 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Formal Limits of Alignment Verification
Mar 08, 2026The goal of AI alignment is to ensure that an AI system reliably pursues intended objectives. A foundational question for AI safety is whether alignment can be formally certified: whether there exists a procedure that can guarantee that a given system satisfies an alignment specification. This paper studies the nature of alignment verification. We prove that no verification procedure can simultaneously satisfy three properties: soundness (no misaligned system is certified), generality (verification holds over the full input domain), and tractability (verification runs in polynomial time). Each pair of properties is achievable, but all three cannot hold simultaneously. Relaxing any one property restores the corresponding possibility, indicating that practical bounded or probabilistic assurance remains viable. The result follows from three independent barriers: the computational complexity of full-domain neural network verification, the non-identifiability of internal goal structure from behavioral observation, and the limits of finite evidence for properties defined over infinite domains. The trilemma establishes the limits of alignment certification and characterizes the regimes in which meaningful guarantees remain possible.
First Train to Generate, then Generate to Train: UnitedSynT5 for Few-Shot NLI
Dec 13, 2024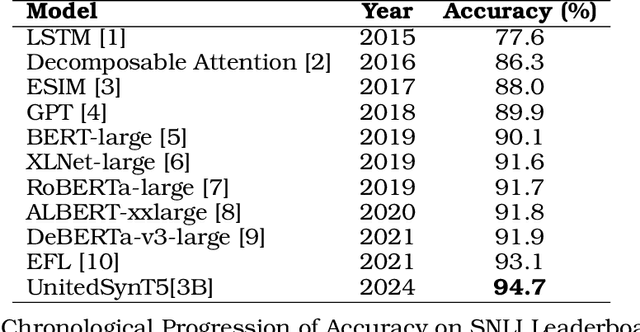
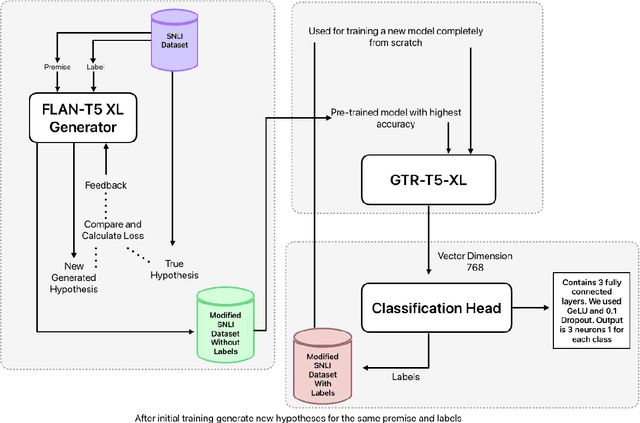

Natural Language Inference (NLI) tasks require identifying the relationship between sentence pairs, typically classified as entailment, contradiction, or neutrality. While the current state-of-the-art (SOTA) model, Entailment Few-Shot Learning (EFL), achieves a 93.1% accuracy on the Stanford Natural Language Inference (SNLI) dataset, further advancements are constrained by the dataset's limitations. To address this, we propose a novel approach leveraging synthetic data augmentation to enhance dataset diversity and complexity. We present UnitedSynT5, an advanced extension of EFL that leverages a T5-based generator to synthesize additional premise-hypothesis pairs, which are rigorously cleaned and integrated into the training data. These augmented examples are processed within the EFL framework, embedding labels directly into hypotheses for consistency. We train a GTR-T5-XL model on this expanded dataset, achieving a new benchmark of 94.7% accuracy on the SNLI dataset, 94.0% accuracy on the E-SNLI dataset, and 92.6% accuracy on the MultiNLI dataset, surpassing the previous SOTA models. This research demonstrates the potential of synthetic data augmentation in improving NLI models, offering a path forward for further advancements in natural language understanding tasks.
The Vulnerability of Language Model Benchmarks: Do They Accurately Reflect True LLM Performance?
Dec 02, 2024The pursuit of leaderboard rankings in Large Language Models (LLMs) has created a fundamental paradox: models excel at standardized tests while failing to demonstrate genuine language understanding and adaptability. Our systematic analysis of NLP evaluation frameworks reveals pervasive vulnerabilities across the evaluation spectrum, from basic metrics to complex benchmarks like GLUE and MMLU. These vulnerabilities manifest through benchmark exploitation, dataset contamination, and evaluation bias, creating a false perception of progress in language understanding capabilities. Through extensive review of contemporary evaluation approaches, we identify significant limitations in static benchmark designs, human evaluation protocols, and LLM-as-judge frameworks, all of which compromise the reliability of current performance assessments. As LLM capabilities evolve and existing benchmarks become redundant, we lay the groundwork for new evaluation methods that resist manipulation, minimize data contamination, and assess domain-specific tasks. This requires frameworks that are adapted dynamically, addressing current limitations and providing a more accurate reflection of LLM performance.
High-precision medical speech recognition through synthetic data and semantic correction: UNITED-MEDASR
Nov 24, 2024



