 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora
Nov 17, 2025A classifier using byte n-grams as features is the only approach we have found fast enough to meet requirements in size (sub 2 MB), speed (multiple GB/s), and latency (sub 10 ms) for deployment in numerous malware detection scenarios. However, we've consistently found that 6-8 grams achieve the best accuracy on our production deployments but have been unable to deploy regularly updated models due to the high cost of finding the top-k most frequent n-grams over terabytes of executable programs. Because the Zipfian distribution well models the distribution of n-grams, we exploit its properties to develop a new top-k n-gram extractor that is up to $35\times$ faster than the previous best alternative. Using our new Zipf-Gramming algorithm, we are able to scale up our production training set and obtain up to 30\% improvement in AUC at detecting new malware. We show theoretically and empirically that our approach will select the top-k items with little error and the interplay between theory and engineering required to achieve these results.
* Published in CIKM 2025
EMBER2024 -- A Benchmark Dataset for Holistic Evaluation of Malware Classifiers
Jun 05, 2025



A lack of accessible data has historically restricted malware analysis research, and practitioners have relied heavily on datasets provided by industry sources to advance. Existing public datasets are limited by narrow scope - most include files targeting a single platform, have labels supporting just one type of malware classification task, and make no effort to capture the evasive files that make malware detection difficult in practice. We present EMBER2024, a new dataset that enables holistic evaluation of malware classifiers. Created in collaboration with the authors of EMBER2017 and EMBER2018, the EMBER2024 dataset includes hashes, metadata, feature vectors, and labels for more than 3.2 million files from six file formats. Our dataset supports the training and evaluation of machine learning models on seven malware classification tasks, including malware detection, malware family classification, and malware behavior identification. EMBER2024 is the first to include a collection of malicious files that initially went undetected by a set of antivirus products, creating a "challenge" set to assess classifier performance against evasive malware. This work also introduces EMBER feature version 3, with added support for several new feature types. We are releasing the EMBER2024 dataset to promote reproducibility and empower researchers in the pursuit of new malware research topics.
AVScan2Vec: Feature Learning on Antivirus Scan Data for Production-Scale Malware Corpora
Jun 09, 2023

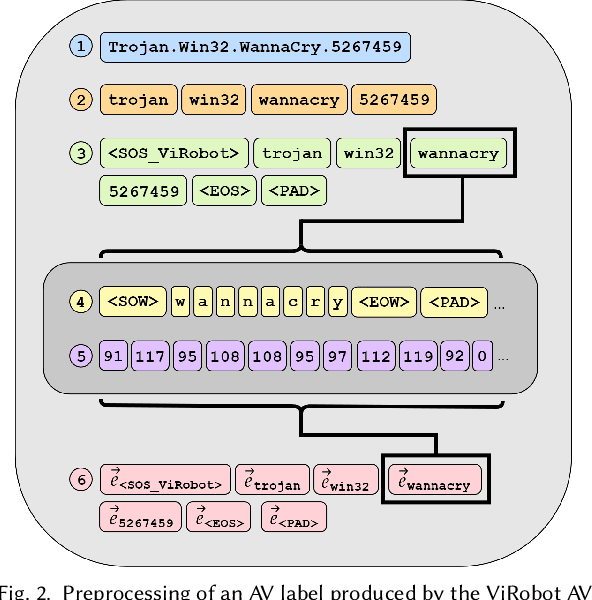

When investigating a malicious file, searching for related files is a common task that malware analysts must perform. Given that production malware corpora may contain over a billion files and consume petabytes of storage, many feature extraction and similarity search approaches are computationally infeasible. Our work explores the potential of antivirus (AV) scan data as a scalable source of features for malware. This is possible because AV scan reports are widely available through services such as VirusTotal and are ~100x smaller than the average malware sample. The information within an AV scan report is abundant with information and can indicate a malicious file's family, behavior, target operating system, and many other characteristics. We introduce AVScan2Vec, a language model trained to comprehend the semantics of AV scan data. AVScan2Vec ingests AV scan data for a malicious file and outputs a meaningful vector representation. AVScan2Vec vectors are ~3 to 85x smaller than popular alternatives in use today, enabling faster vector comparisons and lower memory usage. By incorporating Dynamic Continuous Indexing, we show that nearest-neighbor queries on AVScan2Vec vectors can scale to even the largest malware production datasets. We also demonstrate that AVScan2Vec vectors are superior to other leading malware feature vector representations across nearly all classification, clustering, and nearest-neighbor lookup algorithms that we evaluated.
