 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Quantum-MUSIC for DoA Estimation Using Rydberg Atomic Receiver Arrays
May 25, 2026Quantum wireless sensing using Rydberg atomic receivers enables high-sensitivity signal acquisition direction-of-arrival (DoA) estimation. However, it suffers from a fundamental limitation, where only the magnitude of the received signal is observable. The recently proposed Quantum-MUSIC algorithm addresses this problem by recovering phase information through alternating minimization and subsequently applying the MUSIC algorithm for DoA estimation. However, the existing approach relies on an $\ell_2$-norm phase retrieval step, making it highly sensitive to outlier measurements produced by hardware faults, sensor saturation, or adversarial interference. In this letter, we propose a \emph{Robust Quantum-MUSIC} (RobQMUSIC) framework that replaces the $\ell_2$-norm with an $\ell_1$-norm formulation. The resulting weighted phase-retrieval problem is solved efficiently via an Iteratively Reweighted Least Squares (IRLS) scheme embedded within the alternating minimization loop, requiring no increase in structural complexity relative to the baseline algorithm. Simulation results demonstrate that RobQMUSIC achieves near-identical DoA estimation accuracy to Quantum-MUSIC under ideal conditions, while maintaining robust performance over a wide range of outlier contamination levels at which Quantum-MUSIC fails entirely.
Warm-Start Quantum Approximate Optimization Algorithm for QAM MIMO Data Detection
Apr 20, 2026Data detection in large-scale multiple-input multiple-output (MIMO) systems with higher-order quadrature amplitude modulation (QAM) remains a challenging problem due to the exponential complexity of the classical maximum likelihood (ML) detector. This challenge is further amplified by Gray-coded modulation, which introduces nonlinear symbol-to-bit mappings and transforms the problem into a higher-order unconstrained binary optimization (HUBO) formulation. To address this problem, this paper presents a hybrid quantum-classical detection framework that leverages a warm-start linear-ramp Quantum Approximate Optimization Algorithm (WSLR-QAOA) for solving the resulting HUBO problem. A structured warm-start based on a low-rank semidefinite relaxation, solved via a block coordinate descent (BCD) method, provides an efficient and high-quality initialization, while a linear ramp parameterization guides the QAOA optimization. Simulation results show that the proposed framework outperforms classical methods in terms of symbol error rate (SER) and converges faster than standard QAOA, while achieving performance close to the optimal ML detector. Furthermore, the WSLR-QAOA algorithm is validated on actual IBM quantum hardware, where it achieves near-ML performance at low SNR and maintains competitive accuracy at higher SNR despite moderate degradation due to hardware noise. This demonstrates the practical potential of the HUBO-based WSLR-QAOA algorithm for large-scale MIMO data detection.
Rydberg Atomic RF Sensor-based Quantum Radar
Dec 19, 2025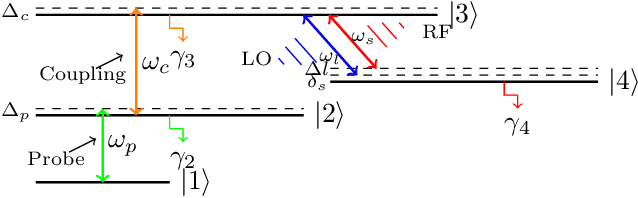
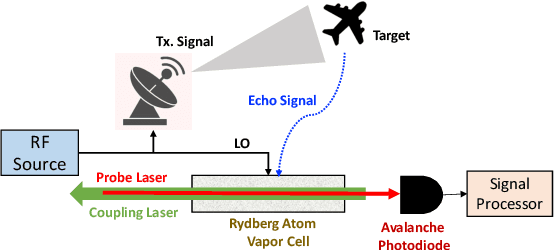


Rydberg atom-based RF sensors offer distinct advantages over conventional dipole antennas for electric field detection. This paper presents a system model and performance analysis of a Rydberg atom-based quantum radar, which employs optical readout via lasers and photon detectors instead of circuit-based receivers. We derive the signal-to-noise ratio (SNR), compare it with classical radar, and estimate Doppler frequency using an invariant function-based method. Simulations show that the quantum radar achieves higher SNR and lower RMSE in velocity estimation than conventional radar.
First Train to Generate, then Generate to Train: UnitedSynT5 for Few-Shot NLI
Dec 13, 2024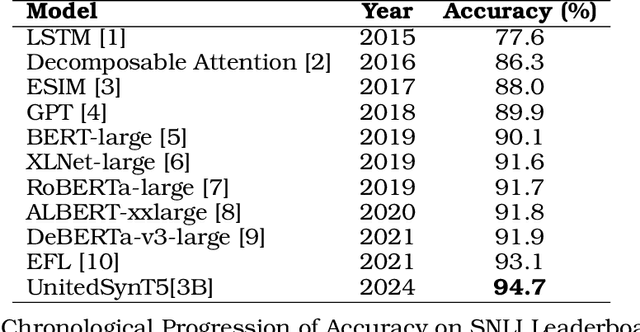
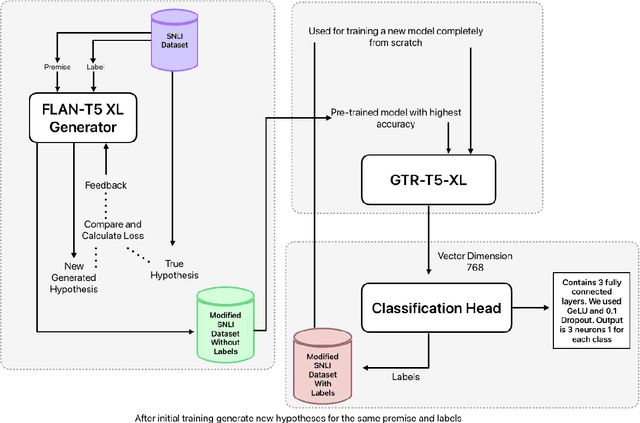

