 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKerasCV and KerasNLP: Vision and Language Power-Ups
May 31, 2024
We present the Keras domain packages KerasCV and KerasNLP, extensions of the Keras API for Computer Vision and Natural Language Processing workflows, capable of running on either JAX, TensorFlow, or PyTorch. These domain packages are designed to enable fast experimentation, with a focus on ease-of-use and performance. We adopt a modular, layered design: at the library's lowest level of abstraction, we provide building blocks for creating models and data preprocessing pipelines, and at the library's highest level of abstraction, we provide pretrained ``task" models for popular architectures such as Stable Diffusion, YOLOv8, GPT2, BERT, Mistral, CLIP, Gemma, T5, etc. Task models have built-in preprocessing, pretrained weights, and can be fine-tuned on raw inputs. To enable efficient training, we support XLA compilation for all models, and run all preprocessing via a compiled graph of TensorFlow operations using the tf.data API. The libraries are fully open-source (Apache 2.0 license) and available on GitHub.
Small Effect Sizes in Malware Detection? Make Harder Train/Test Splits!
Dec 25, 2023



Industry practitioners care about small improvements in malware detection accuracy because their models are deployed to hundreds of millions of machines, meaning a 0.1\% change can cause an overwhelming number of false positives. However, academic research is often restrained to public datasets on the order of ten thousand samples and is too small to detect improvements that may be relevant to industry. Working within these constraints, we devise an approach to generate a benchmark of configurable difficulty from a pool of available samples. This is done by leveraging malware family information from tools like AVClass to construct training/test splits that have different generalization rates, as measured by a secondary model. Our experiments will demonstrate that using a less accurate secondary model with disparate features is effective at producing benchmarks for a more sophisticated target model that is under evaluation. We also ablate against alternative designs to show the need for our approach.
Can NLP Models 'Identify', 'Distinguish', and 'Justify' Questions that Don't have a Definitive Answer?
Sep 08, 2023Though state-of-the-art (SOTA) NLP systems have achieved remarkable performance on a variety of language understanding tasks, they primarily focus on questions that have a correct and a definitive answer. However, in real-world applications, users often ask questions that don't have a definitive answer. Incorrectly answering such questions certainly hampers a system's reliability and trustworthiness. Can SOTA models accurately identify such questions and provide a reasonable response? To investigate the above question, we introduce QnotA, a dataset consisting of five different categories of questions that don't have definitive answers. Furthermore, for each QnotA instance, we also provide a corresponding QA instance i.e. an alternate question that ''can be'' answered. With this data, we formulate three evaluation tasks that test a system's ability to 'identify', 'distinguish', and 'justify' QnotA questions. Through comprehensive experiments, we show that even SOTA models including GPT-3 and Flan T5 do not fare well on these tasks and lack considerably behind the human performance baseline. We conduct a thorough analysis which further leads to several interesting findings. Overall, we believe our work and findings will encourage and facilitate further research in this important area and help develop more robust models.
AVScan2Vec: Feature Learning on Antivirus Scan Data for Production-Scale Malware Corpora
Jun 09, 2023