Rank-1 Similarity Matrix Decomposition For Modeling Changes in Antivirus Consensus Through Time
Dec 28, 2021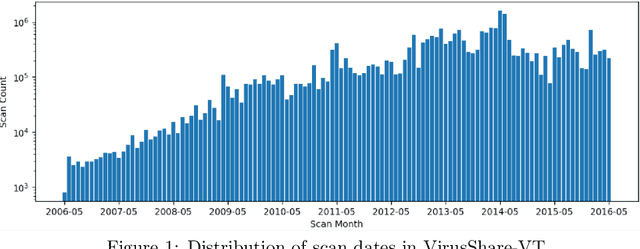
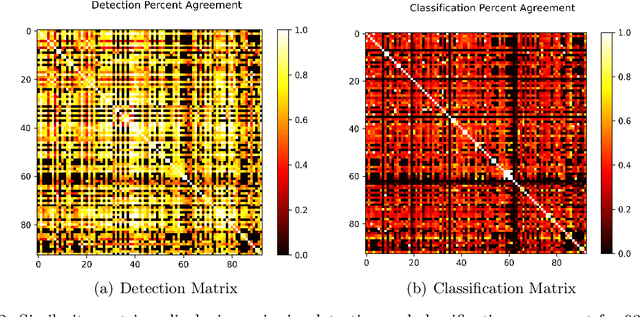
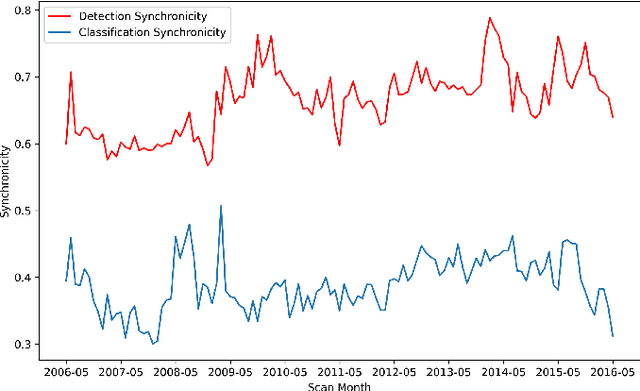
Although groups of strongly correlated antivirus engines are known to exist, at present there is limited understanding of how or why these correlations came to be. Using a corpus of 25 million VirusTotal reports representing over a decade of antivirus scan data, we challenge prevailing wisdom that these correlations primarily originate from "first-order" interactions such as antivirus vendors copying the labels of leading vendors. We introduce the Temporal Rank-1 Similarity Matrix decomposition (R1SM-T) in order to investigate the origins of these correlations and to model how consensus amongst antivirus engines changes over time. We reveal that first-order interactions do not explain as much behavior in antivirus correlation as previously thought, and that the relationships between antivirus engines are highly volatile. We make recommendations on items in need of future study and consideration based on our findings.
MOTIF: A Large Malware Reference Dataset with Ground Truth Family Labels
Nov 29, 2021
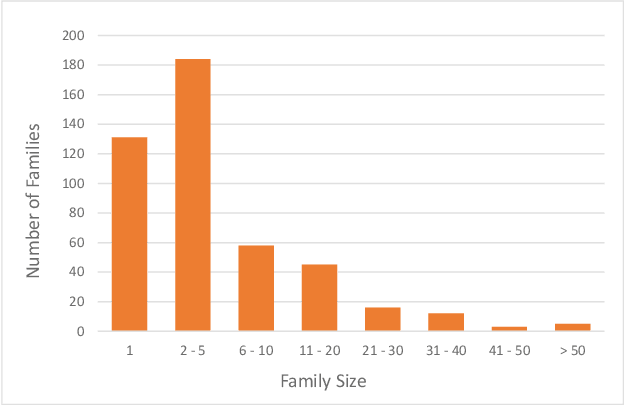
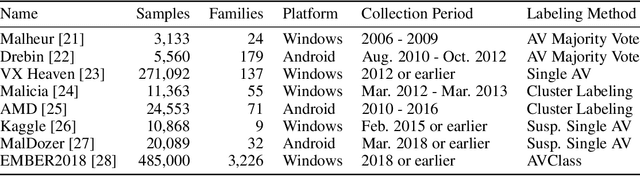

Malware family classification is a significant issue with public safety and research implications that has been hindered by the high cost of expert labels. The vast majority of corpora use noisy labeling approaches that obstruct definitive quantification of results and study of deeper interactions. In order to provide the data needed to advance further, we have created the Malware Open-source Threat Intelligence Family (MOTIF) dataset. MOTIF contains 3,095 malware samples from 454 families, making it the largest and most diverse public malware dataset with ground truth family labels to date, nearly 3x larger than any prior expert-labeled corpus and 36x larger than the prior Windows malware corpus. MOTIF also comes with a mapping from malware samples to threat reports published by reputable industry sources, which both validates the labels and opens new