 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Media Polarization Using Large Language Models and Heuristic Rules
Jan 02, 2026Understanding affective polarization in online discourse is crucial for evaluating the societal impact of social media interactions. This study presents a novel framework that leverages large language models (LLMs) and domain-informed heuristics to systematically analyze and quantify affective polarization in discussions on divisive topics such as climate change and gun control. Unlike most prior approaches that relied on sentiment analysis or predefined classifiers, our method integrates LLMs to extract stance, affective tone, and agreement patterns from large-scale social media discussions. We then apply a rule-based scoring system capable of quantifying affective polarization even in small conversations consisting of single interactions, based on stance alignment, emotional content, and interaction dynamics. Our analysis reveals distinct polarization patterns that are event dependent: (i) anticipation-driven polarization, where extreme polarization escalates before well-publicized events, and (ii) reactive polarization, where intense affective polarization spikes immediately after sudden, high-impact events. By combining AI-driven content annotation with domain-informed scoring, our framework offers a scalable and interpretable approach to measuring affective polarization. The source code is publicly available at: https://github.com/hasanjawad001/llm-social-media-polarization.
From Observations to Causations: A GNN-based Probabilistic Prediction Framework for Causal Discovery
Jul 27, 2025Causal discovery from observational data is challenging, especially with large datasets and complex relationships. Traditional methods often struggle with scalability and capturing global structural information. To overcome these limitations, we introduce a novel graph neural network (GNN)-based probabilistic framework that learns a probability distribution over the entire space of causal graphs, unlike methods that output a single deterministic graph. Our framework leverages a GNN that encodes both node and edge attributes into a unified graph representation, enabling the model to learn complex causal structures directly from data. The GNN model is trained on a diverse set of synthetic datasets augmented with statistical and information-theoretic measures, such as mutual information and conditional entropy, capturing both local and global data properties. We frame causal discovery as a supervised learning problem, directly predicting the entire graph structure. Our approach demonstrates superior performance, outperforming both traditional and recent non-GNN-based methods, as well as a GNN-based approach, in terms of accuracy and scalability on synthetic and real-world datasets without further training. This probabilistic framework significantly improves causal structure learning, with broad implications for decision-making and scientific discovery across various fields.
CGLearn: Consistent Gradient-Based Learning for Out-of-Distribution Generalization
Nov 09, 2024Improving generalization and achieving highly predictive, robust machine learning models necessitates learning the underlying causal structure of the variables of interest. A prominent and effective method for this is learning invariant predictors across multiple environments. In this work, we introduce a simple yet powerful approach, CGLearn, which relies on the agreement of gradients across various environments. This agreement serves as a powerful indication of reliable features, while disagreement suggests less reliability due to potential differences in underlying causal mechanisms. Our proposed method demonstrates superior performance compared to state-of-the-art methods in both linear and nonlinear settings across various regression and classification tasks. CGLearn shows robust applicability even in the absence of separate environments by exploiting invariance across different subsamples of observational data. Comprehensive experiments on both synthetic and real-world datasets highlight its effectiveness in diverse scenarios. Our findings underscore the importance of leveraging gradient agreement for learning causal invariance, providing a significant step forward in the field of robust machine learning. The source code of the linear and nonlinear implementation of CGLearn is open-source and available at: https://github.com/hasanjawad001/CGLearn.
Two-Stage Stance Labeling: User-Hashtag Heuristics with Graph Neural Networks
Apr 16, 2024The high volume and rapid evolution of content on social media present major challenges for studying the stance of social media users. In this work, we develop a two stage stance labeling method that utilizes the user-hashtag bipartite graph and the user-user interaction graph. In the first stage, a simple and efficient heuristic for stance labeling uses the user-hashtag bipartite graph to iteratively update the stance association of user and hashtag nodes via a label propagation mechanism. This set of soft labels is then integrated with the user-user interaction graph to train a graph neural network (GNN) model using semi-supervised learning. We evaluate this method on two large-scale datasets containing tweets related to climate change from June 2021 to June 2022 and gun control from January 2022 to January 2023. Experiments demonstrate that our user-hashtag heuristic and the semi-supervised GNN method outperform zero-shot stance labeling using LLMs such as GPT4. Further analysis illustrates how the stance labeling information and interaction graph can be used for evaluating the polarization of social media interactions on divisive issues such as climate change and gun control.
