face detector for mobile devices to detect user's face acquired by the front facing camera. The proposed method is able to detect faces in images containing extreme pose and illumination variations as well as partial faces. The main challenge in developing deep feature-based algorithms for mobile devices is the constrained nature of the mobile platform and the non-availability of CUDA enabled GPUs on such devices. Our implementation takes into account the special nature of the images captured by the front-facing camera of mobile devices and exploits the GPUs present in mobile devices without CUDA-based frameorks, to meet these challenges.
Skin Segmentation based Elastic Bunch Graph Matching for efficient multiple Face Recognition
Oct 22, 2013

This paper is aimed at developing and combining different algorithms for face detection and face recognition to generate an efficient mechanism that can detect and recognize the facial regions of input image. For the detection of face from complex region, skin segmentation isolates the face-like regions in a complex image and following operations of morphology and template matching rejects false matches to extract facial region. For the recognition of the face, the image database is now converted into a database of facial segments. Hence, implementing the technique of Elastic Bunch Graph matching (EBGM) after skin segmentation generates Face Bunch Graphs that acutely represents the features of an individual face enhances the quality of the training set. This increases the matching probability significantly.
Word Spotting in Cursive Handwritten Documents using Modified Character Shape Codes
Oct 22, 2013


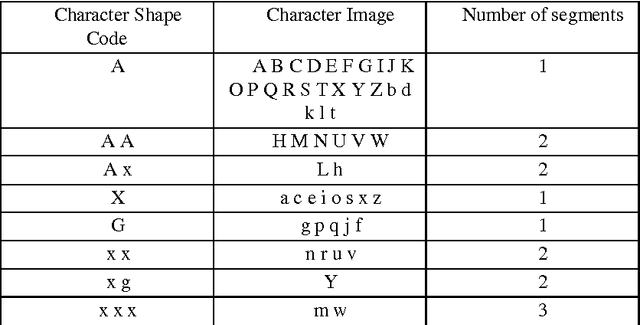
There is a large collection of Handwritten English paper documents of Historical and Scientific importance. But paper documents are not recognized directly by computer. Hence the closest way of indexing these documents is by storing their document digital image. Hence a large database of document images can replace the paper documents. But the document and data corresponding to each image cannot be directly recognized by the computer. This paper applies the technique of word spotting using Modified Character Shape Code to Handwritten English document images for quick and efficient query search of words on a database of document images. It is different from other Word Spotting techniques as it implements two level of selection for word segments to match search query. First based on word size and then based on character shape code of query. It makes the process faster and more efficient and reduces the need of multiple pre-processing.