research opportunities in connecting opaque malware samples to human-readable descriptions. This enables important evaluations that are normally infeasible due to non-standardized reporting in industry. For example, we provide aliases of the different names used to describe the same malware family, allowing us to benchmark for the first time accuracy of existing tools when names are obtained from differing sources. Evaluation results obtained using the MOTIF dataset indicate that existing tasks have significant room for improvement, with accuracy of antivirus majority voting measured at only 62.10% and the well-known AVClass tool having just 46.78% accuracy. Our findings indicate that malware family classification suffers a type of labeling noise unlike that studied in most ML literature, due to the large open set of classes that may not be known from the sample under consideration
A Framework for Cluster and Classifier Evaluation in the Absence of Reference Labels
Sep 23, 2021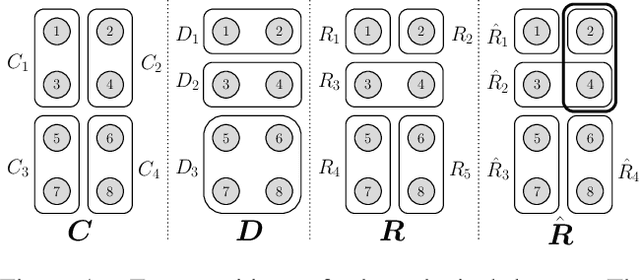
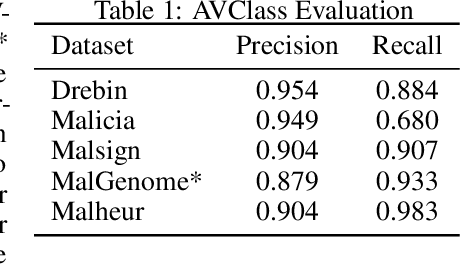
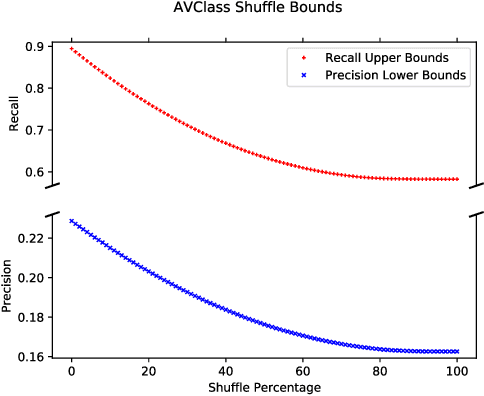
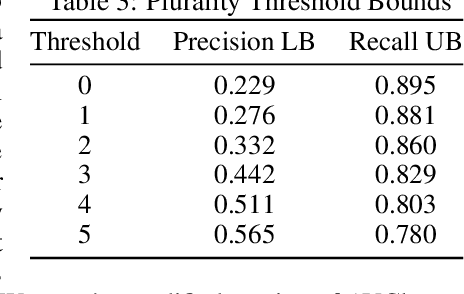
In some problem spaces, the high cost of obtaining ground truth labels necessitates use of lower quality reference datasets. It is difficult to benchmark model performance using these datasets, as evaluation results may be biased. We propose a supplement to using reference labels, which we call an approximate ground truth refinement (AGTR). Using an AGTR, we prove that bounds on specific metrics used to evaluate clustering algorithms and multi-class classifiers can be computed without reference labels. We also introduce a procedure that uses an AGTR to identify inaccurate evaluation results produced from datasets of dubious quality. Creating an AGTR requires domain knowledge, and malware family classification is a task with robust domain knowledge approaches that support the construction of an AGTR. We demonstrate our AGTR evaluation framework by applying it to a popular malware labeling tool to diagnose over-fitting in prior testing and evaluate changes whose impact could not be meaningfully quantified under previous data.