Evaluation of Induced Expert Knowledge in Causal Structure Learning by NOTEARS
Jan 04, 2023Causal modeling provides us with powerful counterfactual reasoning and interventional mechanism to generate predictions and reason under various what-if scenarios. However, causal discovery using observation data remains a nontrivial task due to unobserved confounding factors, finite sampling, and changes in the data distribution. These can lead to spurious cause-effect relationships. To mitigate these challenges in practice, researchers augment causal learning with known causal relations. The goal of the paper is to study the impact of expert knowledge on causal relations in the form of additional constraints used in the formulation of the nonparametric NOTEARS. We provide a comprehensive set of comparative analyses of biasing the model using different types of knowledge. We found that (i) knowledge that corrects the mistakes of the NOTEARS model can lead to statistically significant improvements, (ii) constraints on active edges have a larger positive impact on causal discovery than inactive edges, and surprisingly, (iii) the induced knowledge does not correct on average more incorrect active and/or inactive edges than expected. We also demonstrate the behavior of the model and the effectiveness of domain knowledge on a real-world dataset.
Machine Fault Classification using Hamiltonian Neural Networks
Jan 04, 2023A new approach is introduced to classify faults in rotating machinery based on the total energy signature estimated from sensor measurements. The overall goal is to go beyond using black-box models and incorporate additional physical constraints that govern the behavior of mechanical systems. Observational data is used to train Hamiltonian neural networks that describe the conserved energy of the system for normal and various abnormal regimes. The estimated total energy function, in the form of the weights of the Hamiltonian neural network, serves as the new feature vector to discriminate between the faults using off-the-shelf classification models. The experimental results are obtained using the MaFaulDa database, where the proposed model yields a promising area under the curve (AUC) of $0.78$ for the binary classification (normal vs abnormal) and $0.84$ for the multi-class problem (normal, and $5$ different abnormal regimes).
From Causal Pairs to Causal Graphs
Nov 08, 2022



