 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Train to Generate, then Generate to Train: UnitedSynT5 for Few-Shot NLI
Dec 13, 2024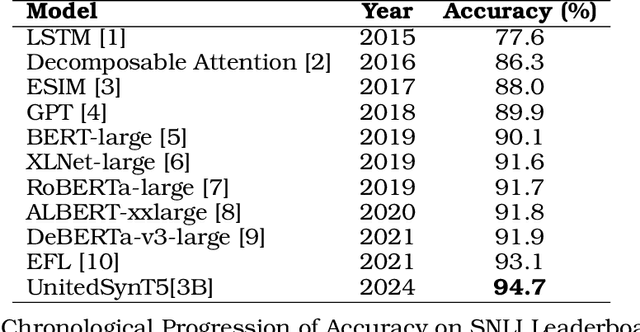
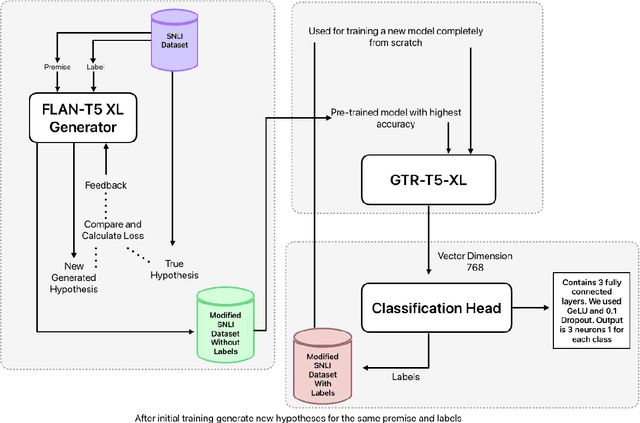

Natural Language Inference (NLI) tasks require identifying the relationship between sentence pairs, typically classified as entailment, contradiction, or neutrality. While the current state-of-the-art (SOTA) model, Entailment Few-Shot Learning (EFL), achieves a 93.1% accuracy on the Stanford Natural Language Inference (SNLI) dataset, further advancements are constrained by the dataset's limitations. To address this, we propose a novel approach leveraging synthetic data augmentation to enhance dataset diversity and complexity. We present UnitedSynT5, an advanced extension of EFL that leverages a T5-based generator to synthesize additional premise-hypothesis pairs, which are rigorously cleaned and integrated into the training data. These augmented examples are processed within the EFL framework, embedding labels directly into hypotheses for consistency. We train a GTR-T5-XL model on this expanded dataset, achieving a new benchmark of 94.7% accuracy on the SNLI dataset, 94.0% accuracy on the E-SNLI dataset, and 92.6% accuracy on the MultiNLI dataset, surpassing the previous SOTA models. This research demonstrates the potential of synthetic data augmentation in improving NLI models, offering a path forward for further advancements in natural language understanding tasks.
The Vulnerability of Language Model Benchmarks: Do They Accurately Reflect True LLM Performance?
Dec 02, 2024The pursuit of leaderboard rankings in Large Language Models (LLMs) has created a fundamental paradox: models excel at standardized tests while failing to demonstrate genuine language understanding and adaptability. Our systematic analysis of NLP evaluation frameworks reveals pervasive vulnerabilities across the evaluation spectrum, from basic metrics to complex benchmarks like GLUE and MMLU. These vulnerabilities manifest through benchmark exploitation, dataset contamination, and evaluation bias, creating a false perception of progress in language understanding capabilities. Through extensive review of contemporary evaluation approaches, we identify significant limitations in static benchmark designs, human evaluation protocols, and LLM-as-judge frameworks, all of which compromise the reliability of current performance assessments. As LLM capabilities evolve and existing benchmarks become redundant, we lay the groundwork for new evaluation methods that resist manipulation, minimize data contamination, and assess domain-specific tasks. This requires frameworks that are adapted dynamically, addressing current limitations and providing a more accurate reflection of LLM performance.