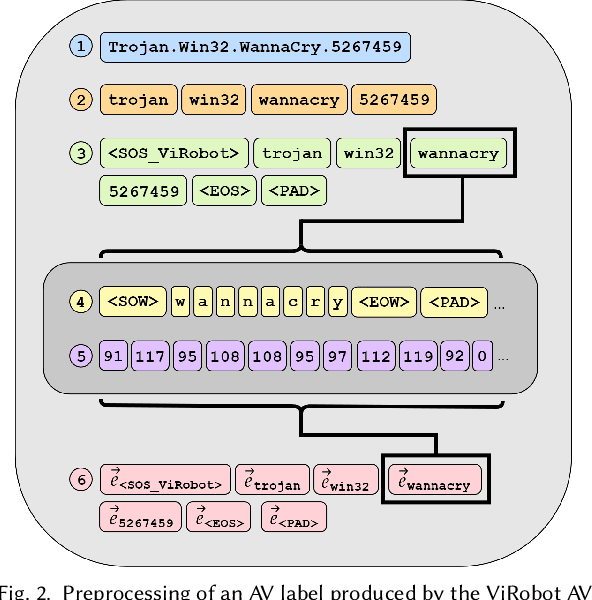

When investigating a malicious file, searching for related files is a common task that malware analysts must perform. Given that production malware corpora may contain over a billion files and consume petabytes of storage, many feature extraction and similarity search approaches are computationally infeasible. Our work explores the potential of antivirus (AV) scan data as a scalable source of features for malware. This is possible because AV scan reports are widely available through services such as VirusTotal and are ~100x smaller than the average malware sample. The information within an AV scan report is abundant with information and can indicate a malicious file's family, behavior, target operating system, and many other characteristics. We introduce AVScan2Vec, a language model trained to comprehend the semantics of AV scan data. AVScan2Vec ingests AV scan data for a malicious file and outputs a meaningful vector representation. AVScan2Vec vectors are ~3 to 85x smaller than popular alternatives in use today, enabling faster vector comparisons and lower memory usage. By incorporating Dynamic Continuous Indexing, we show that nearest-neighbor queries on AVScan2Vec vectors can scale to even the largest malware production datasets. We also demonstrate that AVScan2Vec vectors are superior to other leading malware feature vector representations across nearly all classification, clustering, and nearest-neighbor lookup algorithms that we evaluated.
A Machine Learning Challenge for Prognostic Modelling in Head and Neck Cancer Using Multi-modal Data
Jan 28, 2021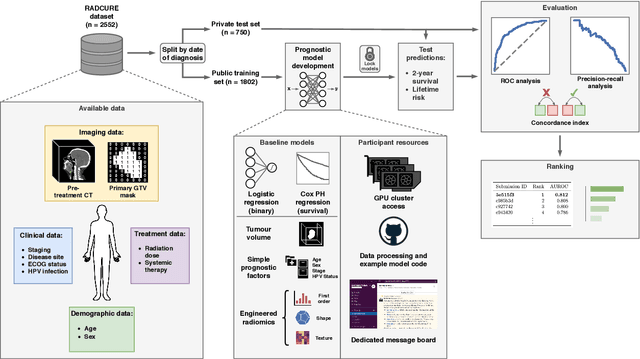

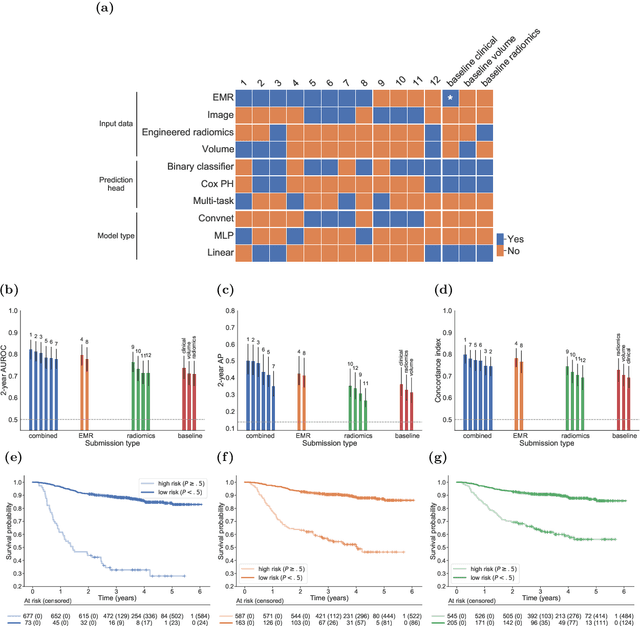
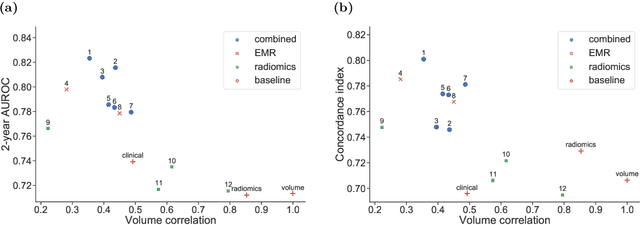
Accurate prognosis for an individual patient is a key component of precision oncology. Recent advances in machine learning have enabled the development of models using a wider range of data, including imaging. Radiomics aims to extract quantitative predictive and prognostic biomarkers from routine medical imaging, but evidence for computed tomography radiomics for prognosis remains inconclusive. We have conducted an institutional machine learning challenge to develop an accurate model for overall survival prediction in head and neck cancer using clinical data etxracted from electronic medical records and pre-treatment radiological images, as well as to evaluate the true added benefit of radiomics for head and neck cancer prognosis. Using a large, retrospective dataset of 2,552 patients and a rigorous evaluation framework, we compared 12 different submissions using imaging and clinical data, separately or in combination. The winning approach used non-linear, multitask learning on clinical data and tumour volume, achieving high prognostic accuracy for 2-year and lifetime survival prediction and outperforming models relying on clinical data only, engineered radiomics and deep learning. Combining all submissions in an ensemble model resulted in improved accuracy, with the highest gain from a image-based deep learning model. Our results show the potential of machine learning and simple, informative prognostic factors in combination with large datasets as a tool to guide personalized cancer care.