Causal structure learning from observational data remains a non-trivial task due to various factors such as finite sampling, unobserved confounding factors, and measurement errors. Constraint-based and score-based methods tend to suffer from high computational complexity due to the combinatorial nature of estimating the directed acyclic graph (DAG). Motivated by the `Cause-Effect Pair' NIPS 2013 Workshop on Causality Challenge, in this paper, we take a different approach and generate a probability distribution over all possible graphs informed by the cause-effect pair features proposed in response to the workshop challenge. The goal of the paper is to propose new methods based on this probabilistic information and compare their performance with traditional and state-of-the-art approaches. Our experiments, on both synthetic and real datasets, show that our proposed methods not only have statistically similar or better performances than some traditional approaches but also are computationally faster.
Explainable Deep Modeling of Tabular Data using TableGraphNet
Feb 12, 2020



The vast majority of research on explainability focuses on post-explainability rather than explainable modeling. Namely, an explanation model is derived to explain a complex black box model built with the sole purpose of achieving the highest performance possible. In part, this trend might be driven by the misconception that there is a trade-off between explainability and accuracy. Furthermore, the consequential work on Shapely values, grounded in game theory, has also contributed to a new wave of post-explainability research on better approximations for various machine learning models, including deep learning models. We propose a new architecture that inherently produces explainable predictions in the form of additive feature attributions. Our approach learns a graph representation for each record in the dataset. Attribute centric features are then derived from the graph and fed into a contribution deep set model to produce the final predictions. We show that our explainable model attains the same level of performance as black box models. Finally, we provide an augmented model training approach that leverages the missingness property and yields high levels of consistency (as required for the Shapely values) without loss of accuracy.
Approximate Sampling using an Accelerated Metropolis-Hastings based on Bayesian Optimization and Gaussian Processes
