 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-by-Step Reasoning to Solve Grid Puzzles: Where do LLMs Falter?
Jul 20, 2024



Solving grid puzzles involves a significant amount of logical reasoning. Hence, it is a good domain to evaluate the reasoning capability of a model which can then guide us to improve the reasoning ability of models. However, most existing works evaluate only the final predicted answer of a puzzle, without delving into an in-depth analysis of the LLMs' reasoning chains (such as where they falter) or providing any finer metrics to evaluate them. Since LLMs may rely on simple heuristics or artifacts to predict the final answer, it is crucial to evaluate the generated reasoning chain beyond overall correctness measures, for accurately evaluating the reasoning abilities of LLMs. To this end, we first develop GridPuzzle, an evaluation dataset comprising 274 grid-based puzzles with different complexities. Second, we propose a new error taxonomy derived from manual analysis of reasoning chains from LLMs including GPT-4, Claude-3, Gemini, Mistral, and Llama-2. Then, we develop an LLM-based framework for large-scale subjective evaluation (i.e., identifying errors) and an objective metric, PuzzleEval, to evaluate the correctness of reasoning chains. Evaluating reasoning chains from LLMs leads to several interesting findings. We further show that existing prompting methods used for enhancing models' reasoning abilities do not improve performance on GridPuzzle. This highlights the importance of understanding fine-grained errors and presents a challenge for future research to enhance LLMs' puzzle-solving abilities by developing methods that address these errors. Data and source code are available at https://github.com/Mihir3009/GridPuzzle.
Multi-LogiEval: Towards Evaluating Multi-Step Logical Reasoning Ability of Large Language Models
Jun 24, 2024



As Large Language Models (LLMs) continue to exhibit remarkable performance in natural language understanding tasks, there is a crucial need to measure their ability for human-like multi-step logical reasoning. Existing logical reasoning evaluation benchmarks often focus primarily on simplistic single-step or multi-step reasoning with a limited set of inference rules. Furthermore, the lack of datasets for evaluating non-monotonic reasoning represents a crucial gap since it aligns more closely with human-like reasoning. To address these limitations, we propose Multi-LogiEval, a comprehensive evaluation dataset encompassing multi-step logical reasoning with various inference rules and depths. Multi-LogiEval covers three logic types--propositional, first-order, and non-monotonic--consisting of more than 30 inference rules and more than 60 of their combinations with various depths. Leveraging this dataset, we conduct evaluations on a range of LLMs including GPT-4, ChatGPT, Gemini-Pro, Yi, Orca, and Mistral, employing a zero-shot chain-of-thought. Experimental results show that there is a significant drop in the performance of LLMs as the reasoning steps/depth increases (average accuracy of ~68% at depth-1 to ~43% at depth-5). We further conduct a thorough investigation of reasoning chains generated by LLMs which reveals several important findings. We believe that Multi-LogiEval facilitates future research for evaluating and enhancing the logical reasoning ability of LLMs. Data is available at https://github.com/Mihir3009/Multi-LogiEval.
Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Apr 23, 2024



Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really "reason" over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
Can NLP Models 'Identify', 'Distinguish', and 'Justify' Questions that Don't have a Definitive Answer?
Sep 08, 2023



Though state-of-the-art (SOTA) NLP systems have achieved remarkable performance on a variety of language understanding tasks, they primarily focus on questions that have a correct and a definitive answer. However, in real-world applications, users often ask questions that don't have a definitive answer. Incorrectly answering such questions certainly hampers a system's reliability and trustworthiness. Can SOTA models accurately identify such questions and provide a reasonable response? To investigate the above question, we introduce QnotA, a dataset consisting of five different categories of questions that don't have definitive answers. Furthermore, for each QnotA instance, we also provide a corresponding QA instance i.e. an alternate question that ''can be'' answered. With this data, we formulate three evaluation tasks that test a system's ability to 'identify', 'distinguish', and 'justify' QnotA questions. Through comprehensive experiments, we show that even SOTA models including GPT-3 and Flan T5 do not fare well on these tasks and lack considerably behind the human performance baseline. We conduct a thorough analysis which further leads to several interesting findings. Overall, we believe our work and findings will encourage and facilitate further research in this important area and help develop more robust models.
Can NLP Models Correctly Reason Over Contexts that Break the Common Assumptions?
May 20, 2023


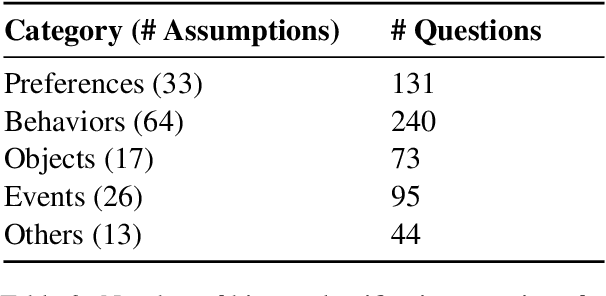
Pre-training on large corpora of text enables the language models to acquire a vast amount of factual and commonsense knowledge which allows them to achieve remarkable performance on a variety of language understanding tasks. They typically acquire this knowledge by learning from the pre-training text and capturing certain patterns from it. However, real-world settings often present scenarios that do not abide by these patterns i.e. scenarios that break the common assumptions. Can state-of-the-art NLP models correctly reason over the contexts of such scenarios? Addressing the above question, in this paper, we investigate the ability of models to correctly reason over contexts that break the common assumptions. To this end, we first systematically create evaluation data in which each data instance consists of (a) a common assumption, (b) a context that follows the assumption, (c) a context that breaks the assumption, and (d) questions based on the contexts. Then, through evaluations on multiple models including GPT-3 and Flan T5, we show that while doing fairly well on contexts that follow the common assumptions, the models struggle to correctly reason over contexts that break those assumptions. Specifically, the performance gap is as high as 20% absolute points. Furthermore, we thoroughly analyze these results revealing several interesting findings. We believe our work and findings will encourage and facilitate further research in developing more robust models that can also reliably reason over contexts that break the common assumptions. Data is available at \url{https://github.com/nrjvarshney/break_the_common_assumptions}.