Natural Language Inference (NLI) tasks require identifying the relationship between sentence pairs, typically classified as entailment, contradiction, or neutrality. While the current state-of-the-art (SOTA) model, Entailment Few-Shot Learning (EFL), achieves a 93.1% accuracy on the Stanford Natural Language Inference (SNLI) dataset, further advancements are constrained by the dataset's limitations. To address this, we propose a novel approach leveraging synthetic data augmentation to enhance dataset diversity and complexity. We present UnitedSynT5, an advanced extension of EFL that leverages a T5-based generator to synthesize additional premise-hypothesis pairs, which are rigorously cleaned and integrated into the training data. These augmented examples are processed within the EFL framework, embedding labels directly into hypotheses for consistency. We train a GTR-T5-XL model on this expanded dataset, achieving a new benchmark of 94.7% accuracy on the SNLI dataset, 94.0% accuracy on the E-SNLI dataset, and 92.6% accuracy on the MultiNLI dataset, surpassing the previous SOTA models. This research demonstrates the potential of synthetic data augmentation in improving NLI models, offering a path forward for further advancements in natural language understanding tasks.
The Vulnerability of Language Model Benchmarks: Do They Accurately Reflect True LLM Performance?
Dec 02, 2024The pursuit of leaderboard rankings in Large Language Models (LLMs) has created a fundamental paradox: models excel at standardized tests while failing to demonstrate genuine language understanding and adaptability. Our systematic analysis of NLP evaluation frameworks reveals pervasive vulnerabilities across the evaluation spectrum, from basic metrics to complex benchmarks like GLUE and MMLU. These vulnerabilities manifest through benchmark exploitation, dataset contamination, and evaluation bias, creating a false perception of progress in language understanding capabilities. Through extensive review of contemporary evaluation approaches, we identify significant limitations in static benchmark designs, human evaluation protocols, and LLM-as-judge frameworks, all of which compromise the reliability of current performance assessments. As LLM capabilities evolve and existing benchmarks become redundant, we lay the groundwork for new evaluation methods that resist manipulation, minimize data contamination, and assess domain-specific tasks. This requires frameworks that are adapted dynamically, addressing current limitations and providing a more accurate reflection of LLM performance.
High-precision medical speech recognition through synthetic data and semantic correction: UNITED-MEDASR
Nov 24, 2024



Automatic Speech Recognition (ASR) systems in the clinical domain face significant challenges, notably the need to recognise specialised medical vocabulary accurately and meet stringent precision requirements. We introduce United-MedASR, a novel architecture that addresses these challenges by integrating synthetic data generation, precision ASR fine-tuning, and advanced semantic enhancement techniques. United-MedASR constructs a specialised medical vocabulary by synthesising data from authoritative sources such as ICD-10 (International Classification of Diseases, 10th Revision), MIMS (Monthly Index of Medical Specialties), and FDA databases. This enriched vocabulary helps finetune the Whisper ASR model to better cater to clinical needs. To enhance processing speed, we incorporate Faster Whisper, ensuring streamlined and high-speed ASR performance. Additionally, we employ a customised BART-based semantic enhancer to handle intricate medical terminology, thereby increasing accuracy efficiently. Our layered approach establishes new benchmarks in ASR performance, achieving a Word Error Rate (WER) of 0.985% on LibriSpeech test-clean, 0.26% on Europarl-ASR EN Guest-test, and demonstrating robust performance on Tedlium (0.29% WER) and FLEURS (0.336% WER). Furthermore, we present an adaptable architecture that can be replicated across different domains, making it a versatile solution for domain-specific ASR systems.
LLMs Will Always Hallucinate, and We Need to Live With This
Sep 09, 2024



As Large Language Models become more ubiquitous across domains, it becomes important to examine their inherent limitations critically. This work argues that hallucinations in language models are not just occasional errors but an inevitable feature of these systems. We demonstrate that hallucinations stem from the fundamental mathematical and logical structure of LLMs. It is, therefore, impossible to eliminate them through architectural improvements, dataset enhancements, or fact-checking mechanisms. Our analysis draws on computational theory and Godel's First Incompleteness Theorem, which references the undecidability of problems like the Halting, Emptiness, and Acceptance Problems. We demonstrate that every stage of the LLM process-from training data compilation to fact retrieval, intent classification, and text generation-will have a non-zero probability of producing hallucinations. This work introduces the concept of Structural Hallucination as an intrinsic nature of these systems. By establishing the mathematical certainty of hallucinations, we challenge the prevailing notion that they can be fully mitigated.
Machine Fault Classification using Hamiltonian Neural Networks
Jan 04, 2023A new approach is introduced to classify faults in rotating machinery based on the total energy signature estimated from sensor measurements. The overall goal is to go beyond using black-box models and incorporate additional physical constraints that govern the behavior of mechanical systems. Observational data is used to train Hamiltonian neural networks that describe the conserved energy of the system for normal and various abnormal regimes. The estimated total energy function, in the form of the weights of the Hamiltonian neural network, serves as the new feature vector to discriminate between the faults using off-the-shelf classification models. The experimental results are obtained using the MaFaulDa database, where the proposed model yields a promising area under the curve (AUC) of $0.78$ for the binary classification (normal vs abnormal) and $0.84$ for the multi-class problem (normal, and $5$ different abnormal regimes).