Oct 21, 2019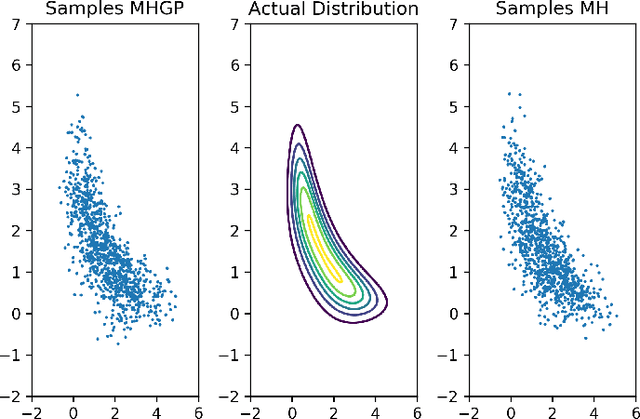
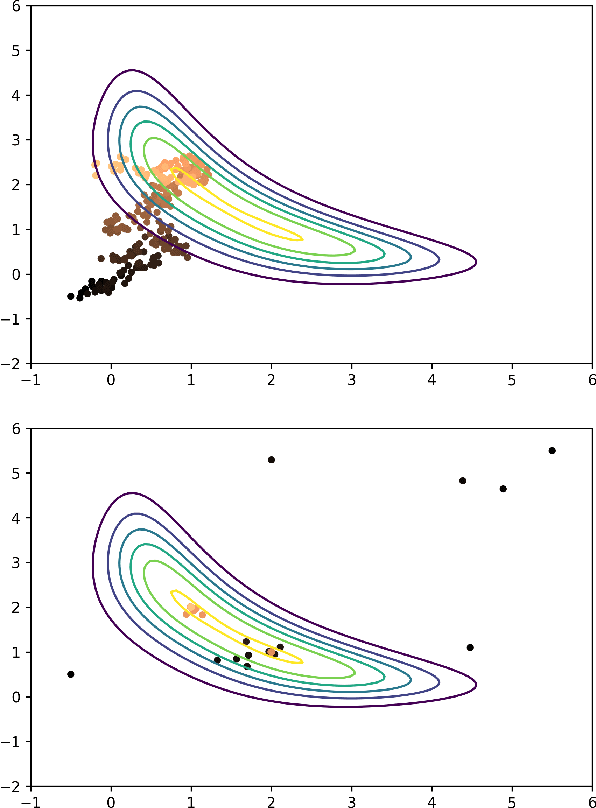
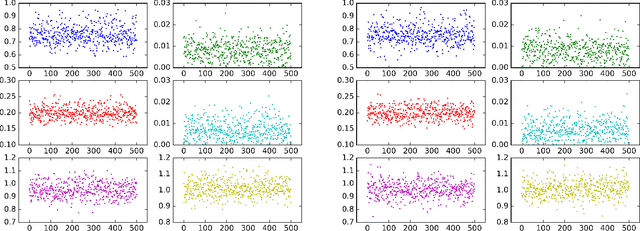
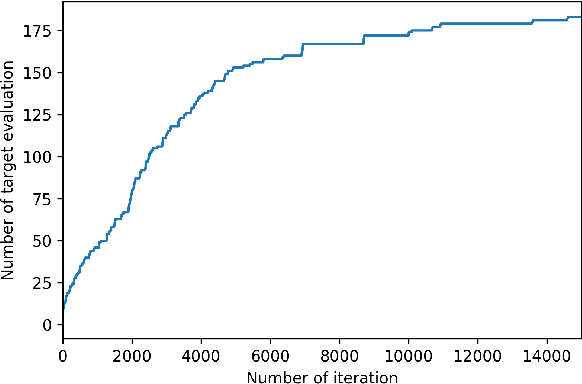
Markov Chain Monte Carlo (MCMC) methods have a drawback when working with a target distribution or likelihood function that is computationally expensive to evaluate, specially when working with big data. This paper focuses on Metropolis-Hastings (MH) algorithm for unimodal distributions. Here, an enhanced MH algorithm is proposed that requires less number of expensive function evaluations, has shorter burn-in period, and uses a better proposal distribution. The main innovations include the use of Bayesian optimization to reach the high probability region quickly, emulating the target distribution using Gaussian processes (GP), and using Laplace approximation of the GP to build a proposal distribution that captures the underlying correlation better. The experiments show significant improvement over the regular MH. Statistical comparison between the results from two algorithms is presented.
A Multiple Filter Based Neural Network Approach to the Extrapolation of Adsorption Energies on Metal Surfaces for Catalysis Applications
Oct 01, 2019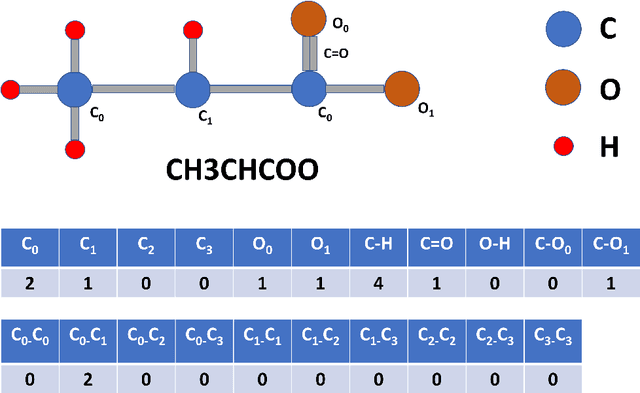
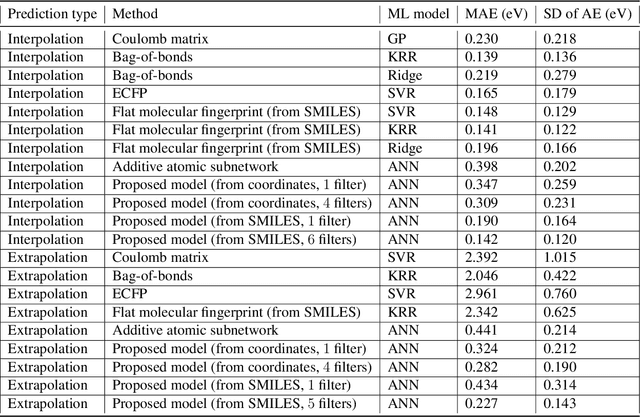
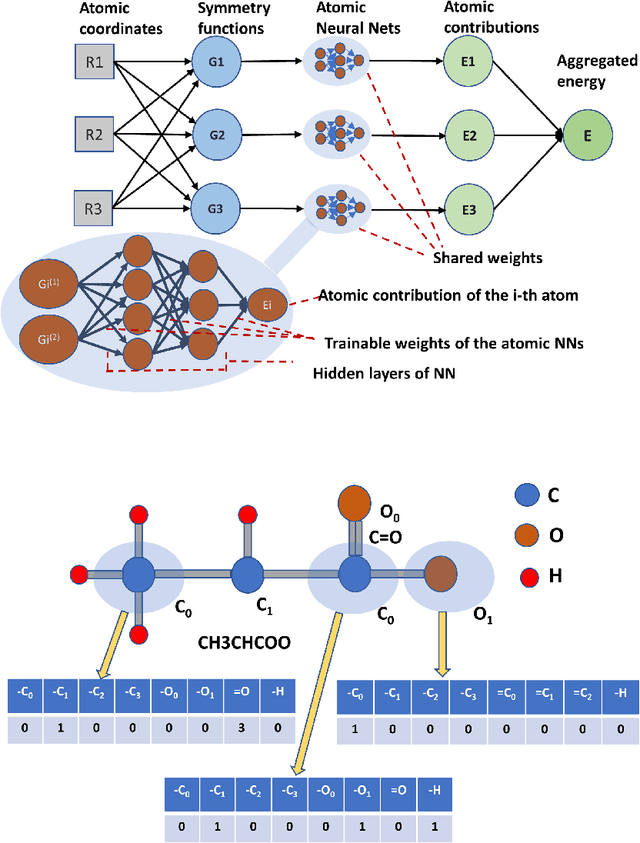
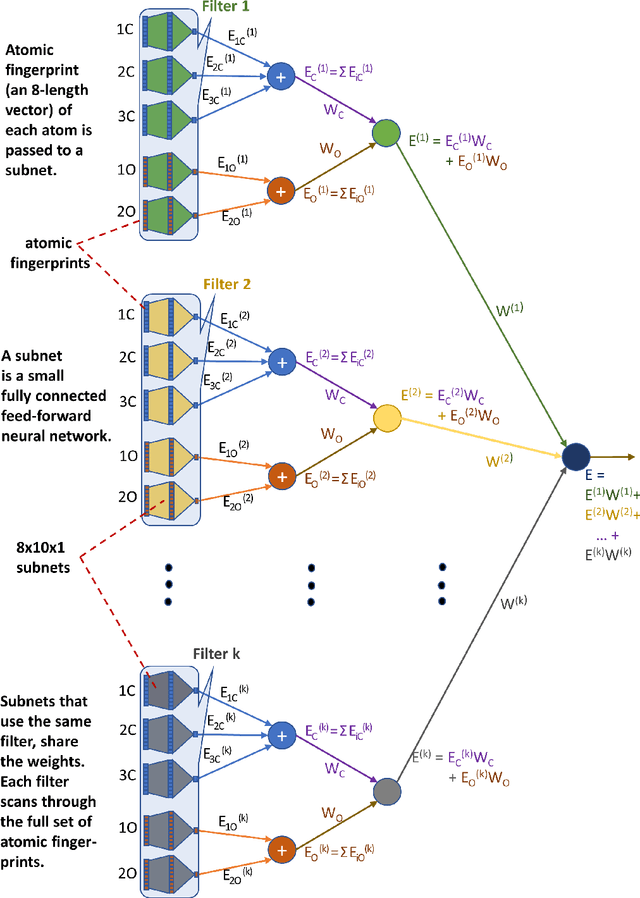
Computational catalyst discovery involves the development of microkinetic reactor models based on estimated parameters determined from density functional theory (DFT). For complex surface chemistries, the cost of calculating the adsorption energies by DFT for a large number of reaction intermediates can become prohibitive. Here, we have identified appropriate descriptors and machine learning models that can be used to predict part of these adsorption energies given data on the rest of them. Our investigations also included the case when the species data used to train the predictive model is of different size relative to the species the model tries to predict - an extrapolation in the data space which is typically difficult with regular machine learning models. We have developed a neural network based predictive model that combines an established model with the concepts of a convolutional neural network that, when extrapolating, achieves significant improvement over the previous models.