Automatic Speech Recognition (ASR) systems in the clinical domain face significant challenges, notably the need to recognise specialised medical vocabulary accurately and meet stringent precision requirements. We introduce United-MedASR, a novel architecture that addresses these challenges by integrating synthetic data generation, precision ASR fine-tuning, and advanced semantic enhancement techniques. United-MedASR constructs a specialised medical vocabulary by synthesising data from authoritative sources such as ICD-10 (International Classification of Diseases, 10th Revision), MIMS (Monthly Index of Medical Specialties), and FDA databases. This enriched vocabulary helps finetune the Whisper ASR model to better cater to clinical needs. To enhance processing speed, we incorporate Faster Whisper, ensuring streamlined and high-speed ASR performance. Additionally, we employ a customised BART-based semantic enhancer to handle intricate medical terminology, thereby increasing accuracy efficiently. Our layered approach establishes new benchmarks in ASR performance, achieving a Word Error Rate (WER) of 0.985% on LibriSpeech test-clean, 0.26% on Europarl-ASR EN Guest-test, and demonstrating robust performance on Tedlium (0.29% WER) and FLEURS (0.336% WER). Furthermore, we present an adaptable architecture that can be replicated across different domains, making it a versatile solution for domain-specific ASR systems.
LLMs Will Always Hallucinate, and We Need to Live With This
Sep 09, 2024



As Large Language Models become more ubiquitous across domains, it becomes important to examine their inherent limitations critically. This work argues that hallucinations in language models are not just occasional errors but an inevitable feature of these systems. We demonstrate that hallucinations stem from the fundamental mathematical and logical structure of LLMs. It is, therefore, impossible to eliminate them through architectural improvements, dataset enhancements, or fact-checking mechanisms. Our analysis draws on computational theory and Godel's First Incompleteness Theorem, which references the undecidability of problems like the Halting, Emptiness, and Acceptance Problems. We demonstrate that every stage of the LLM process-from training data compilation to fact retrieval, intent classification, and text generation-will have a non-zero probability of producing hallucinations. This work introduces the concept of Structural Hallucination as an intrinsic nature of these systems. By establishing the mathematical certainty of hallucinations, we challenge the prevailing notion that they can be fully mitigated.
Machine Learning Driven Biomarker Selection for Medical Diagnosis
May 16, 2024



Recent advances in experimental methods have enabled researchers to collect data on thousands of analytes simultaneously. This has led to correlational studies that associated molecular measurements with diseases such as Alzheimer's, Liver, and Gastric Cancer. However, the use of thousands of biomarkers selected from the analytes is not practical for real-world medical diagnosis and is likely undesirable due to potentially formed spurious correlations. In this study, we evaluate 4 different methods for biomarker selection and 4 different machine learning (ML) classifiers for identifying correlations, evaluating 16 approaches in all. We found that contemporary methods outperform previously reported logistic regression in cases where 3 and 10 biomarkers are permitted. When specificity is fixed at 0.9, ML approaches produced a sensitivity of 0.240 (3 biomarkers) and 0.520 (10 biomarkers), while standard logistic regression provided a sensitivity of 0.000 (3 biomarkers) and 0.040 (10 biomarkers). We also noted that causal-based methods for biomarker selection proved to be the most performant when fewer biomarkers were permitted, while univariate feature selection was the most performant when a greater number of biomarkers were permitted.
Can NLP Models 'Identify', 'Distinguish', and 'Justify' Questions that Don't have a Definitive Answer?
Sep 08, 2023



Though state-of-the-art (SOTA) NLP systems have achieved remarkable performance on a variety of language understanding tasks, they primarily focus on questions that have a correct and a definitive answer. However, in real-world applications, users often ask questions that don't have a definitive answer. Incorrectly answering such questions certainly hampers a system's reliability and trustworthiness. Can SOTA models accurately identify such questions and provide a reasonable response? To investigate the above question, we introduce QnotA, a dataset consisting of five different categories of questions that don't have definitive answers. Furthermore, for each QnotA instance, we also provide a corresponding QA instance i.e. an alternate question that ''can be'' answered. With this data, we formulate three evaluation tasks that test a system's ability to 'identify', 'distinguish', and 'justify' QnotA questions. Through comprehensive experiments, we show that even SOTA models including GPT-3 and Flan T5 do not fare well on these tasks and lack considerably behind the human performance baseline. We conduct a thorough analysis which further leads to several interesting findings. Overall, we believe our work and findings will encourage and facilitate further research in this important area and help develop more robust models.